 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-Encoder Meets Multi-Encoders: Representation Before Fusion for Brain Tumor Segmentation with Missing Modalities
Apr 24, 2026Multimodal MRI offers complementary information for brain tumor segmentation, but clinical scans often lack one or more modalities, which degrades segmentation performance. In this paper, we propose UniME (Uni-Encoder Meets Multi-Encoders), a two-stage heterogeneous method for brain tumor segmentation with missing modalities that reconciles the trade-offs among fine-grained structure capture, cross-modal complementarity modeling, and exploitation of available modalities. The idea is to decouple representation learning from segmentation via a two-stage heterogeneous architecture. Stage 1 pretrains a single ViT Uni-Encoder with masked image modeling to establish a unified representation robust to missing modalities. Stage 2 adds modality-specific CNN Multi-Encoders to extract high-resolution, multi-scale, fine-grained features. We fuse these features with the global representation to produce precise segmentations. Experiments on BraTS 2023 and BraTS 2024 show that UniME outperforms previous methods under incomplete multi-modal scenarios. The code is available at https://github.com/Hooorace-S/UniME
Deep Learning-Based Multi-Satellite Massive MIMO Transmission: Centralized or Decentralized?
Mar 21, 2026This paper investigates new efficient transmission architectures for multi-satellite massive multiple-input multiple-output (MIMO). We study the weighted sum-rate maximization problem in a multi-satellite system where multiple satellites transmit independent data streams to multi-antenna user terminals, thereby achieving higher throughput. We first adopt a multi-satellite weighted minimum mean square error (WMMSE) formulation under statistical channel state information (CSI), which yields closed-form updates for the precoding and receive vectors. To overcome the high complexity of optimization, we propose a learning-based WMMSE design that integrates tensor equivariance with closed-form recovery, enabling inference with near-optimal performance without iterative updates. Moreover, to reduce inter-satellite signaling overhead incurred by exchanging CSI and precoding vectors in centralized coordination, we develop a decentralized multi-satellite transmission scheme in which each satellite locally infers its precoders rather than receiving from the central satellite. The proposed decentralized scheme leverages periodically available satellite state information, such as orbital positions and satellite attitude, which is inherently accessible in satellite networks, and employs a dual-branch tensor-equivariant network to predict the precoders at each satellite locally. Numerical results demonstrate that the proposed multi-satellite transmission significantly outperforms single-satellite systems in sum rate; the decentralized scheme achieves sum-rate performance close to the centralized schemes while substantially reducing computational complexity and inter-satellite overhead; and the learning-based schemes exhibit strong robustness and scalability across different scenarios.
Unlocking Symbol-Level Precoding Efficiency Through Tensor Equivariant Neural Network
Oct 02, 2025Although symbol-level precoding (SLP) based on constructive interference (CI) exploitation offers performance gains, its high complexity remains a bottleneck. This paper addresses this challenge with an end-to-end deep learning (DL) framework with low inference complexity that leverages the structure of the optimal SLP solution in the closed-form and its inherent tensor equivariance (TE), where TE denotes that a permutation of the input induces the corresponding permutation of the output. Building upon the computationally efficient model-based formulations, as well as their known closed-form solutions, we analyze their relationship with linear precoding (LP) and investigate the corresponding optimality condition. We then construct a mapping from the problem formulation to the solution and prove its TE, based on which the designed networks reveal a specific parameter-sharing pattern that delivers low computational complexity and strong generalization. Leveraging these, we propose the backbone of the framework with an attention-based TE module, achieving linear computational complexity. Furthermore, we demonstrate that such a framework is also applicable to imperfect CSI scenarios, where we design a TE-based network to map the CSI, statistics, and symbols to auxiliary variables. Simulation results show that the proposed framework captures substantial performance gains of optimal SLP, while achieving an approximately 80-times speedup over conventional methods and maintaining strong generalization across user numbers and symbol block lengths.
DAVOS: Semi-Supervised Video Object Segmentation via Adversarial Domain Adaptation
May 24, 2021

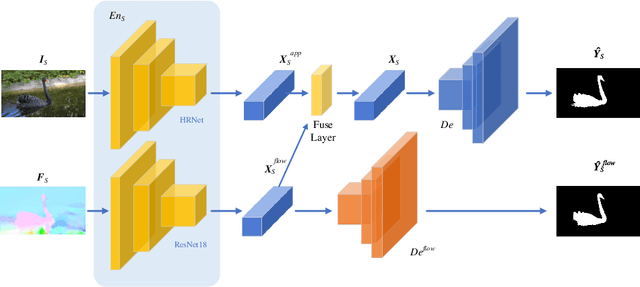
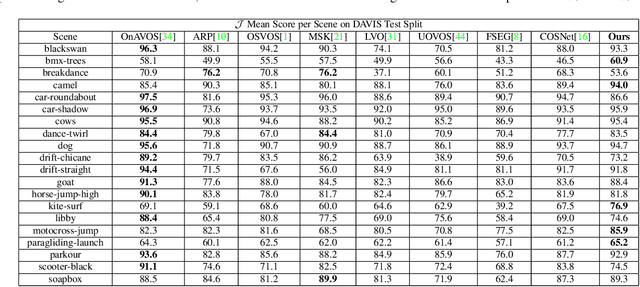
Domain shift has always been one of the primary issues in video object segmentation (VOS), for which models suffer from degeneration when tested on unfamiliar datasets. Recently, many online methods have emerged to narrow the performance gap between training data (source domain) and test data (target domain) by fine-tuning on annotations of test data which are usually in shortage. In this paper, we propose a novel method to tackle domain shift by first introducing adversarial domain adaptation to the VOS task, with supervised training on the source domain and unsupervised training on the target domain. By fusing appearance and motion features with a convolution layer, and by adding supervision onto the motion branch, our model achieves state-of-the-art performance on DAVIS2016 with 82.6% mean IoU score after supervised training. Meanwhile, our adversarial domain adaptation strategy significantly raises the performance of the trained model when applied on FBMS59 and Youtube-Object, without exploiting extra annotations.