 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Visual Tracking via Implicit Low-Rank Constraints and Structural Color Histograms
Dec 24, 2019

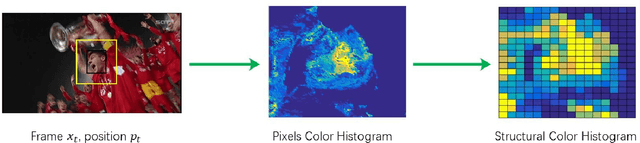
With the guaranteed discrimination and efficiency of spatial appearance model, Discriminative Correlation Filters (DCF-) based tracking methods have achieved outstanding performance recently. However, the construction of effective temporal appearance model is still challenging on account of filter degeneration becomes a significant factor that causes tracking failures in the DCF framework. To encourage temporal continuity and to explore the smooth variation of target appearance, we propose to enhance low-rank structure of the learned filters, which can be realized by constraining the successive filters within a $\ell_2$-norm ball. Moreover, we design a global descriptor, structural color histograms, to provide complementary support to the final response map, improving the stability and robustness to the DCF framework. The experimental results on standard benchmarks demonstrate that our Implicit Low-Rank Constraints and Structural Color Histograms (ILRCSCH) tracker outperforms state-of-the-art methods.
Adaptive Distraction Context Aware Tracking Based on Correlation Filter
Dec 24, 2019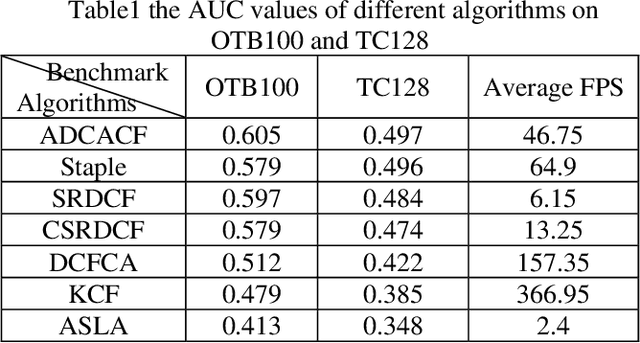
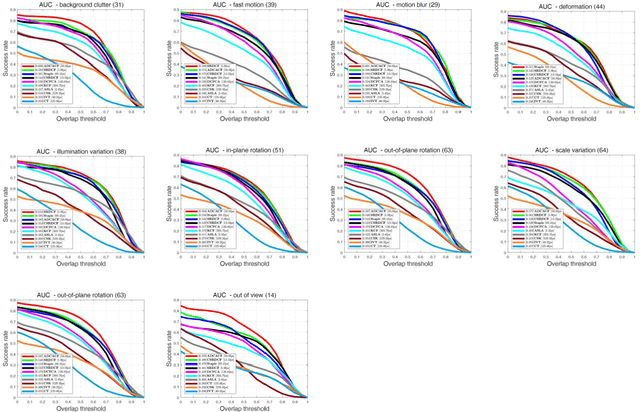

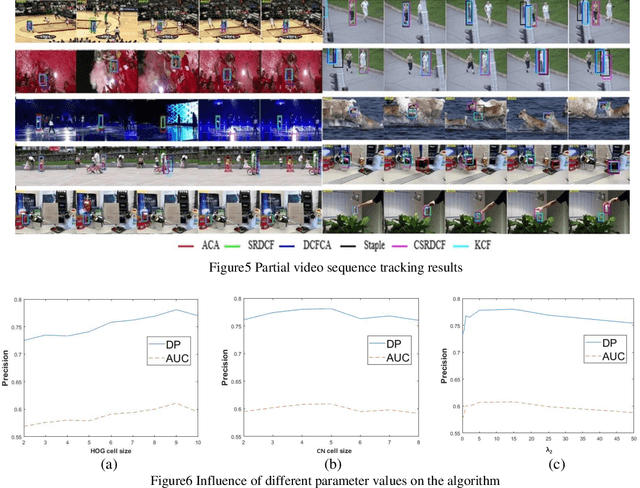
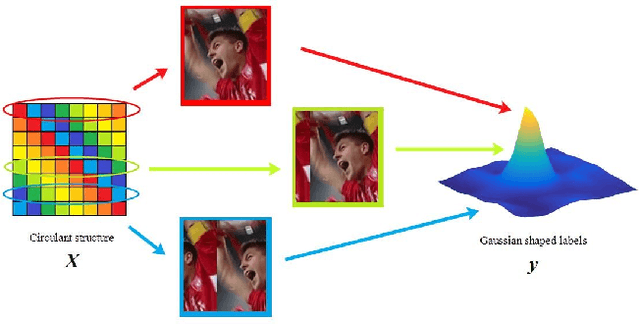
The Discriminative Correlation Filter (CF) uses a circulant convolution operation to provide several training samples for the design of a classifier that can distinguish the target from the background. The filter design may be interfered by objects close to the target during the tracking process, resulting in tracking failure. This paper proposes an adaptive distraction context aware tracking algorithm to solve this problem. In the response map obtained for the previous frame by the CF algorithm, we adaptively find the image blocks that are similar to the target and use them as negative samples. This diminishes the influence of similar image blocks on the classifier in the tracking process and its accuracy is improved. The tracking results on video sequences show that the algorithm can cope with rapid changes such as occlusion and rotation, and can adaptively use the distractive objects around the target as negative samples to improve the accuracy of target tracking.
2DR1-PCA and 2DL1-PCA: two variant 2DPCA algorithms based on none L2 norm
Dec 23, 2019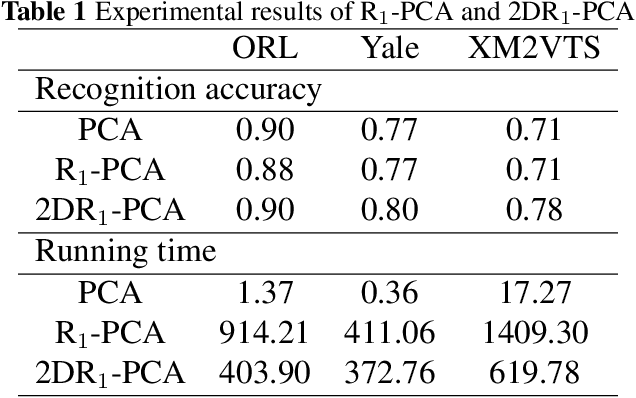
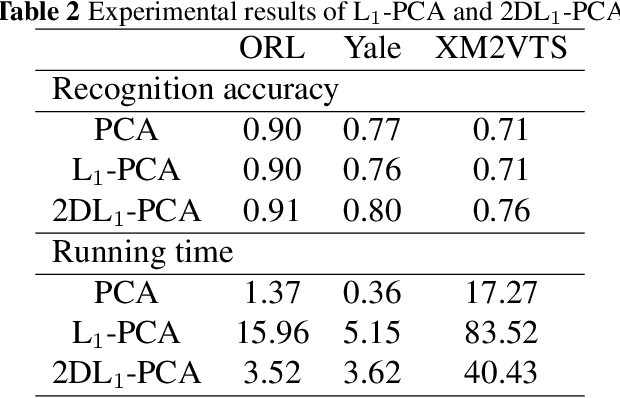
In this paper, two novel methods: 2DR1-PCA and 2DL1-PCA are proposed for face recognition. Compared to the traditional 2DPCA algorithm, 2DR1-PCA and 2DL1-PCA are based on the R1 norm and L1 norm, respectively. The advantage of these proposed methods is they are less sensitive to outliers. These proposed methods are tested on the ORL, YALE and XM2VTS databases and the performance of the related methods is compared experimentally.
A Compared Study Between Some Subspace Based Algorithms
Dec 23, 2019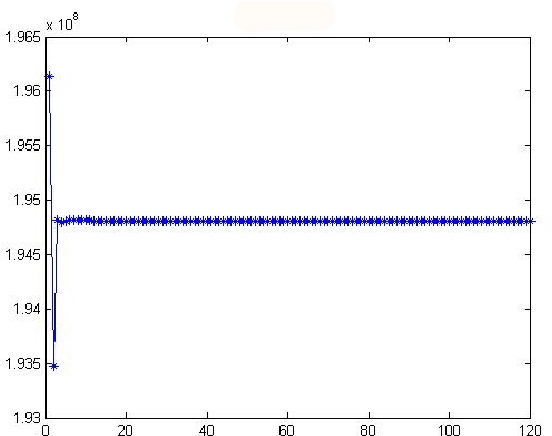

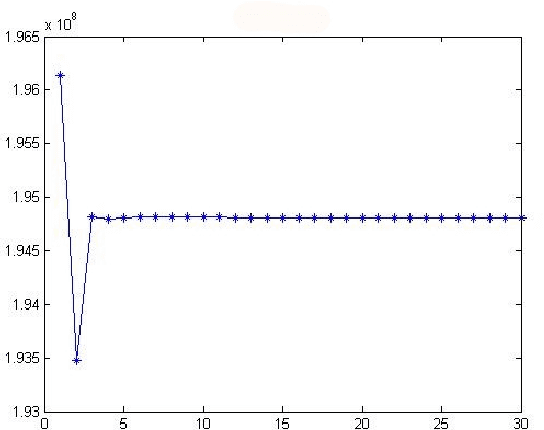
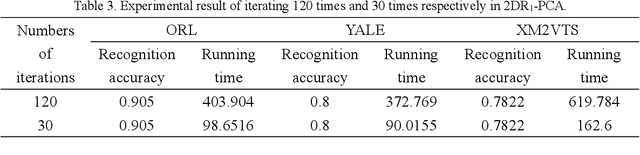
The technology of face recognition has made some progress in recent years. After studying the PCA, 2DPCA, R1-PCA, L1-PCA, KPCA and KECA algorithms, in this paper ECA (2DECA) is proposed by extracting features in PCA (2DPCA) based on Renyi entropy contribution. And then we conduct a study on the 2DL1-PCA and 2DR1-PCA algorithms. On the basis of the experiments, this paper compares the difference of the recognition accuracy and operational efficiency between the above algorithms.
Research on Clustering Performance of Sparse Subspace Clustering
Dec 21, 2019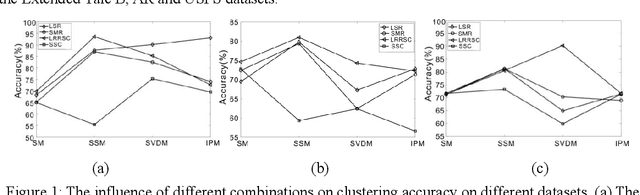
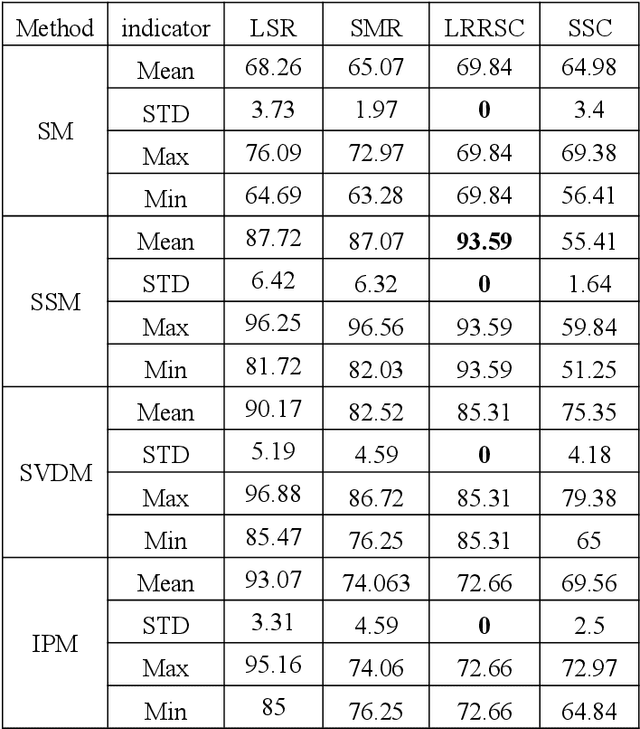

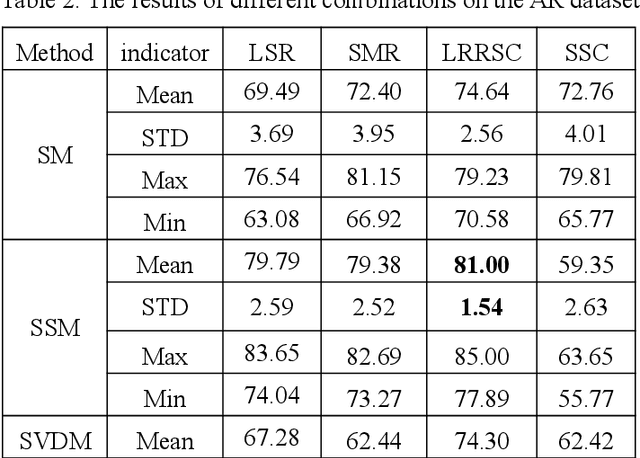
Recently, sparse subspace clustering has been a valid tool to deal with high-dimensional data. There are two essential steps in the framework of sparse subspace clustering. One is solving the coefficient matrix of data, and the other is constructing the affinity matrix from the coefficient matrix, which is applied to the spectral clustering. This paper investigates the factors which affect clustering performance from both clustering accuracy and stability of the approaches based on existing algorithms. We select four methods to solve the coefficient matrix and use four different ways to construct a similarity matrix for each coefficient matrix. Then we compare the clustering performance of different combinations on three datasets. The experimental results indicate that both the coefficient matrix and affinity matrix have a huge influence on clustering performance and how to develop a stable and valid algorithm still needs to be studied.
Multi-focus Image Fusion Based on Similarity Characteristics
Dec 17, 2019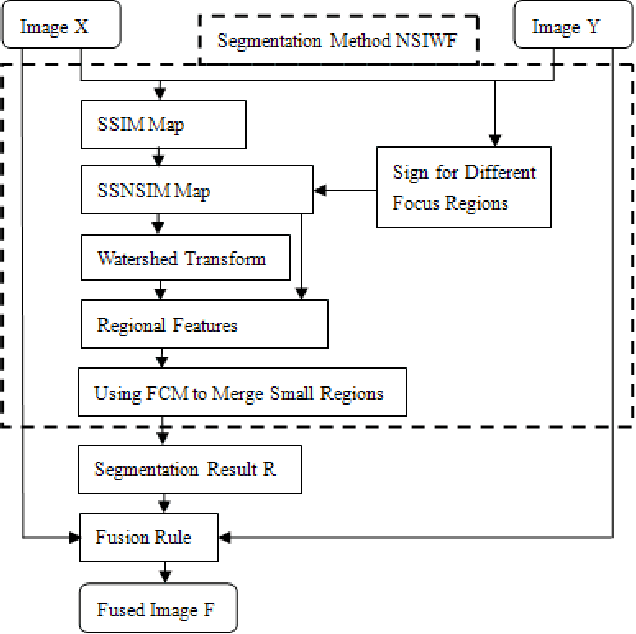
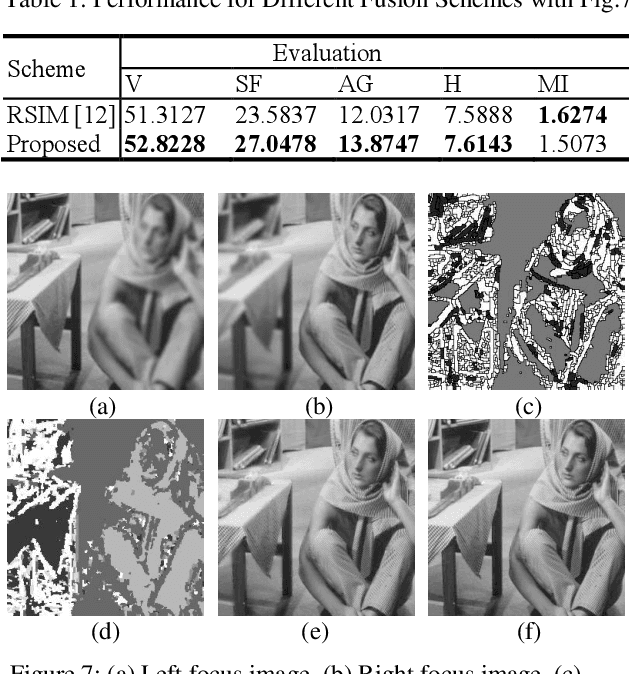
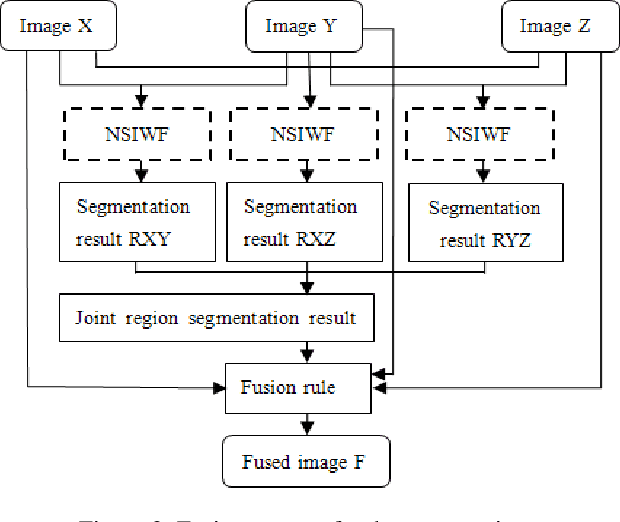
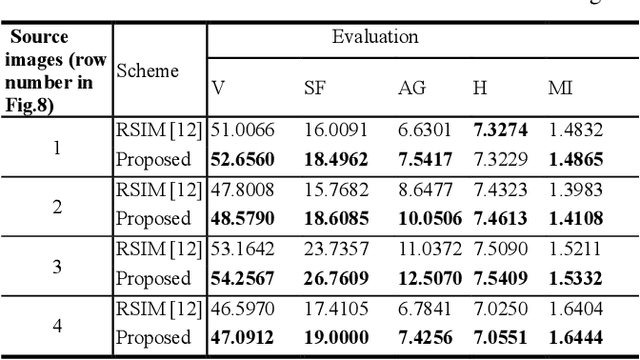
A novel multi-focus image fusion algorithm performed in spatial domain based on similarity characteristics is proposed incorporating with region segmentation. In this paper, a new similarity measure is developed based on the structural similarity (SSIM) index, which is more suitable for multi-focus image segmentation. Firstly, the SSNSIM map is calculated between two input images. Then we segment the SSNSIM map using watershed method, and merge the small homogeneous regions with fuzzy c-means clustering algorithm (FCM). For three source images, a joint region segmentation method based on segmentation of two images is used to obtain the final segmentation result. Finally, the corresponding segmented regions of the source images are fused according to their average gradient. The performance of the image fusion method is evaluated by several criteria including spatial frequency, average gradient, entropy, edge retention etc. The evaluation results indicate that the proposed method is effective and has good visual perception.
Constructing the F-Graph with a Symmetric Constraint for Subspace Clustering
Dec 17, 2019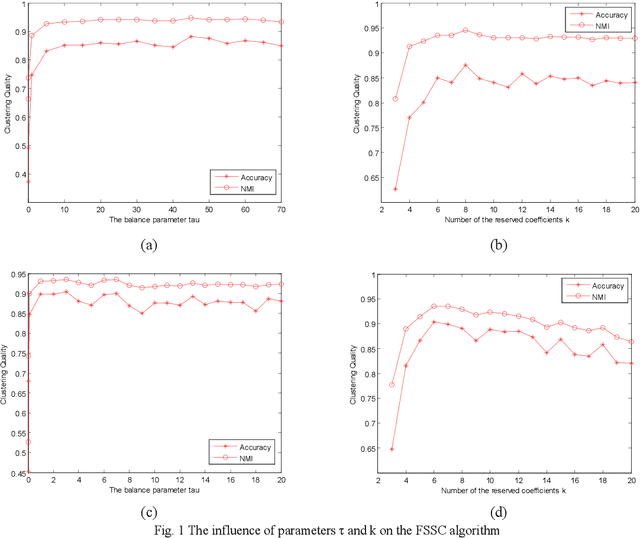
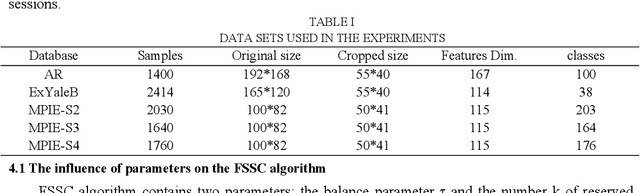
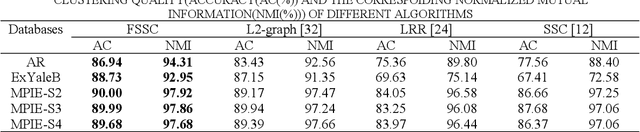

Based on further studying the low-rank subspace clustering (LRSC) and L2-graph subspace clustering algorithms, we propose a F-graph subspace clustering algorithm with a symmetric constraint (FSSC), which constructs a new objective function with a symmetric constraint basing on F-norm, whose the most significant advantage is to obtain a closed-form solution of the coefficient matrix. Then, take the absolute value of each element of the coefficient matrix, and retain the k largest coefficients per column, set the other elements to 0, to get a new coefficient matrix. Finally, FSSC performs spectral clustering over the new coefficient matrix. The experimental results on face clustering and motion segmentation show FSSC algorithm can not only obviously reduce the running time, but also achieve higher accuracy compared with the state-of-the-art representation-based subspace clustering algorithms, which verifies that the FSSC algorithm is efficacious and feasible.
Collaborative representation-based robust face recognition by discriminative low-rank representation
Dec 17, 2019


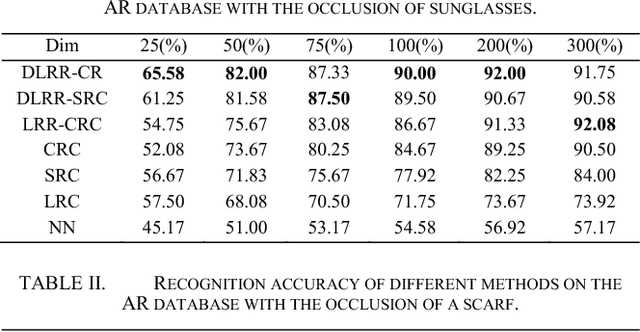
We consider the problem of robust face recognition in which both the training and test samples might be corrupted because of disguise and occlusion. Performance of conventional subspace learning methods and recently proposed sparse representation based classification (SRC) might be degraded when corrupted training samples are provided. In addition, sparsity based approaches are time-consuming due to the sparsity constraint. To alleviate the aforementioned problems to some extent, in this paper, we propose a discriminative low-rank representation method for collaborative representation-based (DLRR-CR) robust face recognition. DLRR-CR not only obtains a clean dictionary, it further forces the sub-dictionaries for distinct classes to be as independent as possible by introducing a structural incoherence regularization term. Simultaneously, a low-rank projection matrix can be learned to remove the possible corruptions in the testing samples. Collaborative representation based classification (CRC) method is exploited in our proposed method which has closed-form solution. Experimental results obtained on public face databases verify the effectiveness and robustness of our method.
Low-rank representations with incoherent dictionary for face recognition
Dec 10, 2019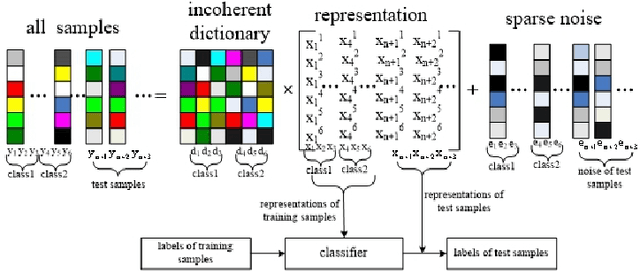
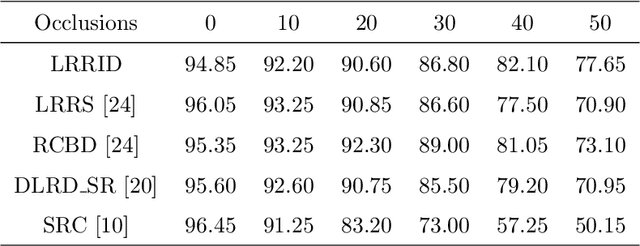

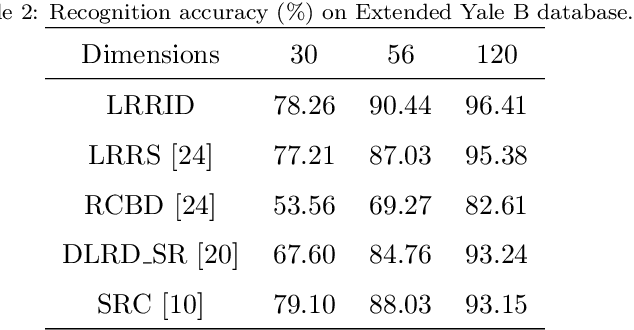
Face recognition remains a hot topic in computer vision, and it is challenging to tackle the problem that both the training and testing images are corrupted. In this paper, we propose a novel semi-supervised method based on the theory of the low-rank matrix recovery for face recognition, which can simultaneously learn discriminative low-rank and sparse representations for both training and testing images. To this end, a correlation penalty term is introduced into the formulation of our proposed method to learn an incoherent dictionary. Experimental results on several face image databases demonstrate the effectiveness of our method, i.e., the proposed method is robust to the illumination, expression and pose variations, as well as images with noises such as block occlusion or uniform noises.
Face Recognition via Locality Constrained Low Rank Representation and Dictionary Learning
Dec 06, 2019

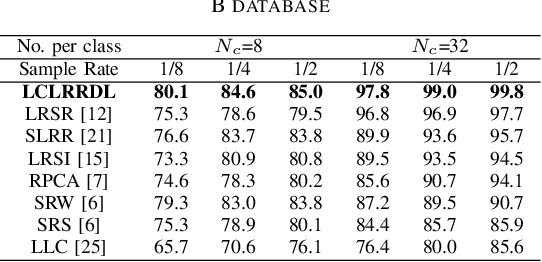
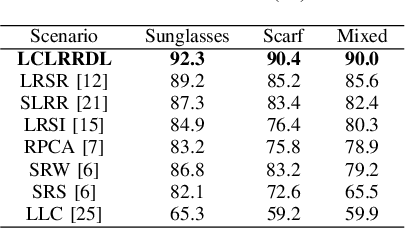
Face recognition has been widely studied due to its importance in smart cities applications. However, the case when both training and test images are corrupted is not well solved. To address such a problem, this paper proposes a locality constrained low rank representation and dictionary learning (LCLRRDL) algorithm for robust face recognition. In particular, we present three contributions in the proposed formulation. First, a low-rank representation is introduced to handle the possible contamination of the training as well as test data. Second, a locality constraint is incorporated to acknowledge the intrinsic manifold structure of training data. With the locality constraint term, our scheme induces similar samples to have similar representations. Third, a compact dictionary is learned to handle the problem of corrupted data. The experimental results on two public databases demonstrate the effectiveness of the proposed approach. Matlab code of our proposed LCLRRDL can be downloaded from https://github.com/yinhefeng/LCLRRDL.