 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Visual-to-Physical Gap: Physically Aligned Representations for Fall Risk Analysis
Mar 12, 2026Vision-based fall analysis has advanced rapidly, but a key bottleneck remains: visually similarmotions can correspond to very different physical outcomes because small differences in contactmechanics and protective responses are hard to infer from appearance alone. Most existingapproaches handle this by supervised injury prediction, which depends on reliable injury labels.In practice, such labels are difficult to obtain: video evidence is often ambiguous (occlusion,viewpoint limits), and true injury events are rare and cannot be safely staged, leading to noisysupervision. We address this problem with PHARL (PHysics-aware Alignment RepresentationLearning), which learns physically meaningful fall representations without requiring clinicaloutcome labels. PHARL regularizes motion embeddings with two complementary constraints:(1) trajectory-level temporal consistency for stable representation learning, and (2) multi-classphysics alignment, where simulation-derived contact outcomes shape embedding geometry. Bypairing video windows with temporally aligned simulation descriptors, PHARL captures localimpact-relevant dynamics while keeping inference purely feed-forward. Experiments on fourpublic datasets show that PHARL consistently improves risk-aligned representation quality overvisual-only baselines while maintaining strong fall-detection performance. Notably, PHARL alsoexhibits zero-shot ordinality: an interpretable severity structure (Head > Trunk > Supported)emerges without explicit ordinal supervision.
Region-Level Context-Aware Multimodal Understanding
Aug 17, 2025Despite significant progress, existing research on Multimodal Large Language Models (MLLMs) mainly focuses on general visual understanding, overlooking the ability to integrate textual context associated with objects for a more context-aware multimodal understanding -- an ability we refer to as Region-level Context-aware Multimodal Understanding (RCMU). To address this limitation, we first formulate the RCMU task, which requires models to respond to user instructions by integrating both image content and textual information of regions or objects. To equip MLLMs with RCMU capabilities, we propose Region-level Context-aware Visual Instruction Tuning (RCVIT), which incorporates object information into the model input and enables the model to utilize bounding box coordinates to effectively associate objects' visual content with their textual information. To address the lack of datasets, we introduce the RCMU dataset, a large-scale visual instruction tuning dataset that covers multiple RCMU tasks. We also propose RC\&P-Bench, a comprehensive benchmark that can evaluate the performance of MLLMs in RCMU and multimodal personalized understanding tasks. Additionally, we propose a reference-free evaluation metric to perform a comprehensive and fine-grained evaluation of the region-level context-aware image descriptions. By performing RCVIT on Qwen2-VL models with the RCMU dataset, we developed RC-Qwen2-VL models. Experimental results indicate that RC-Qwen2-VL models not only achieve outstanding performance on multiple RCMU tasks but also demonstrate successful applications in multimodal RAG and personalized conversation. Our data, model and benchmark are available at https://github.com/hongliang-wei/RC-MLLM
FLAM: Foundation Model-Based Body Stabilization for Humanoid Locomotion and Manipulation
Mar 28, 2025Humanoid robots have attracted significant attention in recent years. Reinforcement Learning (RL) is one of the main ways to control the whole body of humanoid robots. RL enables agents to complete tasks by learning from environment interactions, guided by task rewards. However, existing RL methods rarely explicitly consider the impact of body stability on humanoid locomotion and manipulation. Achieving high performance in whole-body control remains a challenge for RL methods that rely solely on task rewards. In this paper, we propose a Foundation model-based method for humanoid Locomotion And Manipulation (FLAM for short). FLAM integrates a stabilizing reward function with a basic policy. The stabilizing reward function is designed to encourage the robot to learn stable postures, thereby accelerating the learning process and facilitating task completion. Specifically, the robot pose is first mapped to the 3D virtual human model. Then, the human pose is stabilized and reconstructed through a human motion reconstruction model. Finally, the pose before and after reconstruction is used to compute the stabilizing reward. By combining this stabilizing reward with the task reward, FLAM effectively guides policy learning. Experimental results on a humanoid robot benchmark demonstrate that FLAM outperforms state-of-the-art RL methods, highlighting its effectiveness in improving stability and overall performance.
A Memory-Related Multi-Task Method Based on Task-Agnostic Exploration
Sep 09, 2022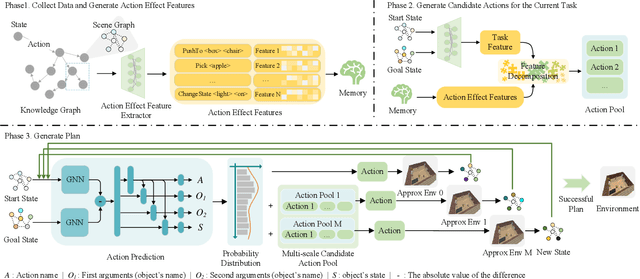
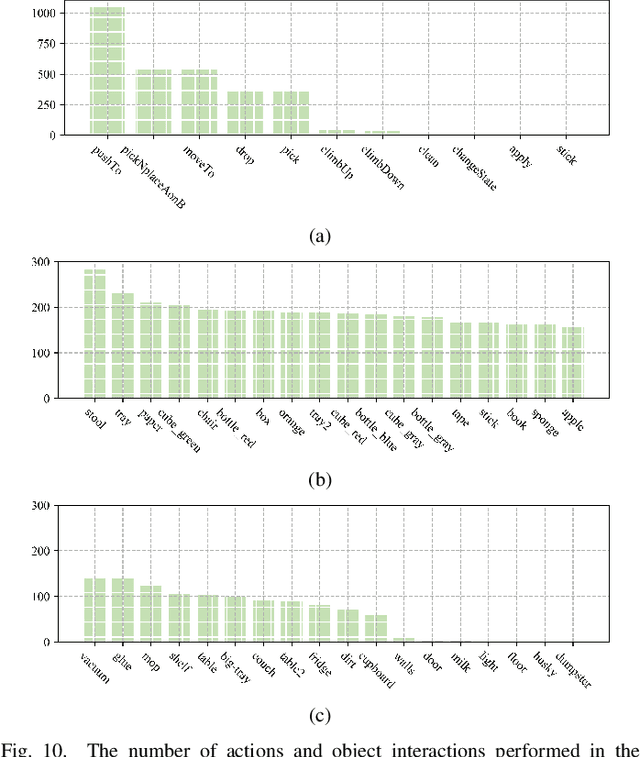
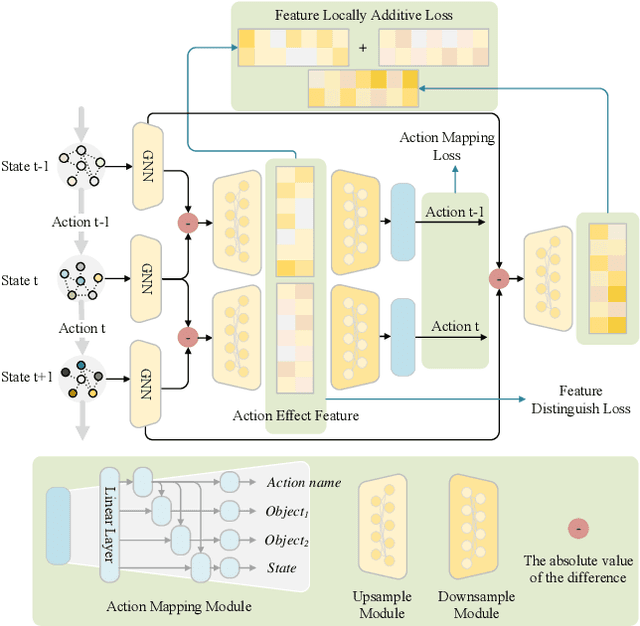
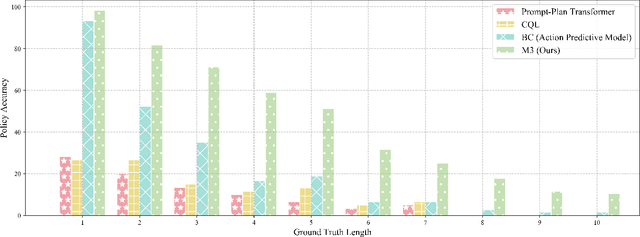
We pose a new question: Can agents learn how to combine actions from previous tasks to complete new tasks, just as humans? In contrast to imitation learning, there is no expert data, only the data collected through environmental exploration. Compared with offline reinforcement learning, the problem of data distribution shift is more serious. Since the action sequence to solve the new task may be the combination of trajectory segments of multiple training tasks, in other words, the test task and the solving strategy do not exist directly in the training data. This makes the problem more difficult. We propose a Memory-related Multi-task Method (M3) to address this problem. The method consists of three stages. First, task-agnostic exploration is carried out to collect data. Different from previous methods, we organize the exploration data into a knowledge graph. We design a model based on the exploration data to extract action effect features and save them in memory, while an action predictive model is trained. Secondly, for a new task, the action effect features stored in memory are used to generate candidate actions by a feature decomposition-based approach. Finally, a multi-scale candidate action pool and the action predictive model are fused to generate a strategy to complete the task. Experimental results show that the performance of our proposed method is significantly improved compared with the baseline.