 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Multi-Satellite Massive MIMO Transmission: Centralized or Decentralized?
Mar 21, 2026This paper investigates new efficient transmission architectures for multi-satellite massive multiple-input multiple-output (MIMO). We study the weighted sum-rate maximization problem in a multi-satellite system where multiple satellites transmit independent data streams to multi-antenna user terminals, thereby achieving higher throughput. We first adopt a multi-satellite weighted minimum mean square error (WMMSE) formulation under statistical channel state information (CSI), which yields closed-form updates for the precoding and receive vectors. To overcome the high complexity of optimization, we propose a learning-based WMMSE design that integrates tensor equivariance with closed-form recovery, enabling inference with near-optimal performance without iterative updates. Moreover, to reduce inter-satellite signaling overhead incurred by exchanging CSI and precoding vectors in centralized coordination, we develop a decentralized multi-satellite transmission scheme in which each satellite locally infers its precoders rather than receiving from the central satellite. The proposed decentralized scheme leverages periodically available satellite state information, such as orbital positions and satellite attitude, which is inherently accessible in satellite networks, and employs a dual-branch tensor-equivariant network to predict the precoders at each satellite locally. Numerical results demonstrate that the proposed multi-satellite transmission significantly outperforms single-satellite systems in sum rate; the decentralized scheme achieves sum-rate performance close to the centralized schemes while substantially reducing computational complexity and inter-satellite overhead; and the learning-based schemes exhibit strong robustness and scalability across different scenarios.
SpaceTrack-TimeSeries: Time Series Dataset towards Satellite Orbit Analysis
Jun 16, 2025With the rapid advancement of aerospace technology and the large-scale deployment of low Earth orbit (LEO) satellite constellations, the challenges facing astronomical observations and deep space exploration have become increasingly pronounced. As a result, the demand for high-precision orbital data on space objects-along with comprehensive analyses of satellite positioning, constellation configurations, and deep space satellite dynamics-has grown more urgent. However, there remains a notable lack of publicly accessible, real-world datasets to support research in areas such as space object maneuver behavior prediction and collision risk assessment. This study seeks to address this gap by collecting and curating a representative dataset of maneuvering behavior from Starlink satellites. The dataset integrates Two-Line Element (TLE) catalog data with corresponding high-precision ephemeris data, thereby enabling a more realistic and multidimensional modeling of space object behavior. It provides valuable insights into practical deployment of maneuver detection methods and the evaluation of collision risks in increasingly congested orbital environments.
SQuantizer: Simultaneous Learning for Both Sparse and Low-precision Neural Networks
Dec 20, 2018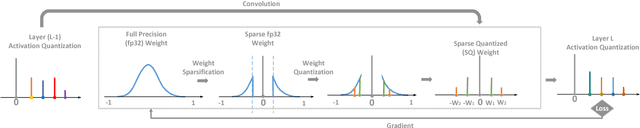

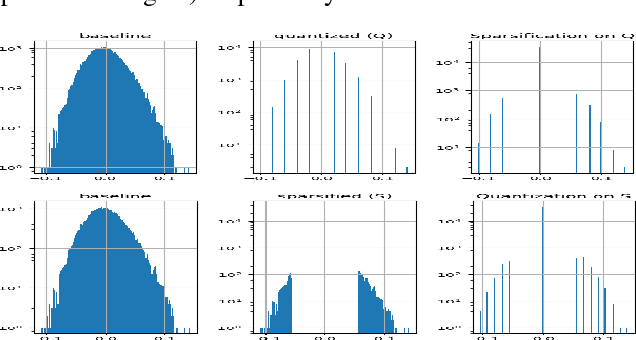
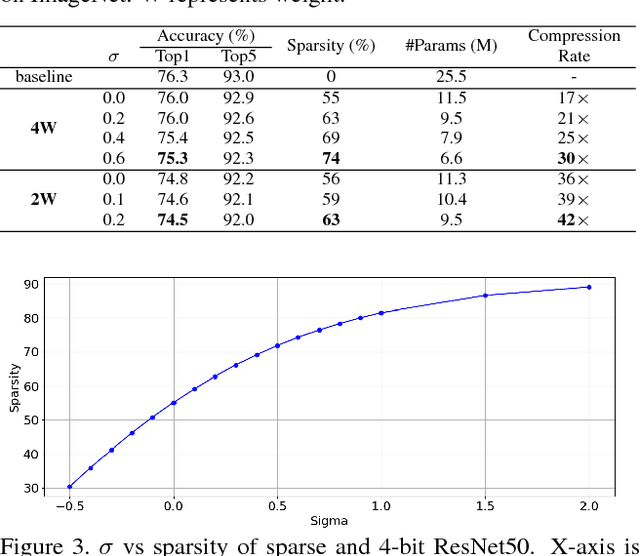
Deep neural networks have achieved state-of-the-art accuracies in a wide range of computer vision, speech recognition, and machine translation tasks. However the limits of memory bandwidth and computational power constrain the range of devices capable of deploying these modern networks. To address this problem, we propose SQuantizer, a new training method that jointly optimizes for both sparse and low-precision neural networks while maintaining high accuracy and providing a high compression rate. This approach brings sparsification and low-bit quantization into a single training pass, employing these techniques in an order demonstrated to be optimal. Our method achieves state-of-the-art accuracies using 4-bit and 2-bit precision for ResNet18, MobileNet-v2 and ResNet50, even with high degree of sparsity. The compression rates of 18x for ResNet18 and 17x for ResNet50, and 9x for MobileNet-v2 are obtained when SQuantizing both weights and activations within 1% and 2% loss in accuracy for ResNets and MobileNet-v2 respectively. An extension of these techniques to object detection also demonstrates high accuracy on YOLO-v2. Additionally, our method allows for fast single pass training, which is important for rapid prototyping and neural architecture search techniques. Finally extensive results from this simultaneous training approach allows us to draw some useful insights into the relative merits of sparsity and quantization.
Hybrid Pruning: Thinner Sparse Networks for Fast Inference on Edge Devices
Nov 01, 2018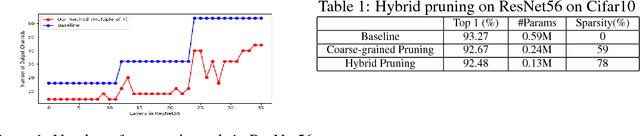
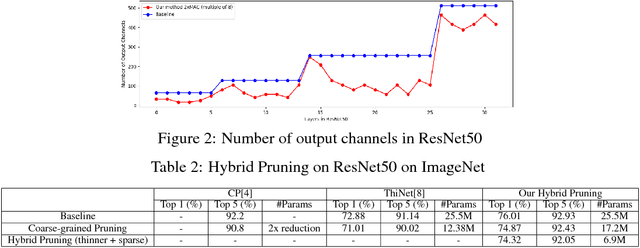
We introduce hybrid pruning which combines both coarse-grained channel and fine-grained weight pruning to reduce model size, computation and power demands with no to little loss in accuracy for enabling modern networks deployment on resource-constrained devices, such as always-on security cameras and drones. Additionally, to effectively perform channel pruning, we propose a fast sensitivity test that helps us quickly identify the sensitivity of within and across layers of a network to the output accuracy for target multiplier accumulators (MACs) or accuracy tolerance. Our experiment shows significantly better results on ResNet50 on ImageNet compared to existing work, even with an additional constraint of channels be hardware-friendly number.