 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCCT-Net: Two-Stream Network Architecture for Fast and Efficient Engagement Estimation via Behavioral Feature Signals
Apr 15, 2024Engagement analysis finds various applications in healthcare, education, advertisement, services. Deep Neural Networks, used for analysis, possess complex architecture and need large amounts of input data, computational power, inference time. These constraints challenge embedding systems into devices for real-time use. To address these limitations, we present a novel two-stream feature fusion "Tensor-Convolution and Convolution-Transformer Network" (TCCT-Net) architecture. To better learn the meaningful patterns in the temporal-spatial domain, we design a "CT" stream that integrates a hybrid convolutional-transformer. In parallel, to efficiently extract rich patterns from the temporal-frequency domain and boost processing speed, we introduce a "TC" stream that uses Continuous Wavelet Transform (CWT) to represent information in a 2D tensor form. Evaluated on the EngageNet dataset, the proposed method outperforms existing baselines, utilizing only two behavioral features (head pose rotations) compared to the 98 used in baseline models. Furthermore, comparative analysis shows TCCT-Net's architecture offers an order-of-magnitude improvement in inference speed compared to state-of-the-art image-based Recurrent Neural Network (RNN) methods. The code will be released at https://github.com/vedernikovphoto/TCCT_Net.
Analyzing Participants' Engagement during Online Meetings Using Unsupervised Remote Photoplethysmography with Behavioral Features
Apr 05, 2024



Engagement measurement finds application in healthcare, education, advertisement, and services. The use of physiological and behavioral features is viable, but the impracticality of traditional physiological measurement arises due to the need for contact sensors. We demonstrate the feasibility of unsupervised remote photoplethysmography (rPPG) as an alternative for contact sensors in deriving heart rate variability (HRV) features, then fusing these with behavioral features to measure engagement in online group meetings. Firstly, a unique Engagement Dataset of online interactions among social workers is collected with granular engagement labels, offering insight into virtual meeting dynamics. Secondly, a pre-trained rPPG model is customized to reconstruct accurate rPPG signals from video meetings in an unsupervised manner, enabling the calculation of HRV features. Thirdly, the feasibility of estimating engagement from HRV features using short observation windows, with a notable enhancement when using longer observation windows of two to four minutes, is demonstrated. Fourthly, the effectiveness of behavioral cues is evaluated and fused with physiological data, which further enhances engagement estimation performance. An accuracy of 94% is achieved when only HRV features are used, eliminating the need for contact sensors or ground truth signals. The incorporation of behavioral cues raises the accuracy to 96%. Facial video analysis offers precise engagement measurement, beneficial for future applications.
Measuring Non-Typical Emotions for Mental Health: A Survey of Computational Approaches
Mar 09, 2024



Analysis of non-typical emotions, such as stress, depression and engagement is less common and more complex compared to that of frequently discussed emotions like happiness, sadness, fear, and anger. The importance of these non-typical emotions has been increasingly recognized due to their implications on mental health and well-being. Stress and depression impact the engagement in daily tasks, highlighting the need to understand their interplay. This survey is the first to simultaneously explore computational methods for analyzing stress, depression, and engagement. We discuss the most commonly used datasets, input modalities, data processing techniques, and information fusion methods used for the computational analysis of stress, depression and engagement. A timeline and taxonomy of non-typical emotion analysis approaches along with their generic pipeline and categories are presented. Subsequently, we describe state-of-the-art computational approaches for non-typical emotion analysis, including a performance summary on the most commonly used datasets. Following this, we explore the applications, along with the associated challenges, limitations, and future research directions.
Synthesizing Sentiment-Controlled Feedback For Multimodal Text and Image Data
Feb 12, 2024The ability to generate sentiment-controlled feedback in response to multimodal inputs, comprising both text and images, addresses a critical gap in human-computer interaction by enabling systems to provide empathetic, accurate, and engaging responses. This capability has profound applications in healthcare, marketing, and education. To this end, we construct a large-scale Controllable Multimodal Feedback Synthesis (CMFeed) dataset and propose a controllable feedback synthesis system. The proposed system includes an encoder, decoder, and controllability block for textual and visual inputs. It extracts textual and visual features using a transformer and Faster R-CNN networks and combines them to generate feedback. The CMFeed dataset encompasses images, text, reactions to the post, human comments with relevance scores, and reactions to the comments. The reactions to the post and comments are utilized to train the proposed model to produce feedback with a particular (positive or negative) sentiment. A sentiment classification accuracy of 77.23% has been achieved, 18.82% higher than the accuracy without using the controllability. Moreover, the system incorporates a similarity module for assessing feedback relevance through rank-based metrics. It implements an interpretability technique to analyze the contribution of textual and visual features during the generation of uncontrolled and controlled feedback.
Contrast-Phys+: Unsupervised and Weakly-supervised Video-based Remote Physiological Measurement via Spatiotemporal Contrast
Sep 13, 2023



Video-based remote physiological measurement utilizes facial videos to measure the blood volume change signal, which is also called remote photoplethysmography (rPPG). Supervised methods for rPPG measurements have been shown to achieve good performance. However, the drawback of these methods is that they require facial videos with ground truth (GT) physiological signals, which are often costly and difficult to obtain. In this paper, we propose Contrast-Phys+, a method that can be trained in both unsupervised and weakly-supervised settings. We employ a 3DCNN model to generate multiple spatiotemporal rPPG signals and incorporate prior knowledge of rPPG into a contrastive loss function. We further incorporate the GT signals into contrastive learning to adapt to partial or misaligned labels. The contrastive loss encourages rPPG/GT signals from the same video to be grouped together, while pushing those from different videos apart. We evaluate our methods on five publicly available datasets that include both RGB and Near-infrared videos. Contrast-Phys+ outperforms the state-of-the-art supervised methods, even when using partially available or misaligned GT signals, or no labels at all. Additionally, we highlight the advantages of our methods in terms of computational efficiency, noise robustness, and generalization.
Interpretable Multimodal Emotion Recognition using Facial Features and Physiological Signals
Jun 05, 2023


This paper aims to demonstrate the importance and feasibility of fusing multimodal information for emotion recognition. It introduces a multimodal framework for emotion understanding by fusing the information from visual facial features and rPPG signals extracted from the input videos. An interpretability technique based on permutation feature importance analysis has also been implemented to compute the contributions of rPPG and visual modalities toward classifying a given input video into a particular emotion class. The experiments on IEMOCAP dataset demonstrate that the emotion classification performance improves by combining the complementary information from multiple modalities.
Contrast-Phys: Unsupervised Video-based Remote Physiological Measurement via Spatiotemporal Contrast
Aug 08, 2022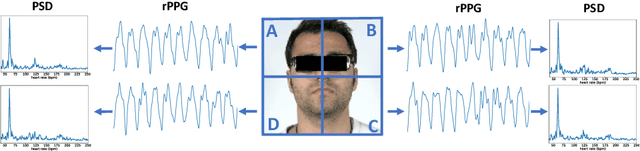
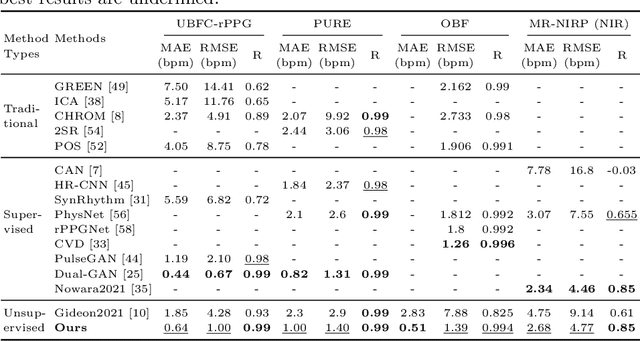

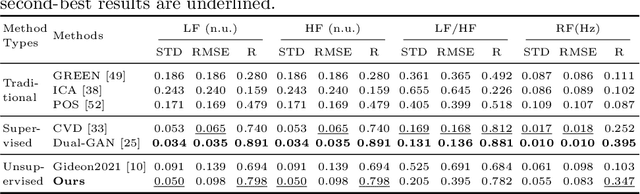
Video-based remote physiological measurement utilizes face videos to measure the blood volume change signal, which is also called remote photoplethysmography (rPPG). Supervised methods for rPPG measurements achieve state-of-the-art performance. However, supervised rPPG methods require face videos and ground truth physiological signals for model training. In this paper, we propose an unsupervised rPPG measurement method that does not require ground truth signals for training. We use a 3DCNN model to generate multiple rPPG signals from each video in different spatiotemporal locations and train the model with a contrastive loss where rPPG signals from the same video are pulled together while those from different videos are pushed away. We test on five public datasets, including RGB videos and NIR videos. The results show that our method outperforms the previous unsupervised baseline and achieves accuracies very close to the current best supervised rPPG methods on all five datasets. Furthermore, we also demonstrate that our approach can run at a much faster speed and is more robust to noises than the previous unsupervised baseline. Our code is available at https://github.com/zhaodongsun/contrast-phys.
Review of Face Presentation Attack Detection Competitions
Dec 21, 2021

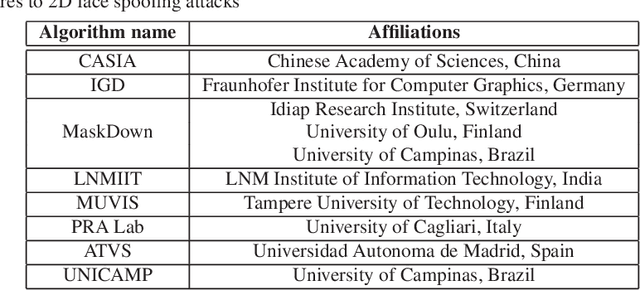

Face presentation attack detection (PAD) has received increasing attention ever since the vulnerabilities to spoofing have been widely recognized. The state of the art in unimodal and multi-modal face anti-spoofing has been assessed in eight international competitions organized in conjunction with major biometrics and computer vision conferences in 2011, 2013, 2017, 2019, 2020 and 2021, each introducing new challenges to the research community. In this chapter, we present the design and results of the five latest competitions from 2019 until 2021. The first two challenges aimed to evaluate the effectiveness of face PAD in multi-modal setup introducing near-infrared (NIR) and depth modalities in addition to colour camera data, while the latest three competitions focused on evaluating domain and attack type generalization abilities of face PAD algorithms operating on conventional colour images and videos. We also discuss the lessons learnt from the competitions and future challenges in the field in general.
Non-contact Atrial Fibrillation Detection from Face Videos by Learning Systolic Peaks
Oct 14, 2021
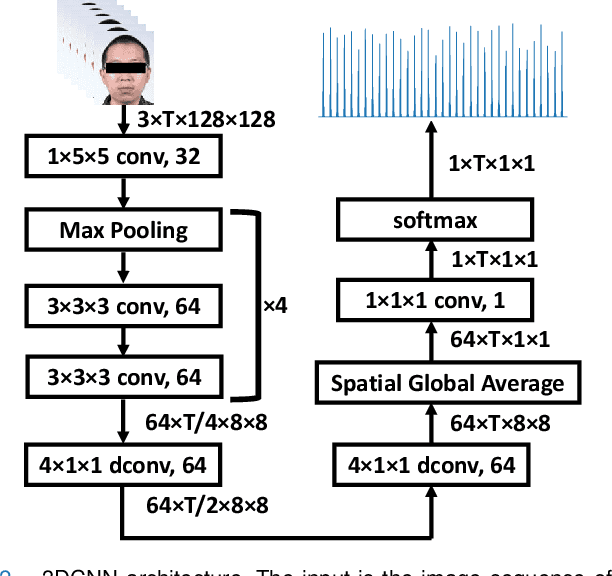


Objective: We propose a non-contact approach for atrial fibrillation (AF) detection from face videos. Methods: Face videos, electrocardiography (ECG), and contact photoplethysmography (PPG) from 100 healthy subjects and 100 AF patients are recorded. All the videos in the healthy group are labeled as healthy. Videos in the patient group are labeled as AF, sinus rhythm (SR), or atrial flutter (AFL) by cardiologists. We use the 3D convolutional neural network for remote PPG measurement and propose a novel loss function (Wasserstein distance) to use the timing of systolic peaks from contact PPG as the label for our model training. Then a set of heart rate variability (HRV) features are calculated from the inter-beat intervals, and a support vector machine (SVM) classifier is trained with HRV features. Results: Our proposed method can accurately extract systolic peaks from face videos for AF detection. The proposed method is trained with subject-independent 10-fold cross-validation with 30s video clips and tested on two tasks. 1) Classification of healthy versus AF: the accuracy, sensitivity, and specificity are 96.16%, 95.71%, and 96.23%. 2) Classification of SR versus AF: the accuracy, sensitivity, and specificity are 95.31%, 98.66%, and 91.11%. Conclusion: We achieve good performance of non-contact AF detection by learning systolic peaks. Significance: non-contact AF detection can be used for self-screening of AF symptom for suspectable populations at home, or self-monitoring of AF recurrence after treatment for the chronical patients.
iMiGUE: An Identity-free Video Dataset for Micro-Gesture Understanding and Emotion Analysis
Jul 01, 2021
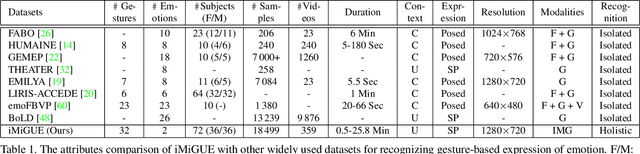
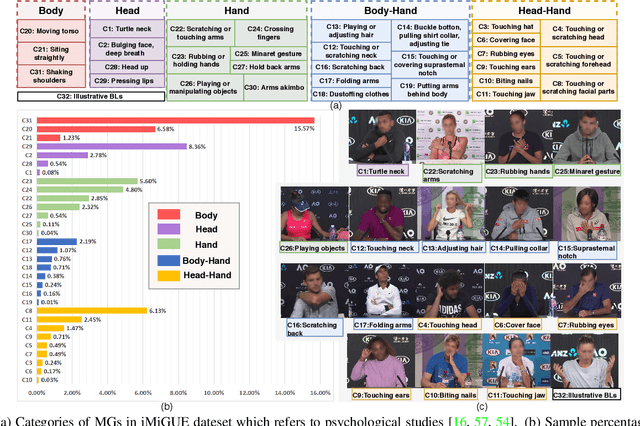
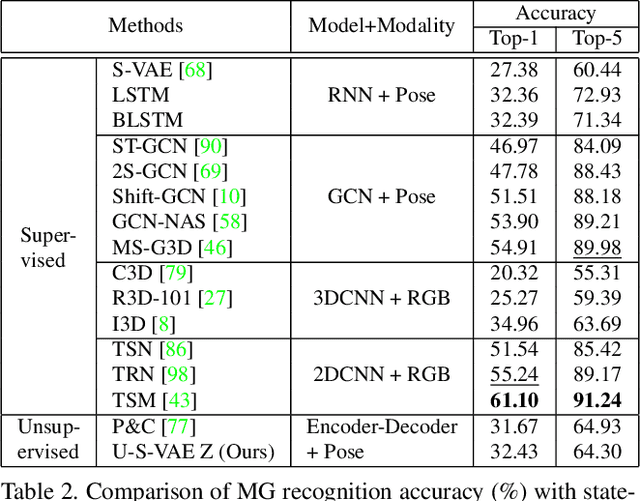
We introduce a new dataset for the emotional artificial intelligence research: identity-free video dataset for Micro-Gesture Understanding and Emotion analysis (iMiGUE). Different from existing public datasets, iMiGUE focuses on nonverbal body gestures without using any identity information, while the predominant researches of emotion analysis concern sensitive biometric data, like face and speech. Most importantly, iMiGUE focuses on micro-gestures, i.e., unintentional behaviors driven by inner feelings, which are different from ordinary scope of gestures from other gesture datasets which are mostly intentionally performed for illustrative purposes. Furthermore, iMiGUE is designed to evaluate the ability of models to analyze the emotional states by integrating information of recognized micro-gesture, rather than just recognizing prototypes in the sequences separately (or isolatedly). This is because the real need for emotion AI is to understand the emotional states behind gestures in a holistic way. Moreover, to counter for the challenge of imbalanced sample distribution of this dataset, an unsupervised learning method is proposed to capture latent representations from the micro-gesture sequences themselves. We systematically investigate representative methods on this dataset, and comprehensive experimental results reveal several interesting insights from the iMiGUE, e.g., micro-gesture-based analysis can promote emotion understanding. We confirm that the new iMiGUE dataset could advance studies of micro-gesture and emotion AI.