 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Accelerated Correlation Filter Tracker
Dec 05, 2019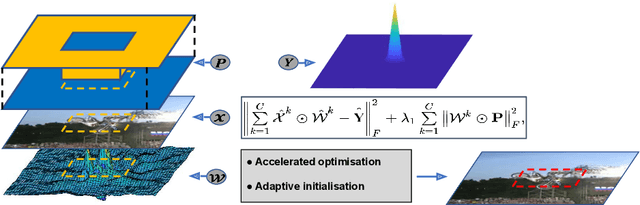
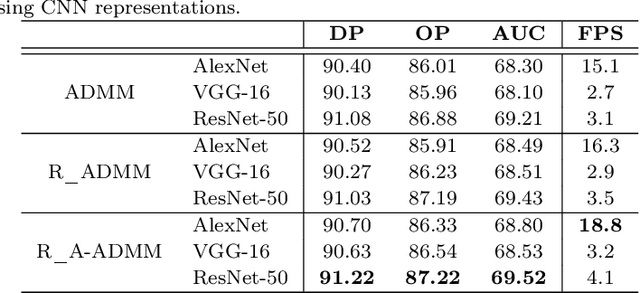
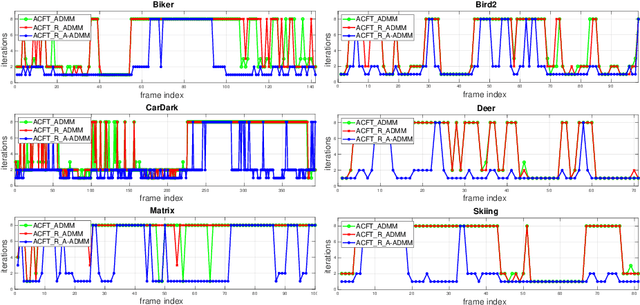
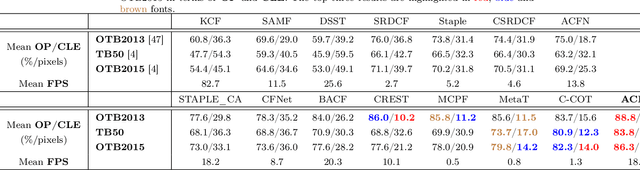
Recent visual object tracking methods have witnessed a continuous improvement in the state-of-the-art with the development of efficient discriminative correlation filters (DCF) and robust deep neural network features. Despite the outstanding performance achieved by the above combination, existing advanced trackers suffer from the burden of high computational complexity of the deep feature extraction and online model learning. We propose an accelerated ADMM optimisation method obtained by adding a momentum to the optimisation sequence iterates, and by relaxing the impact of the error between DCF parameters and their norm. The proposed optimisation method is applied to an innovative formulation of the DCF design, which seeks the most discriminative spatially regularised feature channels. A further speed up is achieved by an adaptive initialisation of the filter optimisation process. The significantly increased convergence of the DCF filter is demonstrated by establishing the optimisation process equivalence with a continuous dynamical system for which the convergence properties can readily be derived. The experimental results obtained on several well-known benchmarking datasets demonstrate the efficiency and robustness of the proposed ACFT method, with a tracking accuracy comparable to the start-of-the-art trackers.
Learning a Representation with the Block-Diagonal Structure for Pattern Classification
Nov 23, 2019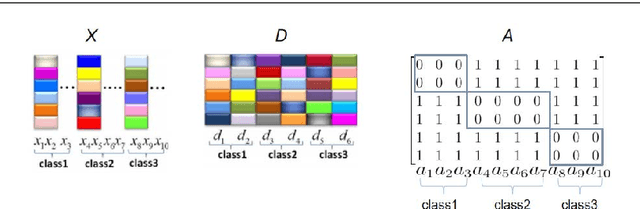
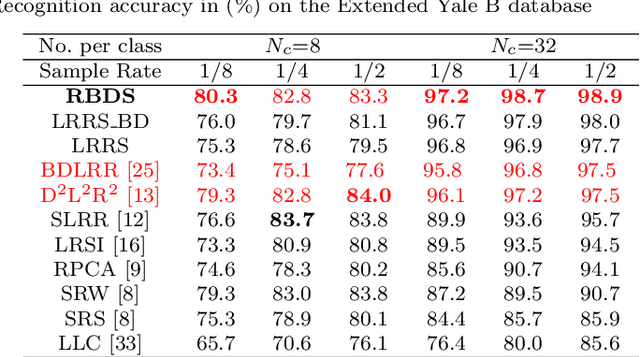

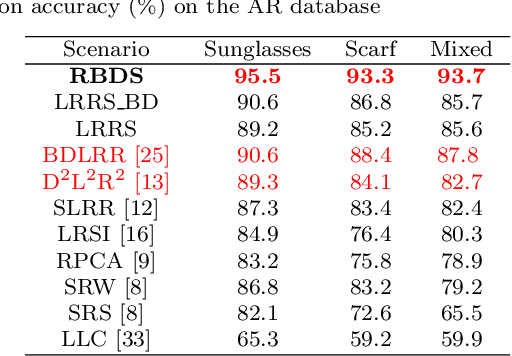
Sparse-representation-based classification (SRC) has been widely studied and developed for various practical signal classification applications. However, the performance of a SRC-based method is degraded when both the training and test data are corrupted. To counteract this problem, we propose an approach that learns Representation with Block-Diagonal Structure (RBDS) for robust image recognition. To be more specific, we first introduce a regularization term that captures the block-diagonal structure of the target representation matrix of the training data. The resulting problem is then solved by an optimizer. Last, based on the learned representation, a simple yet effective linear classifier is used for the classification task. The experimental results obtained on several benchmarking datasets demonstrate the efficacy of the proposed RBDS method.
Locality Constraint Dictionary Learning with Support Vector for Pattern Classification
Nov 22, 2019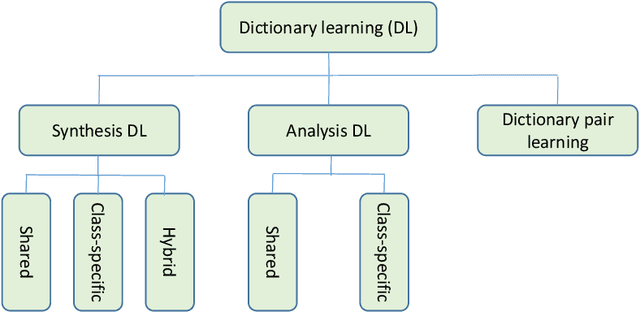
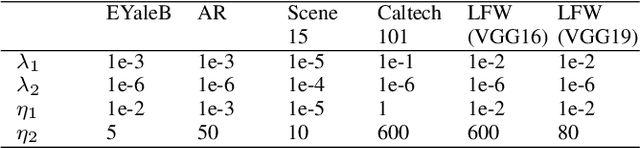
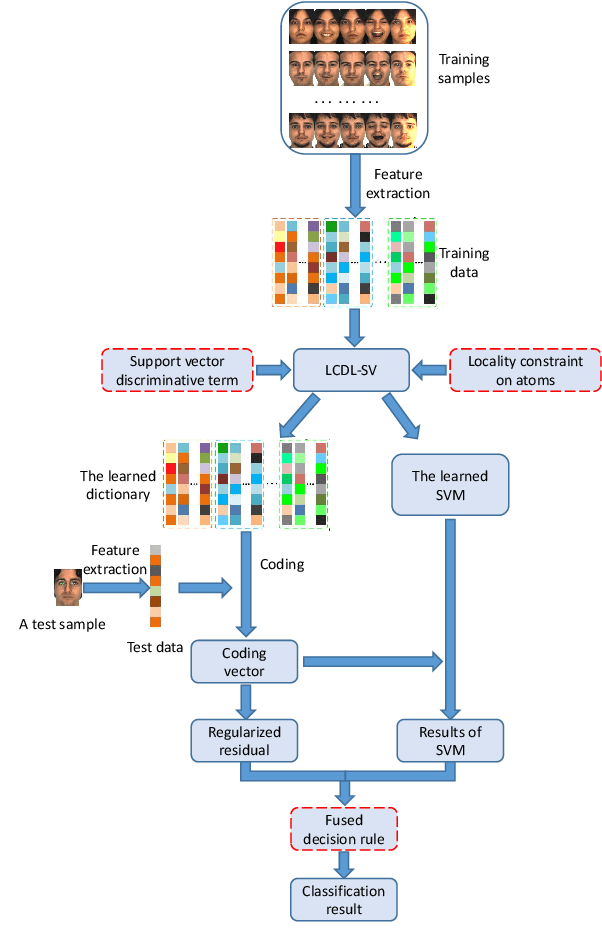
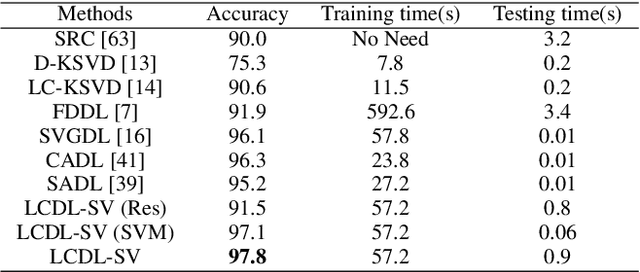
Discriminative dictionary learning (DDL) has recently gained significant attention due to its impressive performance in various pattern classification tasks. However, the locality of atoms is not fully explored in conventional DDL approaches which hampers their classification performance. In this paper, we propose a locality constraint dictionary learning with support vector discriminative term (LCDL-SV), in which the locality information is preserved by employing the graph Laplacian matrix of the learned dictionary. To jointly learn a classifier during the training phase, a support vector discriminative term is incorporated into the proposed objective function. Moreover, in the classification stage, the identity of test data is jointly determined by the regularized residual and the learned multi-class support vector machine. Finally, the resulting optimization problem is solved by utilizing the alternative strategy. Experimental results on benchmark databases demonstrate the superiority of our proposed method over previous dictionary learning approaches on both hand-crafted and deep features. The source code of our proposed LCDL-SV is accessible at https://github.com/yinhefeng/LCDL-SV
Class-specific residual constraint non-negative representation for pattern classification
Nov 22, 2019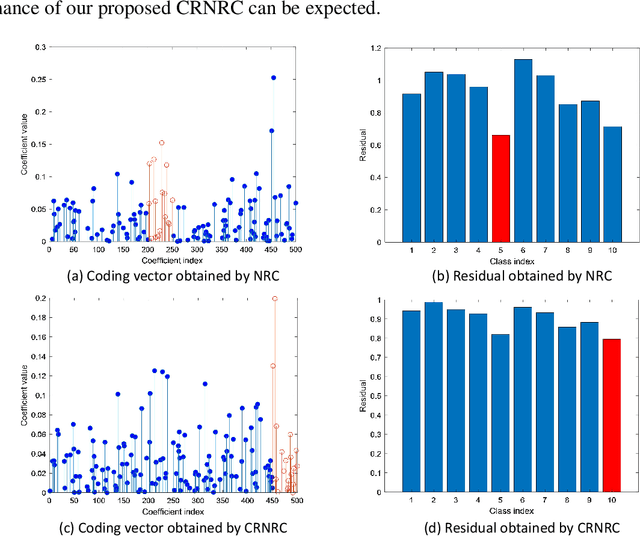


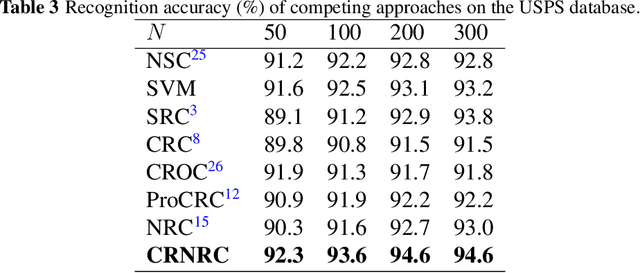
Representation based classification method (RBCM) remains one of the hottest topics in the community of pattern recognition, and the recently proposed non-negative representation based classification (NRC) achieved impressive recognition results in pattern classification. However, there is no regularization term other than the reconstruction error term in the formulation of NRC, which may result in unstable solution leading to misclassification. To overcome this drawback of NRC, in this paper, we propose a class-specific residual constraint non-negative representation (CRNR) for pattern classification. CRNR introduces a class-specific residual constraint into the formulation of NRC, which encourages more homogeneous training samples to participate in the representation of the test sample. Based on the proposed CRNR, we develop a CRNR based classifier (CRNRC) for pattern classification. Experimental results on several benchmark datasets demonstrate the superiority of CRNRC over conventional RBCM as well as the recently proposed NRC. Moreover, CRNRC works better or comparable to some state-of-the-art deep approaches on diverse challenging pattern classification tasks. The source code of our proposed CRNRC is accessible at https://github.com/yinhefeng/CRNRC
More About Covariance Descriptors for Image Set Coding: Log-Euclidean Framework based Kernel Matrix Representation
Sep 26, 2019
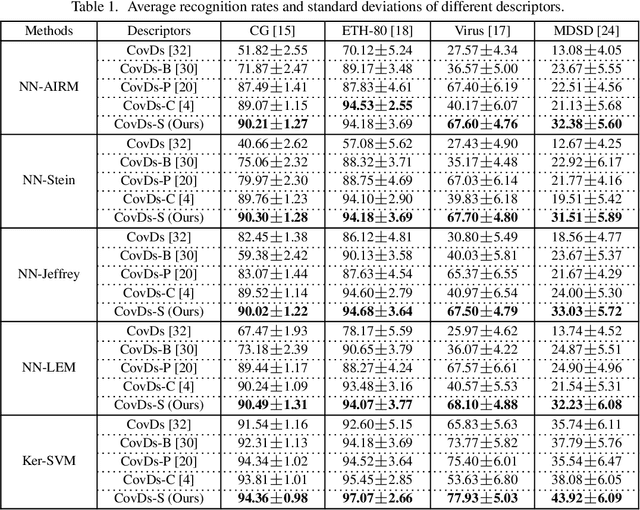
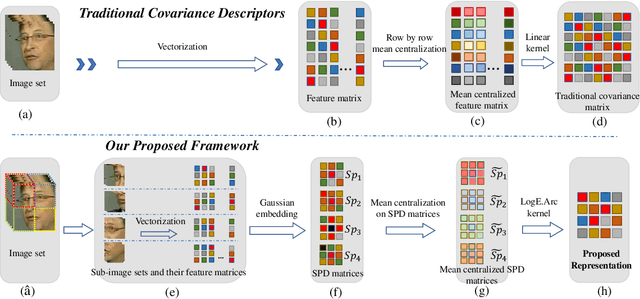
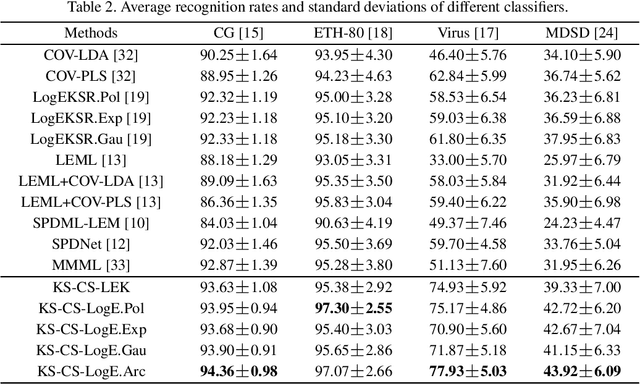
We consider a family of structural descriptors for visual data, namely covariance descriptors (CovDs) that lie on a non-linear symmetric positive definite (SPD) manifold, a special type of Riemannian manifolds. We propose an improved version of CovDs for image set coding by extending the traditional CovDs from Euclidean space to the SPD manifold. Specifically, the manifold of SPD matrices is a complete inner product space with the operations of logarithmic multiplication and scalar logarithmic multiplication defined in the Log-Euclidean framework. In this framework, we characterise covariance structure in terms of the arc-cosine kernel which satisfies Mercer's condition and propose the operation of mean centralization on SPD matrices. Furthermore, we combine arc-cosine kernels of different orders using mixing parameters learnt by kernel alignment in a supervised manner. Our proposed framework provides a lower-dimensional and more discriminative data representation for the task of image set classification. The experimental results demonstrate its superior performance, measured in terms of recognition accuracy, as compared with the state-of-the-art methods.
Dual Encoder-Decoder based Generative Adversarial Networks for Disentangled Facial Representation Learning
Sep 19, 2019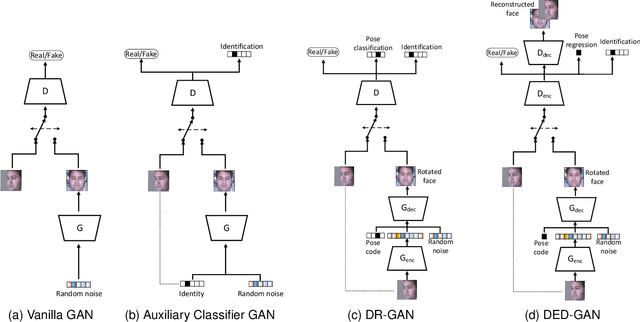
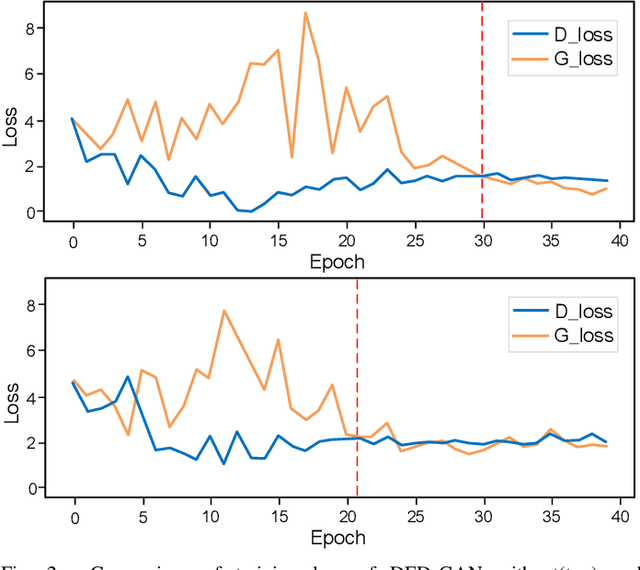
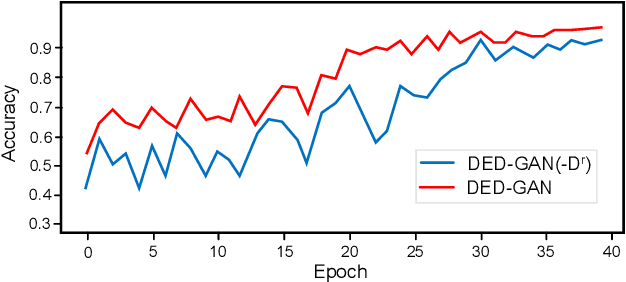
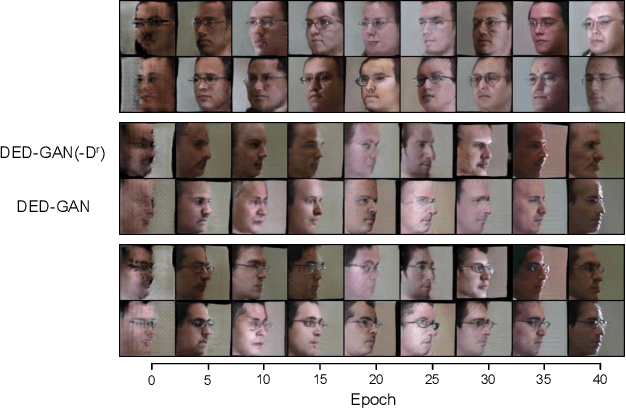
To learn disentangled representations of facial images, we present a Dual Encoder-Decoder based Generative Adversarial Network (DED-GAN). In the proposed method, both the generator and discriminator are designed with deep encoder-decoder architectures as their backbones. To be more specific, the encoder-decoder structured generator is used to learn a pose disentangled face representation, and the encoder-decoder structured discriminator is tasked to perform real/fake classification, face reconstruction, determining identity and estimating face pose. We further improve the proposed network architecture by minimising the additional pixel-wise loss defined by the Wasserstein distance at the output of the discriminator so that the adversarial framework can be better trained. Additionally, we consider face pose variation to be continuous, rather than discrete in existing literature, to inject richer pose information into our model. The pose estimation task is formulated as a regression problem, which helps to disentangle identity information from pose variations. The proposed network is evaluated on the tasks of pose-invariant face recognition (PIFR) and face synthesis across poses. An extensive quantitative and qualitative evaluation carried out on several controlled and in-the-wild benchmarking datasets demonstrates the superiority of the proposed DED-GAN method over the state-of-the-art approaches.
Joint Group Feature Selection and Discriminative Filter Learning for Robust Visual Object Tracking
Aug 02, 2019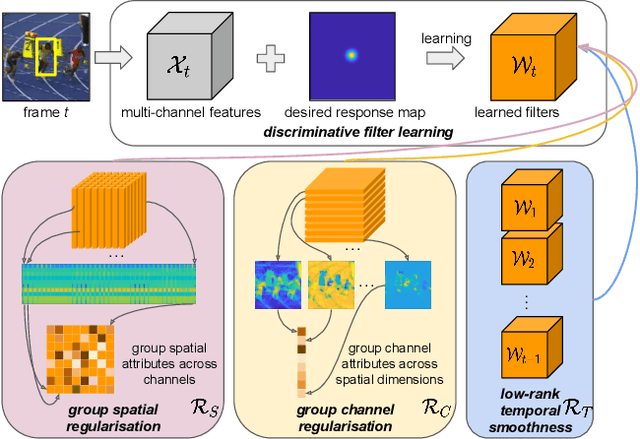
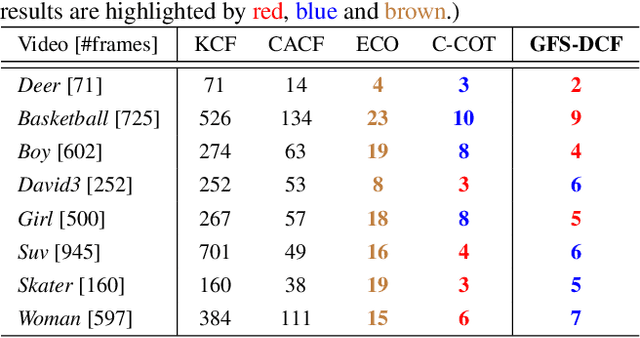
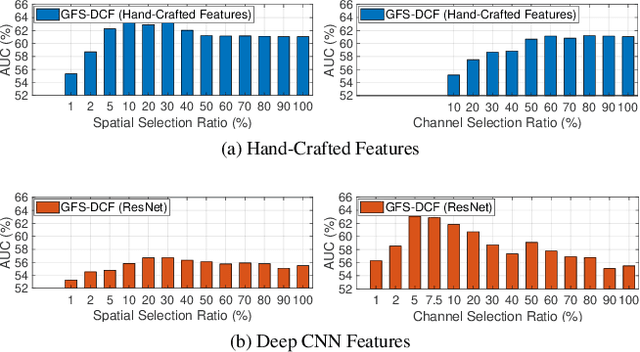
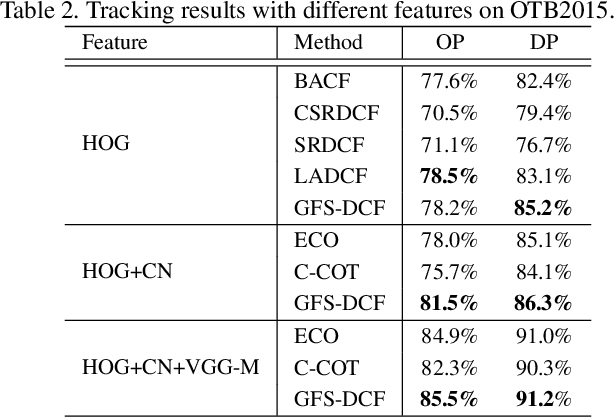
We propose a new Group Feature Selection method for Discriminative Correlation Filters (GFS-DCF) based visual object tracking. The key innovation of the proposed method is to perform group feature selection across both channel and spatial dimensions, thus to pinpoint the structural relevance of multi-channel features to the filtering system. In contrast to the widely used spatial regularisation or feature selection methods, to the best of our knowledge, this is the first time that channel selection has been advocated for DCF-based tracking. We demonstrate that our GFS-DCF method is able to significantly improve the performance of a DCF tracker equipped with deep neural network features. In addition, our GFS-DCF enables joint feature selection and filter learning, achieving enhanced discrimination and interpretability of the learned filters. To further improve the performance, we adaptively integrate historical information by constraining filters to be smooth across temporal frames, using an efficient low-rank approximation. By design, specific temporal-spatial-channel configurations are dynamically learned in the tracking process, highlighting the relevant features, and alleviating the performance degrading impact of less discriminative representations and reducing information redundancy. The experimental results obtained on OTB2013, OTB2015, VOT2017, VOT2018 and TrackingNet demonstrate the merits of our GFS-DCF and its superiority over the state-of-the-art trackers. The code is publicly available at https://github.com/XU-TIANYANG/GFS-DCF.
Transition Subspace Learning based Least Squares Regression for Image Classification
May 14, 2019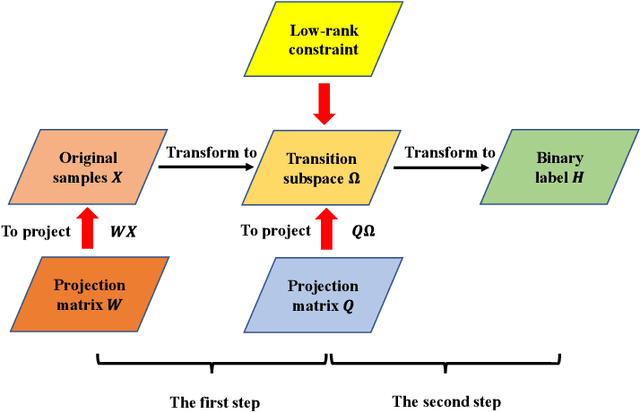
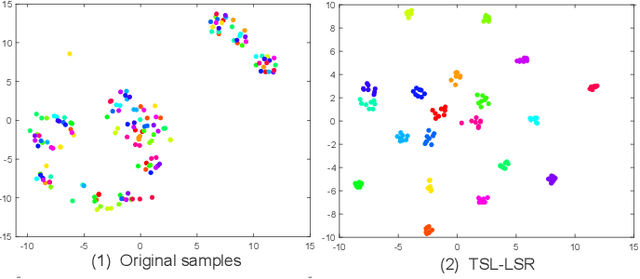
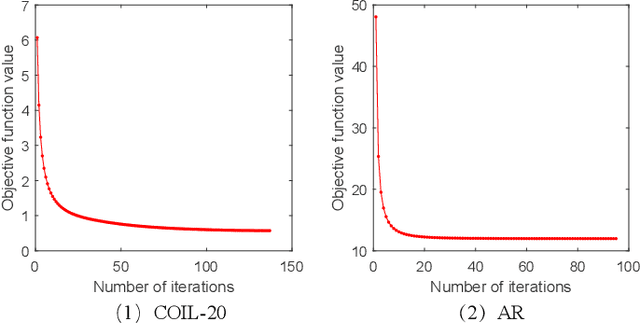
Only learning one projection matrix from original samples to the corresponding binary labels is too strict and will consequentlly lose some intrinsic geometric structures of data. In this paper, we propose a novel transition subspace learning based least squares regression (TSL-LSR) model for multicategory image classification. The main idea of TSL-LSR is to learn a transition subspace between the original samples and binary labels to alleviate the problem of overfitting caused by strict projection learning. Moreover, in order to reflect the underlying low-rank structure of transition matrix and learn more discriminative projection matrix, a low-rank constraint is added to the transition subspace. Experimental results on several image datasets demonstrate the effectiveness of the proposed TSL-LSR model in comparison with state-of-the-art algorithms
Low-Rank Discriminative Least Squares Regression for Image Classification
Apr 16, 2019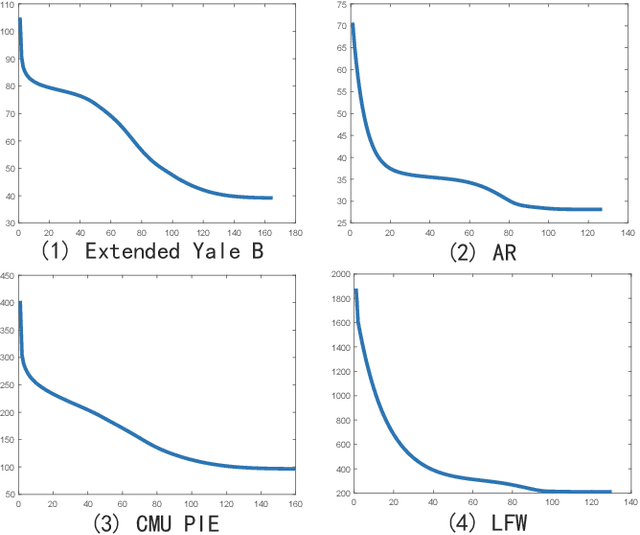


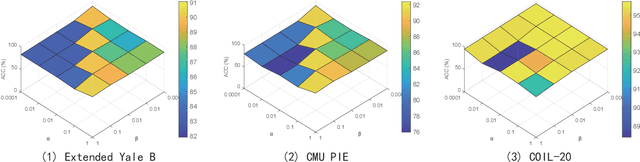
Latest least squares regression (LSR) methods mainly try to learn slack regression targets to replace strict zero-one labels. However, the difference of intra-class targets can also be highlighted when enlarging the distance between different classes, and roughly persuing relaxed targets may lead to the problem of overfitting. To solve above problems, we propose a low-rank discriminative least squares regression model (LRDLSR) for multi-class image classification. Specifically, LRDLSR class-wisely imposes low-rank constraint on the intra-class regression targets to encourage its compactness and similarity. Moreover, LRDLSR introduces an additional regularization term on the learned targets to avoid the problem of overfitting. These two improvements are helpful to learn a more discriminative projection for regression and thus achieving better classification performance. Experimental results over a range of image databases demonstrate the effectiveness of the proposed LRDLSR method.
Cross-modal subspace learning with Kernel correlation maximization and Discriminative structure preserving
Mar 26, 2019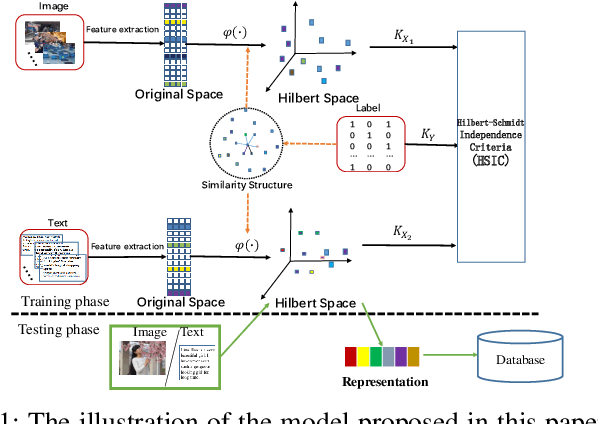
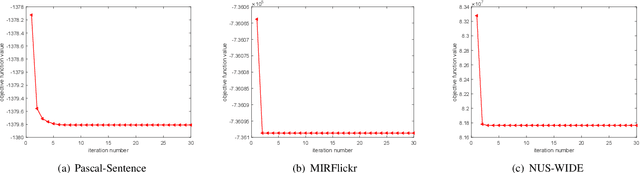
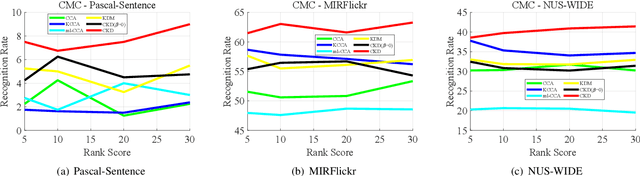
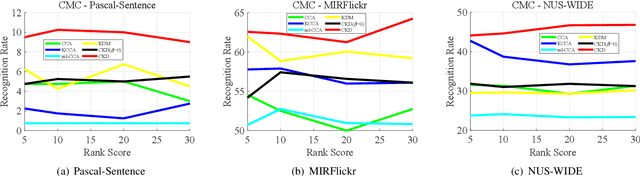
The measure between heterogeneous data is still an open problem. Many research works have been developed to learn a common subspace where the similarity between different modalities can be calculated. However, most of existing works focus on learning low dimensional subspace and ignore the loss of discriminative information in process of reducing dimension. Thus, these approaches cannot get the results they expected. On basis of the Hilbert space theory in which different Hilbert spaces but with same dimension are isomorphic, we propose a novel framework where the multiple use of label information can facilitate more discriminative subspace representation to learn isomorphic Hilbert space for each modal. Our model not only considers the inter-modality correlation by maximizing the kernel correlation, but also preserves the structure information within each modal according to constructed graph model. Extensive experiments are performed to evaluate the proposed framework, termed Cross-modal subspace learning with Kernel correlation maximization and Discriminative structure preserving (CKD), on the three public datasets. Experimental results demonstrated the competitive performance of the proposed CKD compared with the classic subspace learning methods.