 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCENet: Toward Concise and Efficient LiDAR Semantic Segmentation for Autonomous Driving
Jul 26, 2022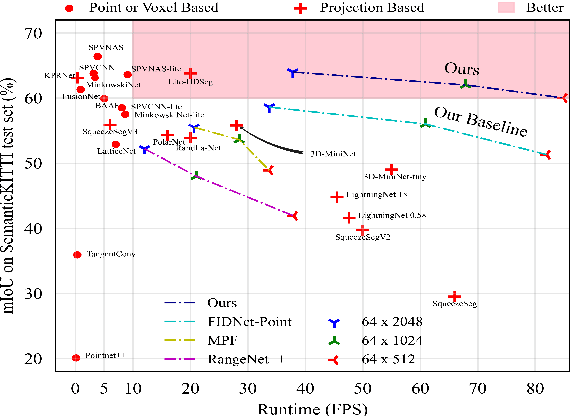
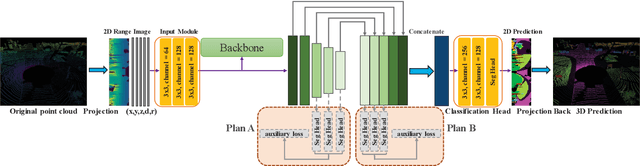
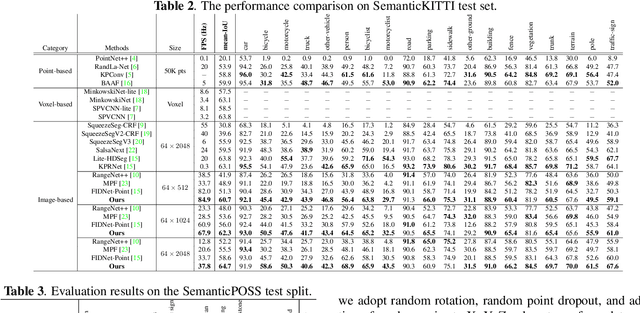

Accurate and fast scene understanding is one of the challenging task for autonomous driving, which requires to take full advantage of LiDAR point clouds for semantic segmentation. In this paper, we present a \textbf{concise} and \textbf{efficient} image-based semantic segmentation network, named \textbf{CENet}. In order to improve the descriptive power of learned features and reduce the computational as well as time complexity, our CENet integrates the convolution with larger kernel size instead of MLP, carefully-selected activation functions, and multiple auxiliary segmentation heads with corresponding loss functions into architecture. Quantitative and qualitative experiments conducted on publicly available benchmarks, SemanticKITTI and SemanticPOSS, demonstrate that our pipeline achieves much better mIoU and inference performance compared with state-of-the-art models. The code will be available at https://github.com/huixiancheng/CENet.
Dual Transformer for Point Cloud Analysis
Apr 27, 2021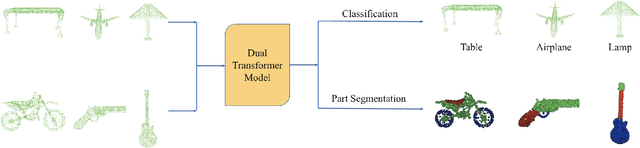
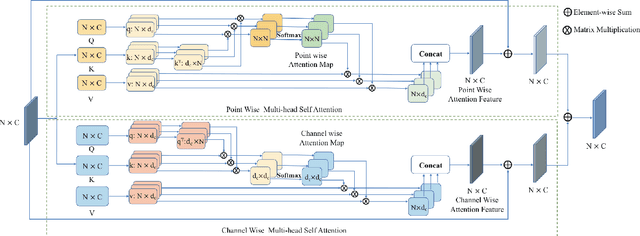
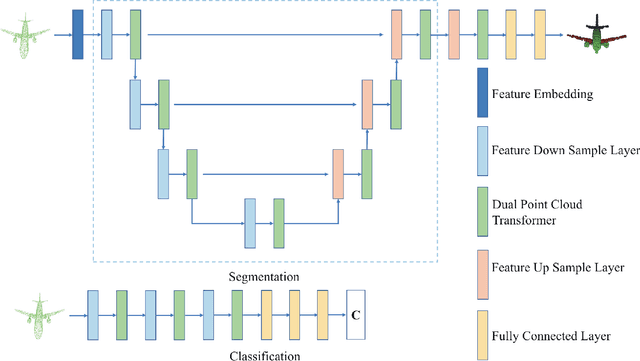

Following the tremendous success of transformer in natural language processing and image understanding tasks, in this paper, we present a novel point cloud representation learning architecture, named Dual Transformer Network (DTNet), which mainly consists of Dual Point Cloud Transformer (DPCT) module. Specifically, by aggregating the well-designed point-wise and channel-wise multi-head self-attention models simultaneously, DPCT module can capture much richer contextual dependencies semantically from the perspective of position and channel. With the DPCT module as a fundamental component, we construct the DTNet for performing point cloud analysis in an end-to-end manner. Extensive quantitative and qualitative experiments on publicly available benchmarks demonstrate the effectiveness of our proposed transformer framework for the tasks of 3D point cloud classification and segmentation, achieving highly competitive performance in comparison with the state-of-the-art approaches.