 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank features based double transformation matrices learning for image classification
Feb 17, 2022Linear regression is a supervised method that has been widely used in classification tasks. In order to apply linear regression to classification tasks, a technique for relaxing regression targets was proposed. However, methods based on this technique ignore the pressure on a single transformation matrix due to the complex information contained in the data. A single transformation matrix in this case is too strict to provide a flexible projection, thus it is necessary to adopt relaxation on transformation matrix. This paper proposes a double transformation matrices learning method based on latent low-rank feature extraction. The core idea is to use double transformation matrices for relaxation, and jointly projecting the learned principal and salient features from two directions into the label space, which can share the pressure of a single transformation matrix. Firstly, the low-rank features are learned by the latent low rank representation (LatLRR) method which processes the original data from two directions. In this process, sparse noise is also separated, which alleviates its interference on projection learning to some extent. Then, two transformation matrices are introduced to process the two features separately, and the information useful for the classification is extracted. Finally, the two transformation matrices can be easily obtained by alternate optimization methods. Through such processing, even when a large amount of redundant information is contained in samples, our method can also obtain projection results that are easy to classify. Experiments on multiple data sets demonstrate the effectiveness of our approach for classification, especially for complex scenarios.
TGFuse: An Infrared and Visible Image Fusion Approach Based on Transformer and Generative Adversarial Network
Feb 04, 2022
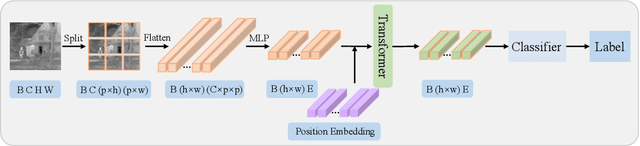
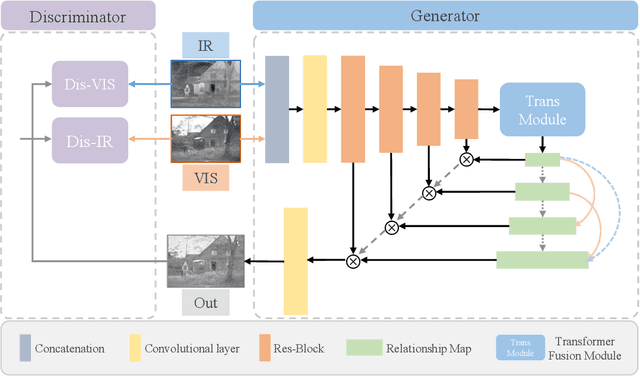
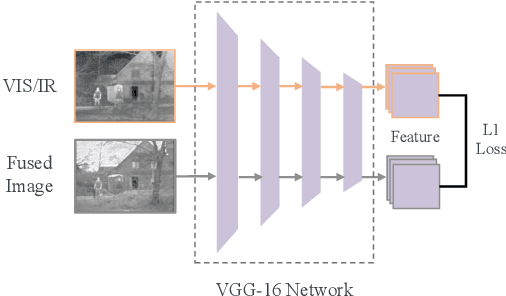
The end-to-end image fusion framework has achieved promising performance, with dedicated convolutional networks aggregating the multi-modal local appearance. However, long-range dependencies are directly neglected in existing CNN fusion approaches, impeding balancing the entire image-level perception for complex scenario fusion. In this paper, therefore, we propose an infrared and visible image fusion algorithm based on a lightweight transformer module and adversarial learning. Inspired by the global interaction power, we use the transformer technique to learn the effective global fusion relations. In particular, shallow features extracted by CNN are interacted in the proposed transformer fusion module to refine the fusion relationship within the spatial scope and across channels simultaneously. Besides, adversarial learning is designed in the training process to improve the output discrimination via imposing competitive consistency from the inputs, reflecting the specific characteristics in infrared and visible images. The experimental performance demonstrates the effectiveness of the proposed modules, with superior improvement against the state-of-the-art, generalising a novel paradigm via transformer and adversarial learning in the fusion task.
Unsupervised Image Fusion Method based on Feature Mutual Mapping
Jan 29, 2022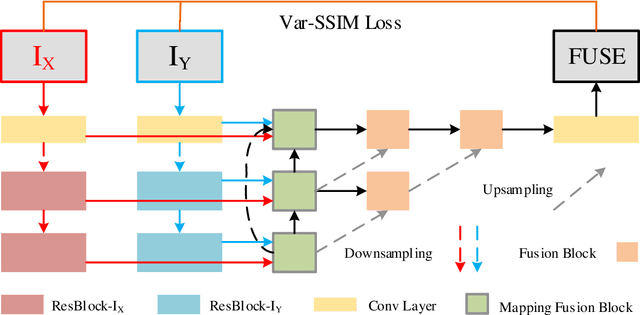
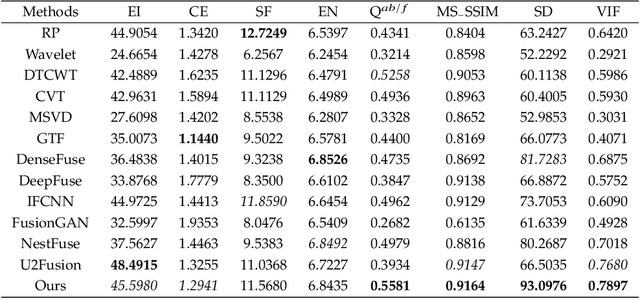
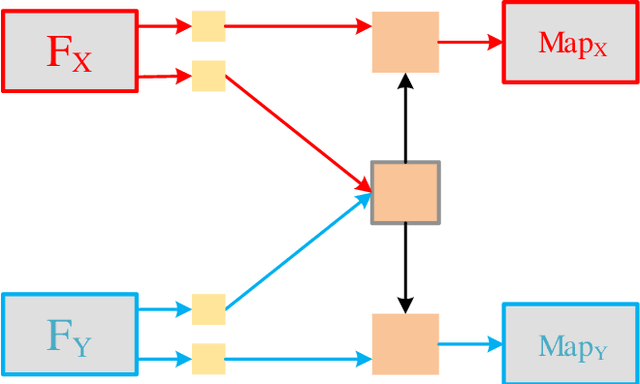
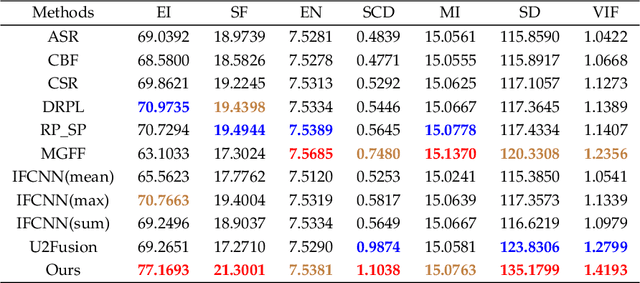
Deep learning-based image fusion approaches have obtained wide attention in recent years, achieving promising performance in terms of visual perception. However, the fusion module in the current deep learning-based methods suffers from two limitations, \textit{i.e.}, manually designed fusion function, and input-independent network learning. In this paper, we propose an unsupervised adaptive image fusion method to address the above issues. We propose a feature mutual mapping fusion module and dual-branch multi-scale autoencoder. More specifically, we construct a global map to measure the connections of pixels between the input source images. % The found mapping relationship guides the image fusion. Besides, we design a dual-branch multi-scale network through sampling transformation to extract discriminative image features. We further enrich feature representations of different scales through feature aggregation in the decoding process. Finally, we propose a modified loss function to train the network with efficient convergence property. Through sufficient training on infrared and visible image data sets, our method also shows excellent generalized performance in multi-focus and medical image fusion. Our method achieves superior performance in both visual perception and objective evaluation. Experiments prove that the performance of our proposed method on a variety of image fusion tasks surpasses other state-of-the-art methods, proving the effectiveness and versatility of our approach.
MSNet: A Deep Multi-scale Submanifold Network for Visual Classification
Jan 29, 2022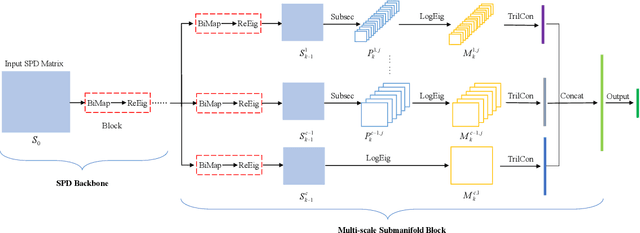
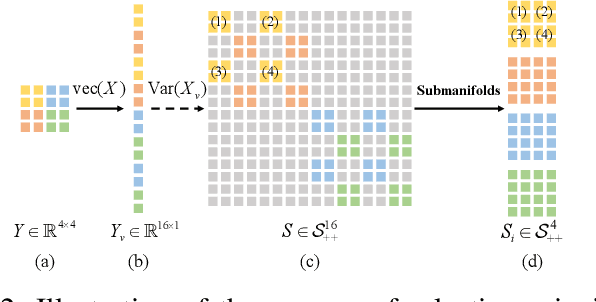


The Symmetric Positive Definite (SPD) matrix has received wide attention as a tool for visual data representation in computer vision. Although there are many different attempts to develop effective deep architectures for data processing on the Riemannian manifold of SPD matrices, a very few solutions explicitly mine the local geometrical information in deep SPD feature representations. While CNNs have demonstrated the potential of hierarchical local pattern extraction even for SPD represented data, we argue that it is of utmost importance to ensure the preservation of local geometric information in the SPD networks. Accordingly, in this work we propose an SPD network designed with this objective in mind. In particular, we propose an architecture, referred to as MSNet, which fuses geometrical multi-scale information. We first analyse the convolution operator commonly used for mapping the local information in Euclidean deep networks from the perspective of a higher level of abstraction afforded by the Category Theory. Based on this analysis, we postulate a submanifold selection principle to guide the design of our MSNet. In particular, we use it to design a submanifold fusion block to take advantage of the rich local geometry encoded in the network layers. The experiments involving multiple visual tasks show that our algorithm outperforms most Riemannian SOTA competitors.
Visual Object Tracking on Multi-modal RGB-D Videos: A Review
Jan 29, 2022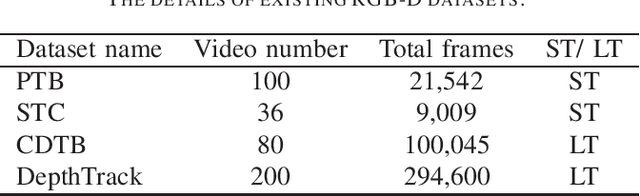
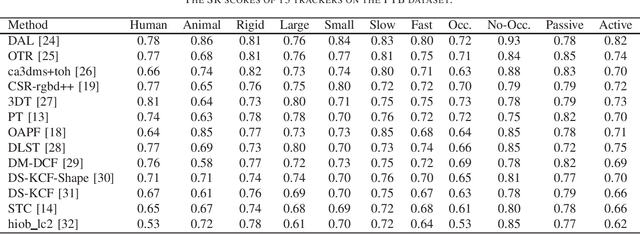
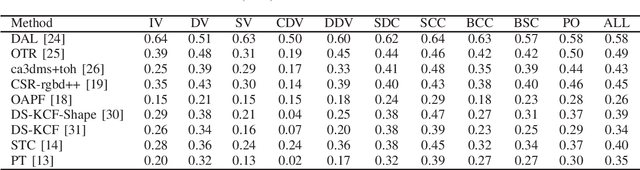

The development of visual object tracking has continued for decades. Recent years, as the wide accessibility of the low-cost RGBD sensors, the task of visual object tracking on RGB-D videos has drawn much attention. Compared to conventional RGB-only tracking, the RGB-D videos can provide more information that facilitates objecting tracking in some complicated scenarios. The goal of this review is to summarize the relative knowledge of the research filed of RGB-D tracking. To be specific, we will generalize the related RGB-D tracking benchmarking datasets as well as the corresponding performance measurements. Besides, the existing RGB-D tracking methods are summarized in the paper. Moreover, we discuss the possible future direction in the field of RGB-D tracking.
Face recognition via compact second order image gradient orientations
Jan 29, 2022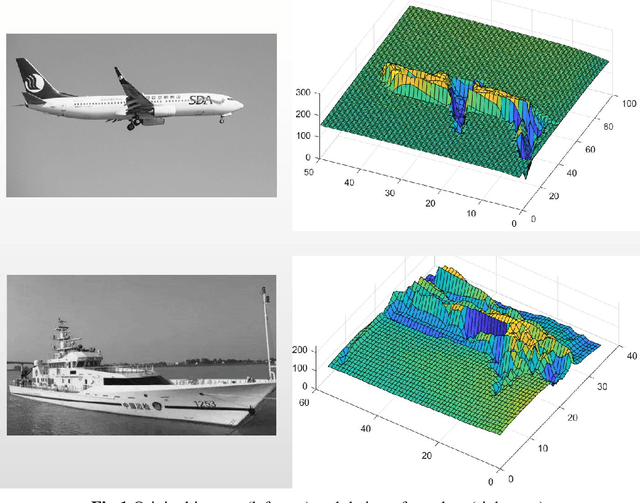
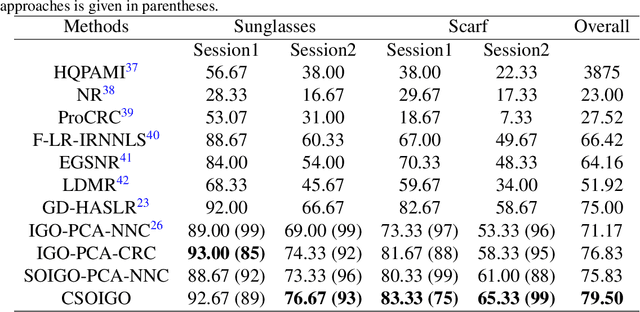

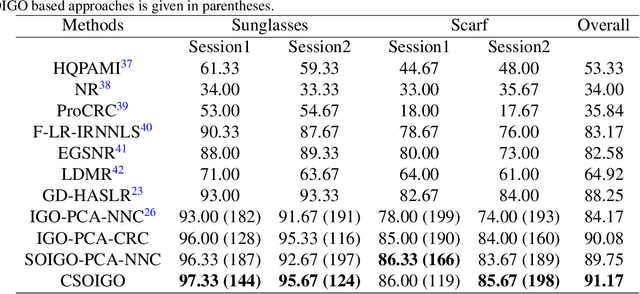
Conventional subspace learning approaches based on image gradient orientations only employ the first-order gradient information. However, recent researches on human vision system (HVS) uncover that the neural image is a landscape or a surface whose geometric properties can be captured through the second order gradient information. The second order image gradient orientations (SOIGO) can mitigate the adverse effect of noises in face images. To reduce the redundancy of SOIGO, we propose compact SOIGO (CSOIGO) by applying linear complex principal component analysis (PCA) in SOIGO. Combined with collaborative representation based classification (CRC) algorithm, the classification performance of CSOIGO is further enhanced. CSOIGO is evaluated under real-world disguise, synthesized occlusion and mixed variations. Experimental results indicate that the proposed method is superior to its competing approaches with few training samples, and even outperforms some prevailing deep neural network based approaches. The source code of CSOIGO is available at https://github.com/yinhefeng/SOIGO.
Temporal Aggregation for Adaptive RGBT Tracking
Jan 29, 2022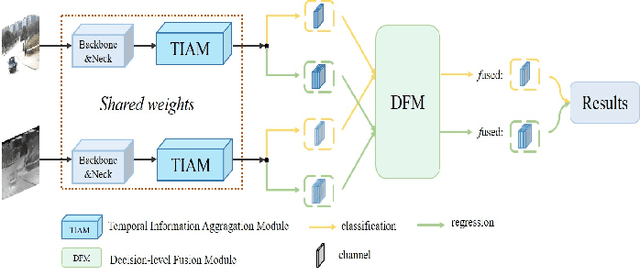
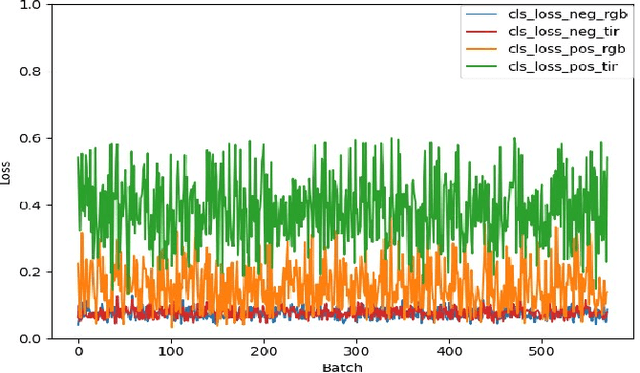
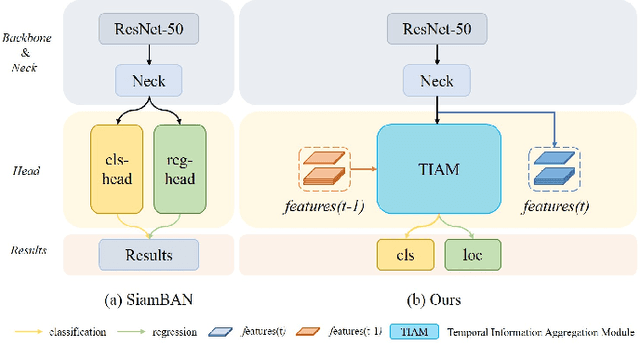
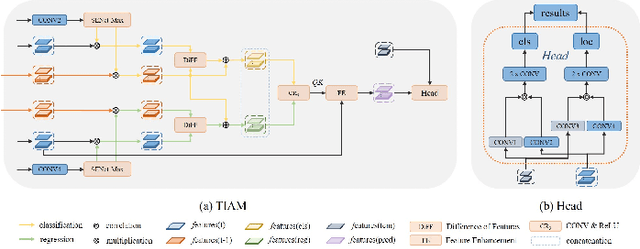
Visual object tracking with RGB and thermal infrared (TIR) spectra available, shorted in RGBT tracking, is a novel and challenging research topic which draws increasing attention nowadays. In this paper, we propose an RGBT tracker which takes spatio-temporal clues into account for robust appearance model learning, and simultaneously, constructs an adaptive fusion sub-network for cross-modal interactions. Unlike most existing RGBT trackers that implement object tracking tasks with only spatial information included, temporal information is further considered in this method. Specifically, different from traditional Siamese trackers, which only obtain one search image during the process of picking up template-search image pairs, an extra search sample adjacent to the original one is selected to predict the temporal transformation, resulting in improved robustness of tracking performance.As for multi-modal tracking, constrained to the limited RGBT datasets, the adaptive fusion sub-network is appended to our method at the decision level to reflect the complementary characteristics contained in two modalities. To design a thermal infrared assisted RGB tracker, the outputs of the classification head from the TIR modality are taken into consideration before the residual connection from the RGB modality. Extensive experimental results on three challenging datasets, i.e. VOT-RGBT2019, GTOT and RGBT210, verify the effectiveness of our method. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/TAAT}}.
A Survey for Deep RGBT Tracking
Jan 29, 2022
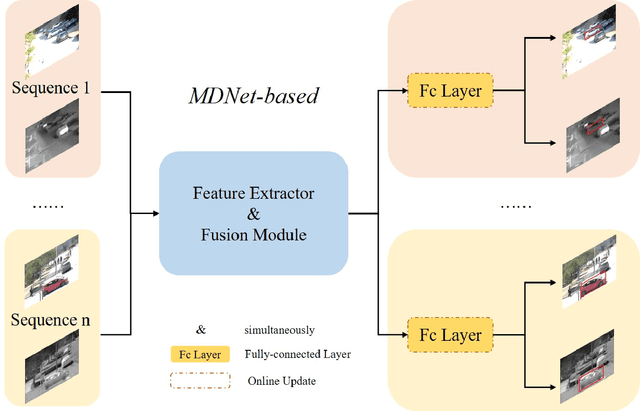
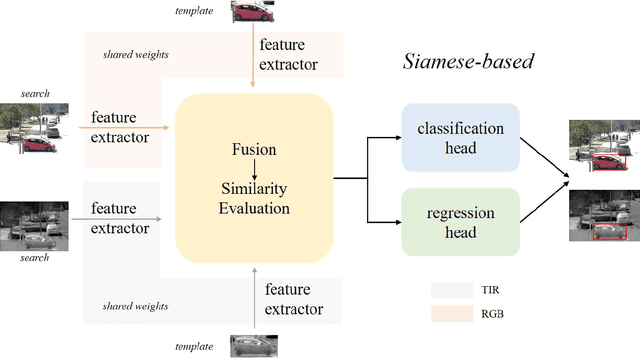
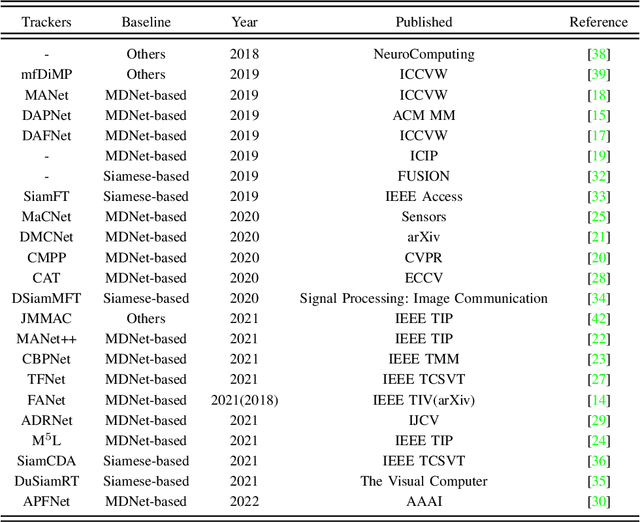
Visual object tracking with the visible (RGB) and thermal infrared (TIR) electromagnetic waves, shorted in RGBT tracking, recently draws increasing attention in the tracking community. Considering the rapid development of deep learning, a survey for the recent deep neural network based RGBT trackers is presented in this paper. Firstly, we give brief introduction for the RGBT trackers concluded into this category. Then, a comparison among the existing RGBT trackers on several challenging benchmarks is given statistically. Specifically, MDNet and Siamese architectures are the two mainstream frameworks in the RGBT community, especially the former. Trackers based on MDNet achieve higher performance while Siamese-based trackers satisfy the real-time requirement. In summary, since the large-scale dataset LasHeR is published, the integration of end-to-end framework, e.g., Siamese and Transformer, should be further considered to fulfil the real-time as well as more robust performance. Furthermore, the mathematical meaning should be more considered during designing the network. This survey can be treated as a look-up-table for researchers who are concerned about RGBT tracking.
Discriminative Supervised Subspace Learning for Cross-modal Retrieval
Jan 26, 2022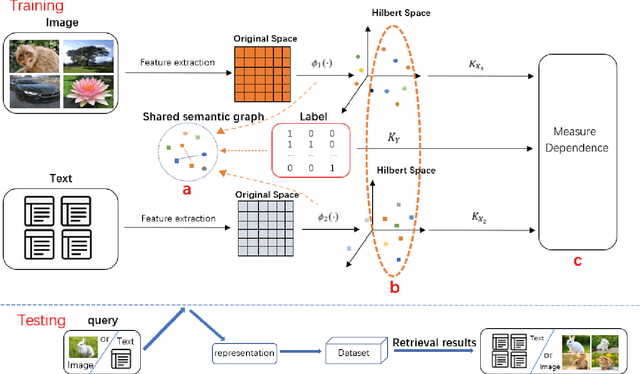
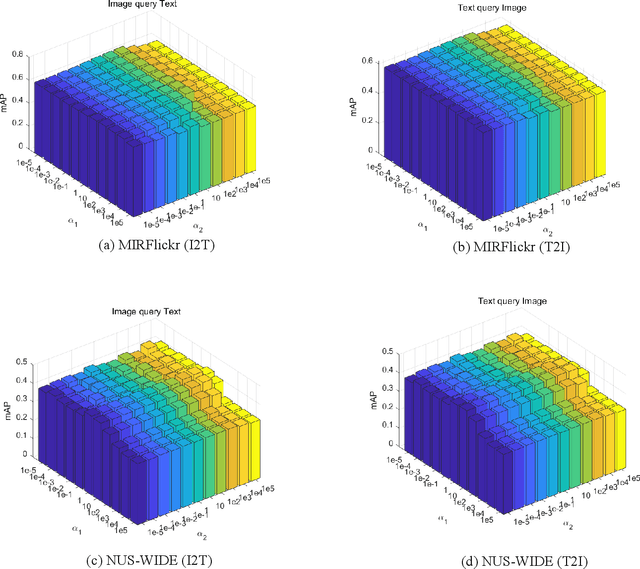
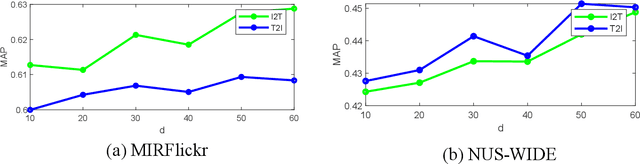
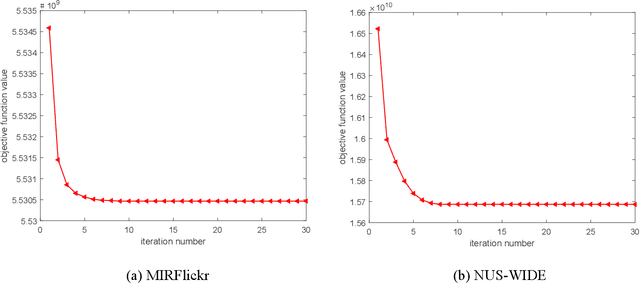
Nowadays the measure between heterogeneous data is still an open problem for cross-modal retrieval. The core of cross-modal retrieval is how to measure the similarity between different types of data. Many approaches have been developed to solve the problem. As one of the mainstream, approaches based on subspace learning pay attention to learning a common subspace where the similarity among multi-modal data can be measured directly. However, many of the existing approaches only focus on learning a latent subspace. They ignore the full use of discriminative information so that the semantically structural information is not well preserved. Therefore satisfactory results can not be achieved as expected. We in this paper propose a discriminative supervised subspace learning for cross-modal retrieval(DS2L), to make full use of discriminative information and better preserve the semantically structural information. Specifically, we first construct a shared semantic graph to preserve the semantic structure within each modality. Subsequently, the Hilbert-Schmidt Independence Criterion(HSIC) is introduced to preserve the consistence between feature-similarity and semantic-similarity of samples. Thirdly, we introduce a similarity preservation term, thus our model can compensate for the shortcomings of insufficient use of discriminative data and better preserve the semantically structural information within each modality. The experimental results obtained on three well-known benchmark datasets demonstrate the effectiveness and competitiveness of the proposed method against the compared classic subspace learning approaches.
Infrared and visible image fusion based on Multi-State Contextual Hidden Markov Model
Jan 26, 2022



The traditional two-state hidden Markov model divides the high frequency coefficients only into two states (large and small states). Such scheme is prone to produce an inaccurate statistical model for the high frequency subband and reduces the quality of fusion result. In this paper, a fine-grained multi-state contextual hidden Markov model (MCHMM) is proposed for infrared and visible image fusion in the non-subsampled Shearlet domain, which takes full consideration of the strong correlations and level of details of NSST coefficients. To this end, an accurate soft context variable is designed correspondingly from the perspective of context correlation. Then, the statistical features provided by MCHMM are utilized for the fusion of high frequency subbands. To ensure the visual quality, a fusion strategy based on the difference in regional energy is proposed as well for lowfrequency subbands. Experimental results demonstrate that the proposed method can achieve a superior performance compared with other fusion methods in both subjective and objective aspects.