 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCENet: Toward Concise and Efficient LiDAR Semantic Segmentation for Autonomous Driving
Jul 26, 2022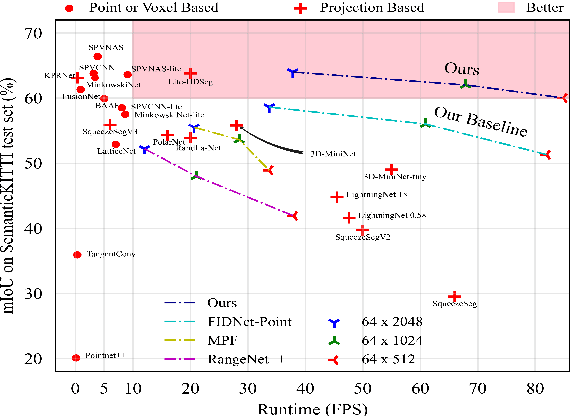
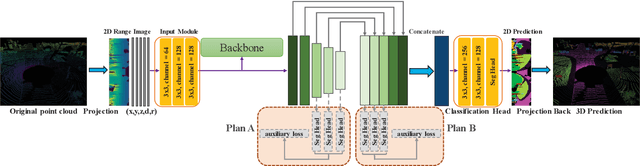
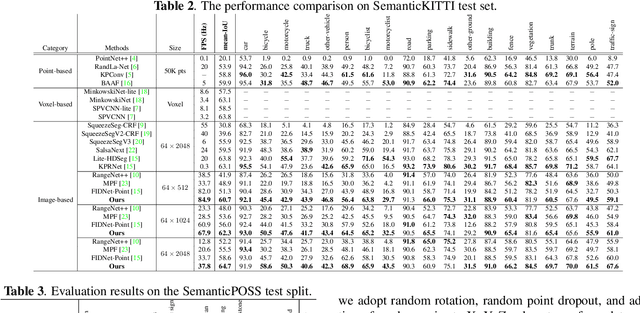

Accurate and fast scene understanding is one of the challenging task for autonomous driving, which requires to take full advantage of LiDAR point clouds for semantic segmentation. In this paper, we present a \textbf{concise} and \textbf{efficient} image-based semantic segmentation network, named \textbf{CENet}. In order to improve the descriptive power of learned features and reduce the computational as well as time complexity, our CENet integrates the convolution with larger kernel size instead of MLP, carefully-selected activation functions, and multiple auxiliary segmentation heads with corresponding loss functions into architecture. Quantitative and qualitative experiments conducted on publicly available benchmarks, SemanticKITTI and SemanticPOSS, demonstrate that our pipeline achieves much better mIoU and inference performance compared with state-of-the-art models. The code will be available at https://github.com/huixiancheng/CENet.
Point Cloud Learning with Transformer
Apr 28, 2021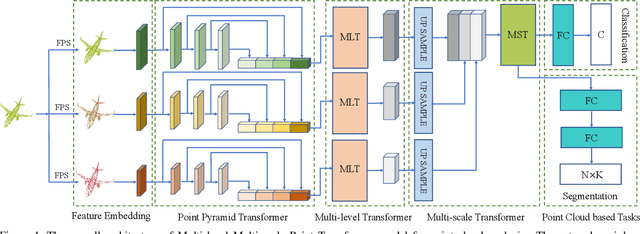
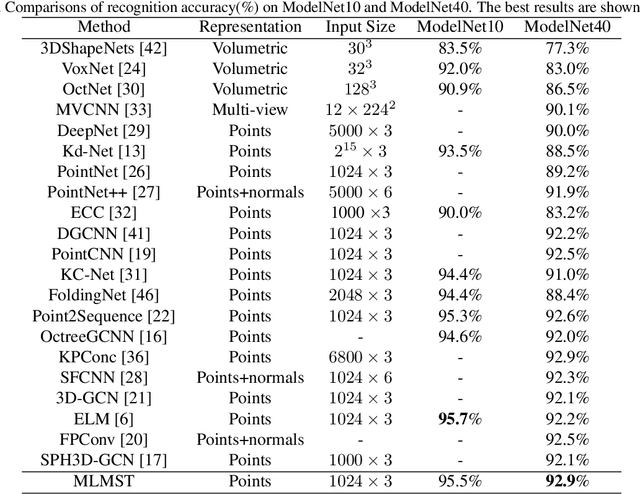
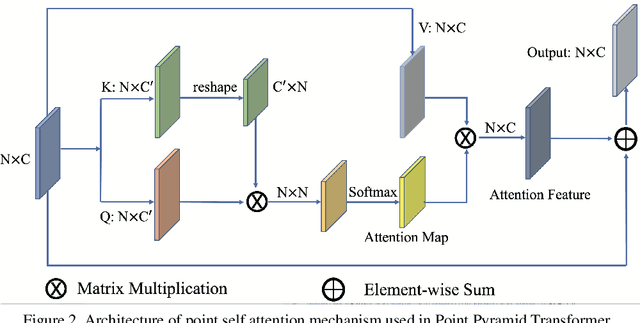
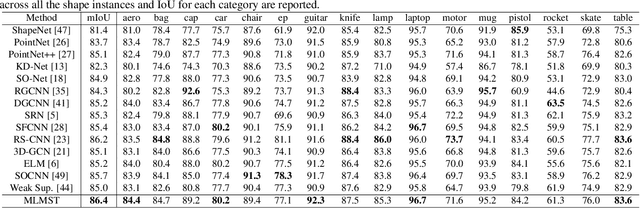
Remarkable performance from Transformer networks in Natural Language Processing promote the development of these models in dealing with computer vision tasks such as image recognition and segmentation. In this paper, we introduce a novel framework, called Multi-level Multi-scale Point Transformer (MLMSPT) that works directly on the irregular point clouds for representation learning. Specifically, a point pyramid transformer is investigated to model features with diverse resolutions or scales we defined, followed by a multi-level transformer module to aggregate contextual information from different levels of each scale and enhance their interactions. While a multi-scale transformer module is designed to capture the dependencies among representations across different scales. Extensive evaluation on public benchmark datasets demonstrate the effectiveness and the competitive performance of our methods on 3D shape classification, part segmentation and semantic segmentation tasks.
Cross-Level Cross-Scale Cross-Attention Network for Point Cloud Representation
Apr 27, 2021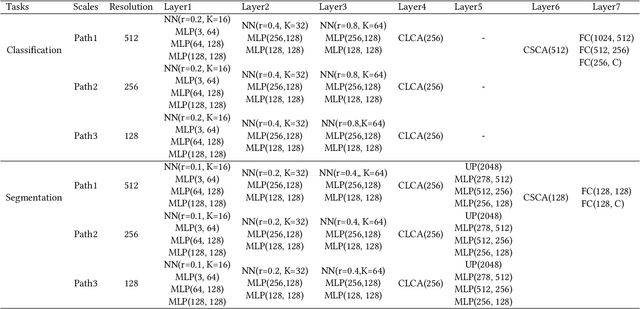
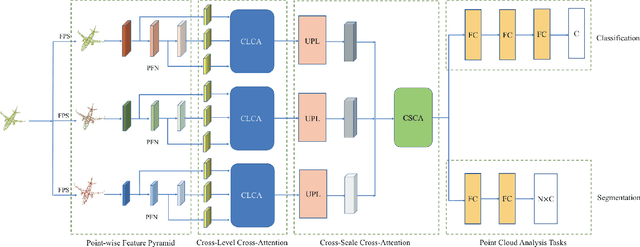
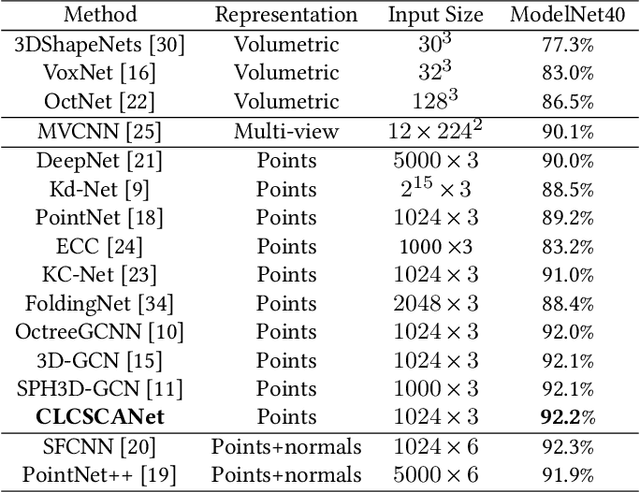
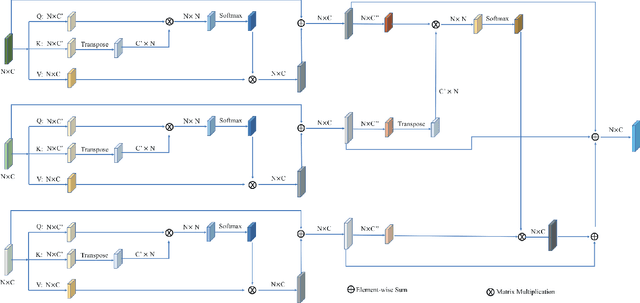
Self-attention mechanism recently achieves impressive advancement in Natural Language Processing (NLP) and Image Processing domains. And its permutation invariance property makes it ideally suitable for point cloud processing. Inspired by this remarkable success, we propose an end-to-end architecture, dubbed Cross-Level Cross-Scale Cross-Attention Network (CLCSCANet), for point cloud representation learning. First, a point-wise feature pyramid module is introduced to hierarchically extract features from different scales or resolutions. Then a cross-level cross-attention is designed to model long-range inter-level and intra-level dependencies. Finally, we develop a cross-scale cross-attention module to capture interactions between-and-within scales for representation enhancement. Compared with state-of-the-art approaches, our network can obtain competitive performance on challenging 3D object classification, point cloud segmentation tasks via comprehensive experimental evaluation.
Dual Transformer for Point Cloud Analysis
Apr 27, 2021
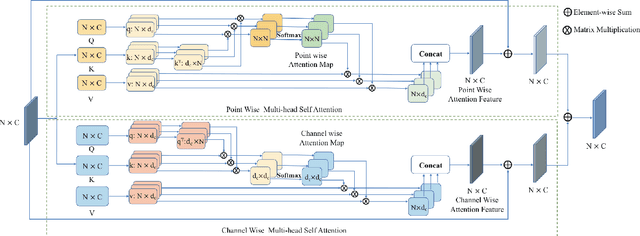
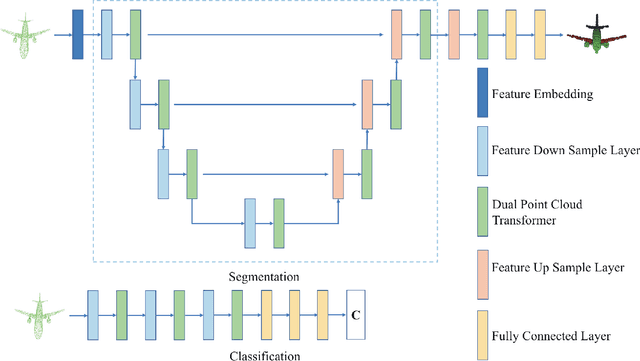

Following the tremendous success of transformer in natural language processing and image understanding tasks, in this paper, we present a novel point cloud representation learning architecture, named Dual Transformer Network (DTNet), which mainly consists of Dual Point Cloud Transformer (DPCT) module. Specifically, by aggregating the well-designed point-wise and channel-wise multi-head self-attention models simultaneously, DPCT module can capture much richer contextual dependencies semantically from the perspective of position and channel. With the DPCT module as a fundamental component, we construct the DTNet for performing point cloud analysis in an end-to-end manner. Extensive quantitative and qualitative experiments on publicly available benchmarks demonstrate the effectiveness of our proposed transformer framework for the tasks of 3D point cloud classification and segmentation, achieving highly competitive performance in comparison with the state-of-the-art approaches.
Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era
Jun 18, 2019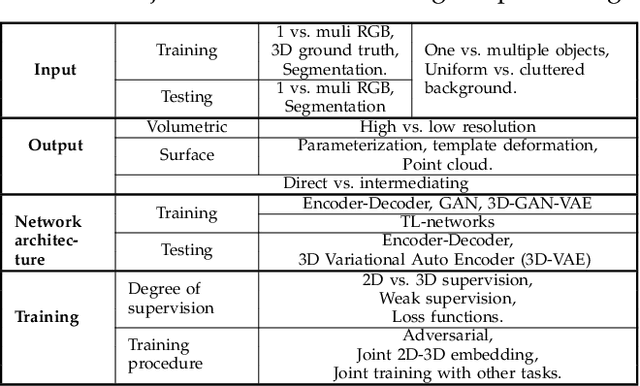
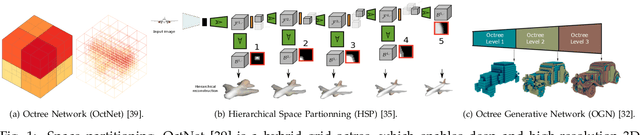

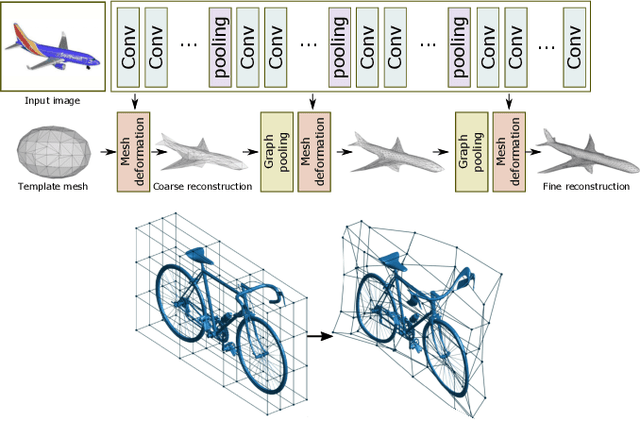
3D reconstruction is a longstanding ill-posed problem, which has been explored for decades by the computer vision, computer graphics, and machine learning communities. Since 2015, image-based 3D reconstruction using convolutional neural networks (CNN) has attracted increasing interest and demonstrated an impressive performance. Given this new era of rapid evolution, this article provides a comprehensive survey of the recent developments in this field. We focus on the works which use deep learning techniques to estimate the 3D shape of generic objects either from a single or multiple RGB images. We organize the literature based on the shape representations, the network architectures, and the training mechanisms they use. While this survey is intended for methods which reconstruct generic objects, we also review some of the recent works which focus on specific object classes such as human body shapes and faces. We provide an analysis and comparison of the performance of some key papers, summarize some of the open problems in this field, and discuss promising directions for future research.