 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacroscopic Emission Modeling of Urban Traffic Using Probe Vehicle Data: A Machine Learning Approach
Nov 11, 2025



Urban congestions cause inefficient movement of vehicles and exacerbate greenhouse gas emissions and urban air pollution. Macroscopic emission fundamental diagram (eMFD)captures an orderly relationship among emission and aggregated traffic variables at the network level, allowing for real-time monitoring of region-wide emissions and optimal allocation of travel demand to existing networks, reducing urban congestion and associated emissions. However, empirically derived eMFD models are sparse due to historical data limitation. Leveraging a large-scale and granular traffic and emission data derived from probe vehicles, this study is the first to apply machine learning methods to predict the network wide emission rate to traffic relationship in U.S. urban areas at a large scale. The analysis framework and insights developed in this work generate data-driven eMFDs and a deeper understanding of their location dependence on network, infrastructure, land use, and vehicle characteristics, enabling transportation authorities to measure carbon emissions from urban transport of given travel demand and optimize location specific traffic management and planning decisions to mitigate network-wide emissions.
Learning-based Models for Vulnerability Detection: An Extensive Study
Aug 14, 2024Though many deep learning-based models have made great progress in vulnerability detection, we have no good understanding of these models, which limits the further advancement of model capability, understanding of the mechanism of model detection, and efficiency and safety of practical application of models. In this paper, we extensively and comprehensively investigate two types of state-of-the-art learning-based approaches (sequence-based and graph-based) by conducting experiments on a recently built large-scale dataset. We investigate seven research questions from five dimensions, namely model capabilities, model interpretation, model stability, ease of use of model, and model economy. We experimentally demonstrate the priority of sequence-based models and the limited abilities of both LLM (ChatGPT) and graph-based models. We explore the types of vulnerability that learning-based models skilled in and reveal the instability of the models though the input is subtlely semantical-equivalently changed. We empirically explain what the models have learned. We summarize the pre-processing as well as requirements for easily using the models. Finally, we initially induce the vital information for economically and safely practical usage of these models.
DISK: Domain-constrained Instance Sketch for Math Word Problem Generation
Apr 10, 2022
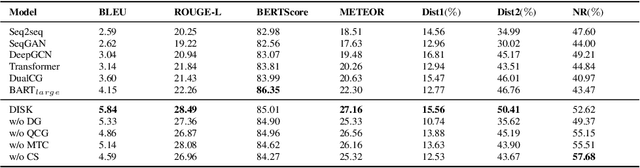

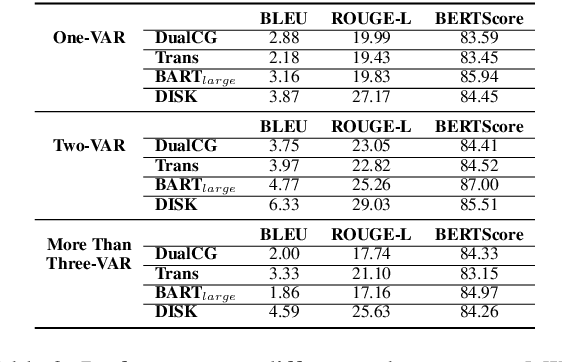
A math word problem (MWP) is a coherent narrative which reflects the underlying logic of math equations. Successful MWP generation can automate the writing of mathematics questions. Previous methods mainly generate MWP text based on inflexible pre-defined templates. In this paper, we propose a neural model for generating MWP text from math equations. Firstly, we incorporate a matching model conditioned on the domain knowledge to retrieve a MWP instance which is most consistent with the ground-truth, where the domain is a latent variable extracted with a domain summarizer. Secondly, by constructing a Quantity Cell Graph (QCG) from the retrieved MWP instance and reasoning over it, we improve the model's comprehension of real-world scenarios and derive a domain-constrained instance sketch to guide the generation. Besides, the QCG also interacts with the equation encoder to enhance the alignment between math tokens (e.g., quantities and variables) and MWP text. Experiments and empirical analysis on educational MWP set show that our model achieves impressive performance in both automatic evaluation metrics and human evaluation metrics.