 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Images with at most one Spike per Neuron
Jan 21, 2020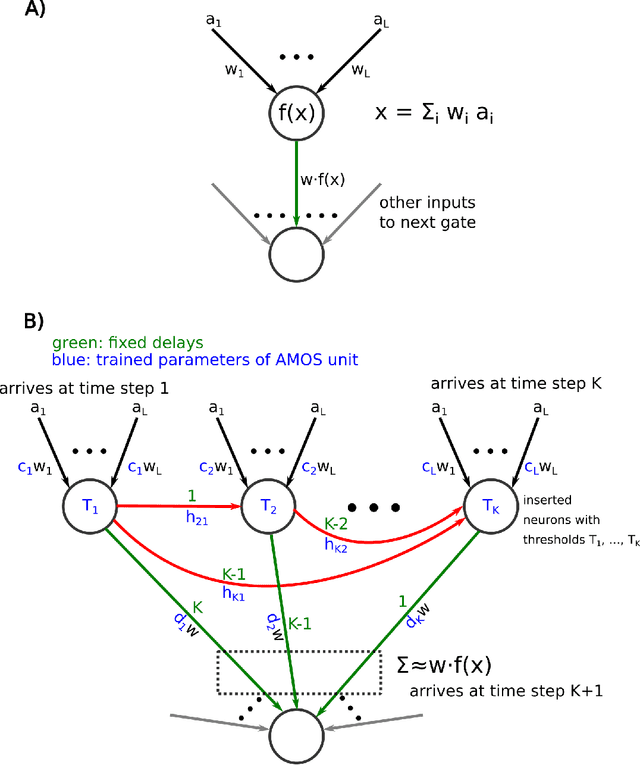

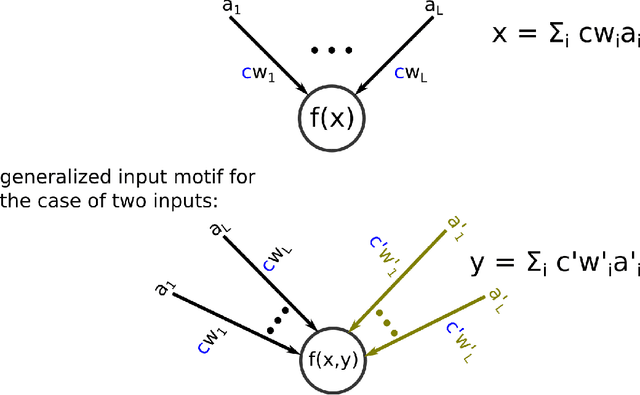

In order to port the performance of trained artificial neural networks (ANNs) to spiking neural networks (SNNs), which can be implemented in neuromorphic hardware with a drastically reduced energy consumption, an efficient ANN to SNN conversion is needed. Previous conversion schemes focused on the representation of the analog output of a rectified linear (ReLU) gate in the ANN by the firing rate of a spiking neuron. But this is not possible for other commonly used ANN gates, and it reduces the throughput even for ReLU gates. We introduce a new conversion method where a gate in the ANN, which can basically be of any type, is emulated by a small circuit of spiking neurons, with At Most One Spike (AMOS) per neuron. We show that this AMOS conversion improves the accuracy of SNNs for ImageNet from 74.60% to 80.97%, thereby bringing it within reach of the best available ANN accuracy (85.0%). The Top5 accuracy of SNNs is raised to 95.82%, getting even closer to the best Top5 performance of 97.2% for ANNs. In addition, AMOS conversion improves latency and throughput of spike-based image classification by several orders of magnitude. Hence these results suggest that SNNs provide a viable direction for developing highly energy efficient hardware for AI that combines high performance with versatility of applications.
Reservoirs learn to learn
Sep 30, 2019



We consider reservoirs in the form of liquid state machines, i.e., recurrently connected networks of spiking neurons with randomly chosen weights. So far only the weights of a linear readout were adapted for a specific task. We wondered whether the performance of liquid state machines can be improved if the recurrent weights are chosen with a purpose, rather than randomly. After all, weights of recurrent connections in the brain are also not assumed to be randomly chosen. Rather, these weights were probably optimized during evolution, development, and prior learning experiences for specific task domains. In order to examine the benefits of choosing recurrent weights within a liquid with a purpose, we applied the Learning-to-Learn (L2L) paradigm to our model: We optimized the weights of the recurrent connections -- and hence the dynamics of the liquid state machine -- for a large family of potential learning tasks, which the network might have to learn later through modification of the weights of readout neurons. We found that this two-tiered process substantially improves the learning speed of liquid state machines for specific tasks. In fact, this learning speed increases further if one does not train the weights of linear readouts at all, and relies instead on the internal dynamics and fading memory of the network for remembering salient information that it could extract from preceding examples for the current learning task. This second type of learning has recently been proposed to underlie fast learning in the prefrontal cortex and motor cortex, and hence it is of interest to explore its performance also in models. Since liquid state machines share many properties with other types of reservoirs, our results raise the question whether L2L conveys similar benefits also to these other reservoirs.
Efficient Reward-Based Structural Plasticity on a SpiNNaker 2 Prototype
Mar 20, 2019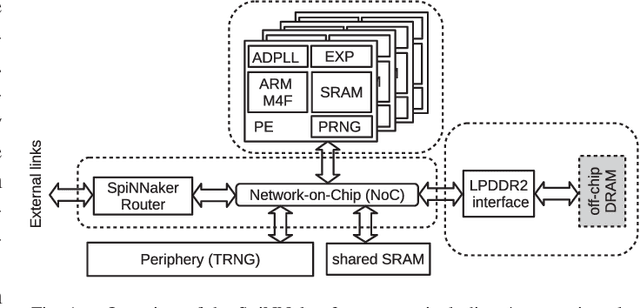
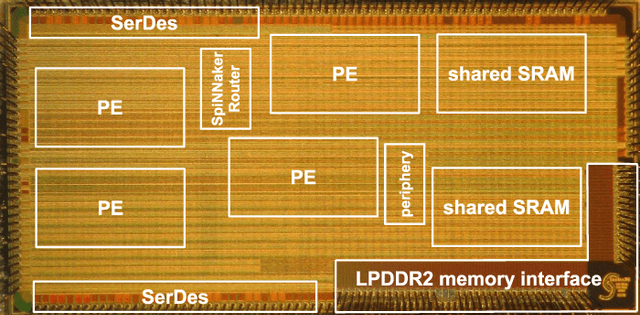
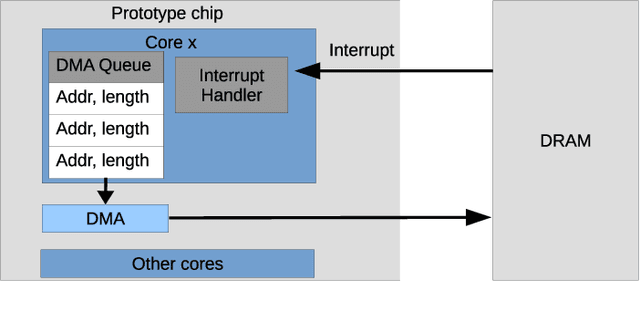
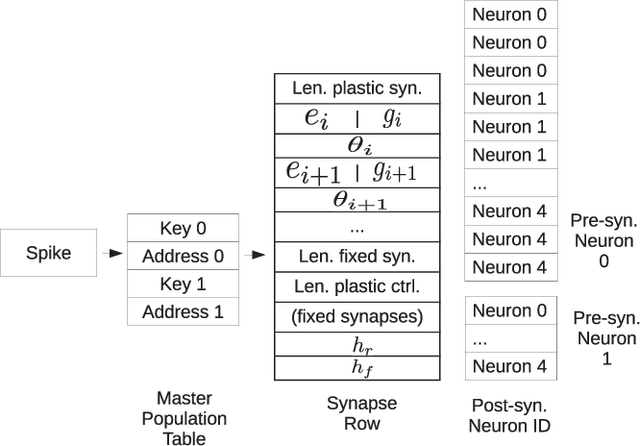
Advances in neuroscience uncover the mechanisms employed by the brain to efficiently solve complex learning tasks with very limited resources. However, the efficiency is often lost when one tries to port these findings to a silicon substrate, since brain-inspired algorithms often make extensive use of complex functions such as random number generators, that are expensive to compute on standard general purpose hardware. The prototype chip of the 2nd generation SpiNNaker system is designed to overcome this problem. Low-power ARM processors equipped with a random number generator and an exponential function accelerator enable the efficient execution of brain-inspired algorithms. We implement the recently introduced reward-based synaptic sampling model that employs structural plasticity to learn a function or task. The numerical simulation of the model requires to update the synapse variables in each time step including an explorative random term. To the best of our knowledge, this is the most complex synapse model implemented so far on the SpiNNaker system. By making efficient use of the hardware accelerators and numerical optimizations the computation time of one plasticity update is reduced by a factor of 2. This, combined with fitting the model into to the local SRAM, leads to 62% energy reduction compared to the case without accelerators and the use of external DRAM. The model implementation is integrated into the SpiNNaker software framework allowing for scalability onto larger systems. The hardware-software system presented in this work paves the way for power-efficient mobile and biomedical applications with biologically plausible brain-inspired algorithms.
Neuromorphic Hardware learns to learn
Mar 18, 2019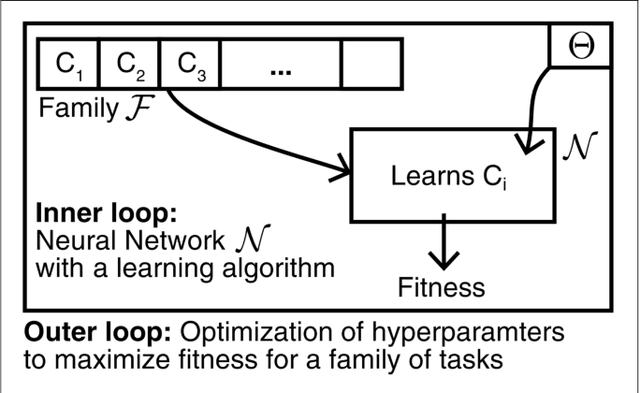

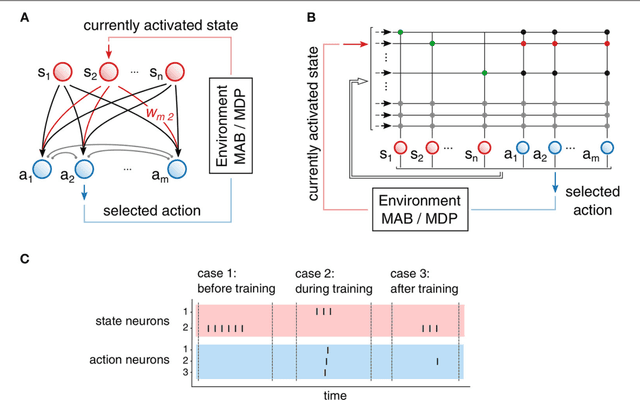
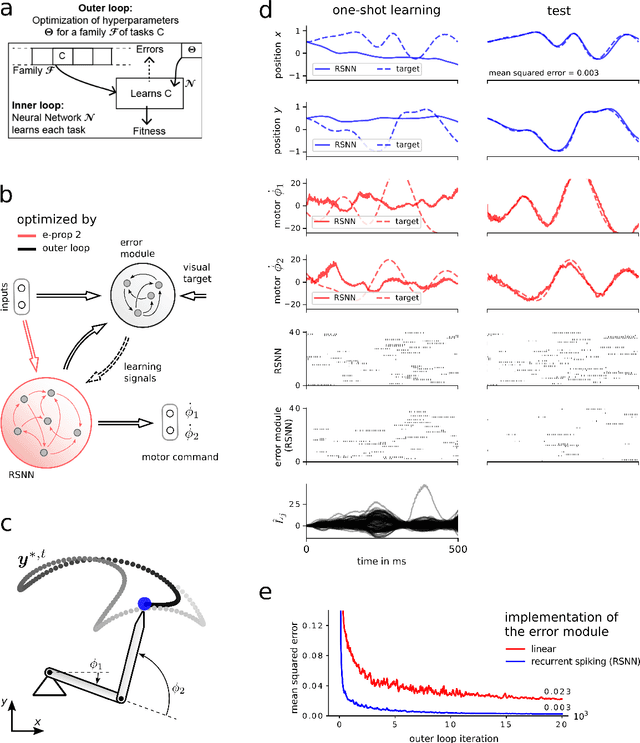
Hyperparameters and learning algorithms for neuromorphic hardware are usually chosen by hand. In contrast, the hyperparameters and learning algorithms of networks of neurons in the brain, which they aim to emulate, have been optimized through extensive evolutionary and developmental processes for specific ranges of computing and learning tasks. Occasionally this process has been emulated through genetic algorithms, but these require themselves hand-design of their details and tend to provide a limited range of improvements. We employ instead other powerful gradient-free optimization tools, such as cross-entropy methods and evolutionary strategies, in order to port the function of biological optimization processes to neuromorphic hardware. As an example, we show that this method produces neuromorphic agents that learn very efficiently from rewards. In particular, meta-plasticity, i.e., the optimization of the learning rule which they use, substantially enhances reward-based learning capability of the hardware. In addition, we demonstrate for the first time Learning-to-Learn benefits from such hardware, in particular, the capability to extract abstract knowledge from prior learning experiences that speeds up the learning of new but related tasks. Learning-to-Learn is especially suited for accelerated neuromorphic hardware, since it makes it feasible to carry out the required very large number of network computations.
Biologically inspired alternatives to backpropagation through time for learning in recurrent neural nets
Jan 25, 2019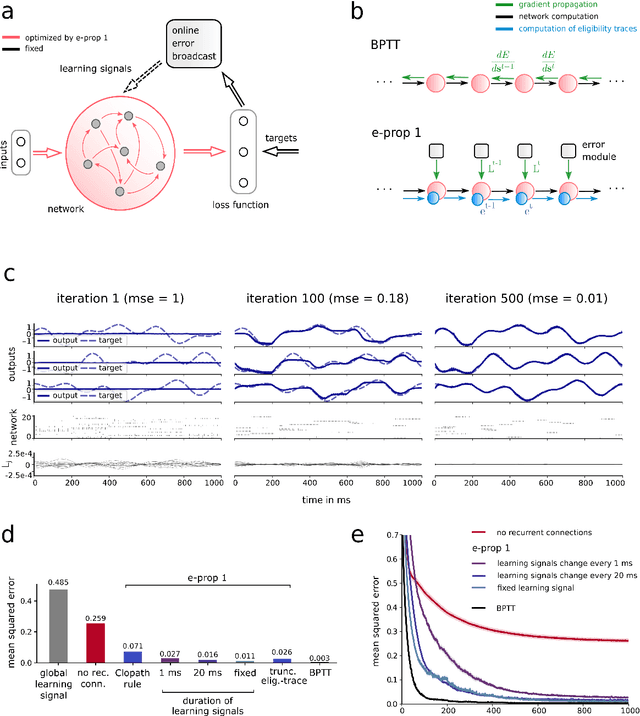
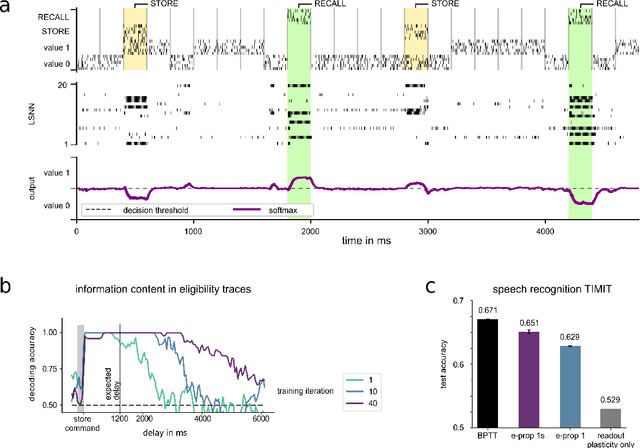
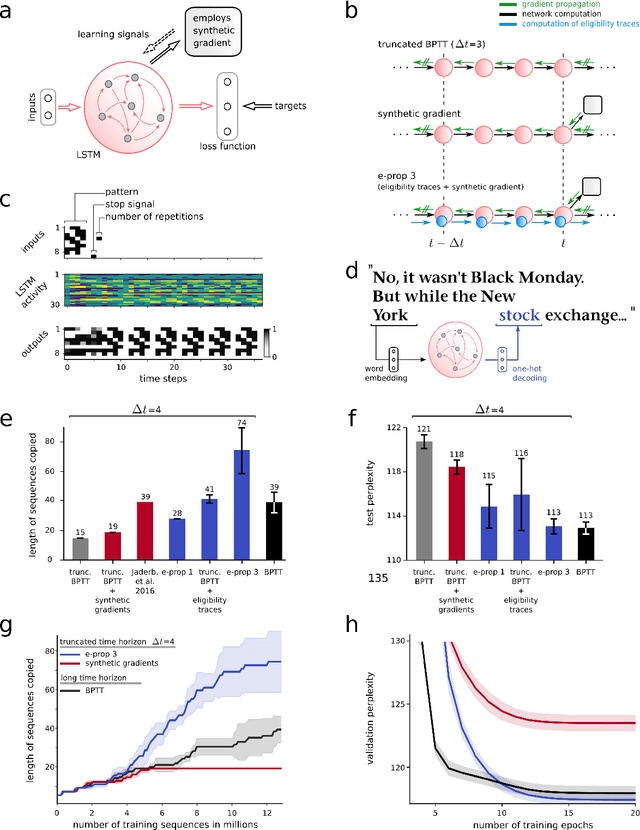
The way how recurrently connected networks of spiking neurons in the brain acquire powerful information processing capabilities through learning has remained a mystery. This lack of understanding is linked to a lack of learning algorithms for recurrent networks of spiking neurons (RSNNs) that are both functionally powerful and can be implemented by known biological mechanisms. Since RSNNs are simultaneously a primary target for implementations of brain-inspired circuits in neuromorphic hardware, this lack of algorithmic insight also hinders technological progress in that area. The gold standard for learning in recurrent neural networks in machine learning is back-propagation through time (BPTT), which implements stochastic gradient descent with regard to a given loss function. But BPTT is unrealistic from a biological perspective, since it requires a transmission of error signals backwards in time and in space, i.e., from post- to presynaptic neurons. We show that an online merging of locally available information during a computation with suitable top-down learning signals in real-time provides highly capable approximations to BPTT. For tasks where information on errors arises only late during a network computation, we enrich locally available information through feedforward eligibility traces of synapses that can easily be computed in an online manner. The resulting new generation of learning algorithms for recurrent neural networks provides a new understanding of network learning in the brain that can be tested experimentally. In addition, these algorithms provide efficient methods for on-chip training of RSNNs in neuromorphic hardware.
Long short-term memory and learning-to-learn in networks of spiking neurons
Nov 02, 2018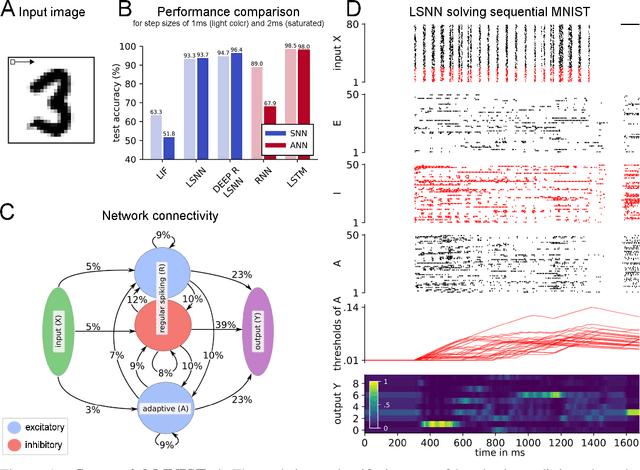
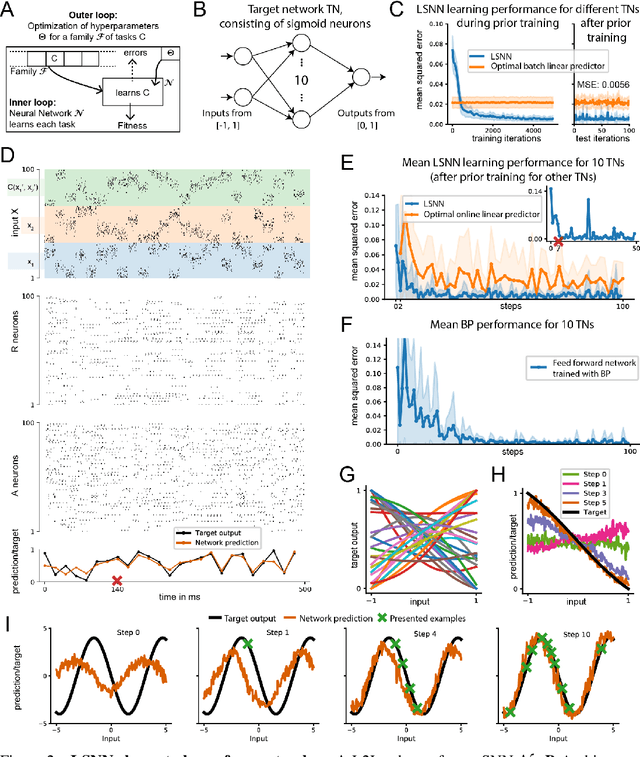
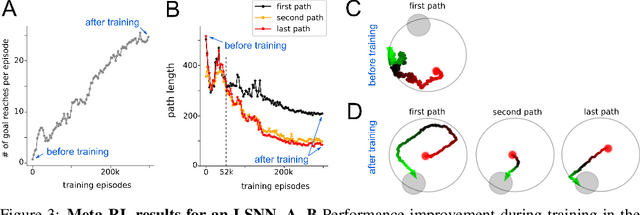
Recurrent networks of spiking neurons (RSNNs) underlie the astounding computing and learning capabilities of the brain. But computing and learning capabilities of RSNN models have remained poor, at least in comparison with ANNs. We address two possible reasons for that. One is that RSNNs in the brain are not randomly connected or designed according to simple rules, and they do not start learning as a tabula rasa network. Rather, RSNNs in the brain were optimized for their tasks through evolution, development, and prior experience. Details of these optimization processes are largely unknown. But their functional contribution can be approximated through powerful optimization methods, such as backpropagation through time (BPTT). A second major mismatch between RSNNs in the brain and models is that the latter only show a small fraction of the dynamics of neurons and synapses in the brain. We include neurons in our RSNN model that reproduce one prominent dynamical process of biological neurons that takes place at the behaviourally relevant time scale of seconds: neuronal adaptation. We denote these networks as LSNNs because of their Long short-term memory. The inclusion of adapting neurons drastically increases the computing and learning capability of RSNNs if they are trained and configured by deep learning (BPTT combined with a rewiring algorithm that optimizes the network architecture). In fact, the computational performance of these RSNNs approaches for the first time that of LSTM networks. In addition RSNNs with adapting neurons can acquire abstract knowledge from prior learning in a Learning-to-Learn (L2L) scheme, and transfer that knowledge in order to learn new but related tasks from very few examples. We demonstrate this for supervised learning and reinforcement learning.
Smoothed Analysis of Discrete Tensor Decomposition and Assemblies of Neurons
Oct 28, 2018We analyze linear independence of rank one tensors produced by tensor powers of randomly perturbed vectors. This enables efficient decomposition of sums of high-order tensors. Our analysis builds upon [BCMV14] but allows for a wider range of perturbation models, including discrete ones. We give an application to recovering assemblies of neurons. Assemblies are large sets of neurons representing specific memories or concepts. The size of the intersection of two assemblies has been shown in experiments to represent the extent to which these memories co-occur or these concepts are related; the phenomenon is called association of assemblies. This suggests that an animal's memory is a complex web of associations, and poses the problem of recovering this representation from cognitive data. Motivated by this problem, we study the following more general question: Can we reconstruct the Venn diagram of a family of sets, given the sizes of their $\ell$-wise intersections? We show that as long as the family of sets is randomly perturbed, it is enough for the number of measurements to be polynomially larger than the number of nonempty regions of the Venn diagram to fully reconstruct the diagram.
Deep Rewiring: Training very sparse deep networks
Aug 07, 2018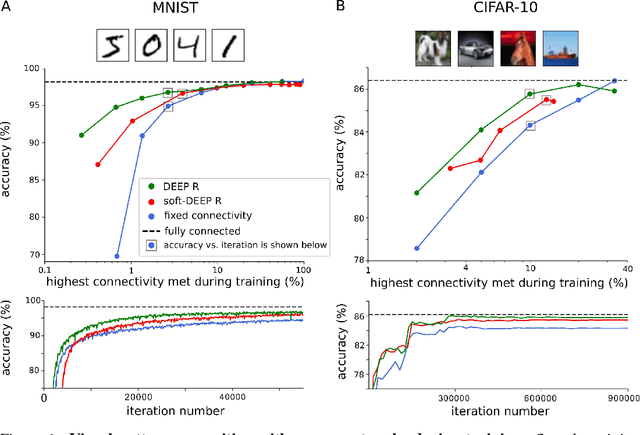
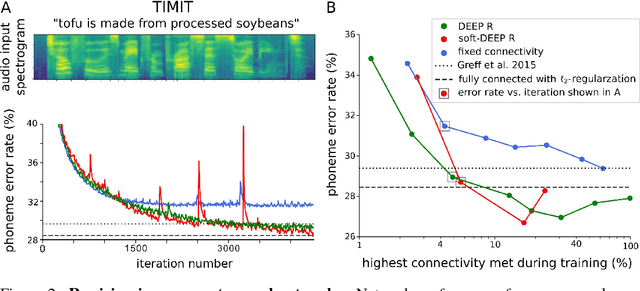
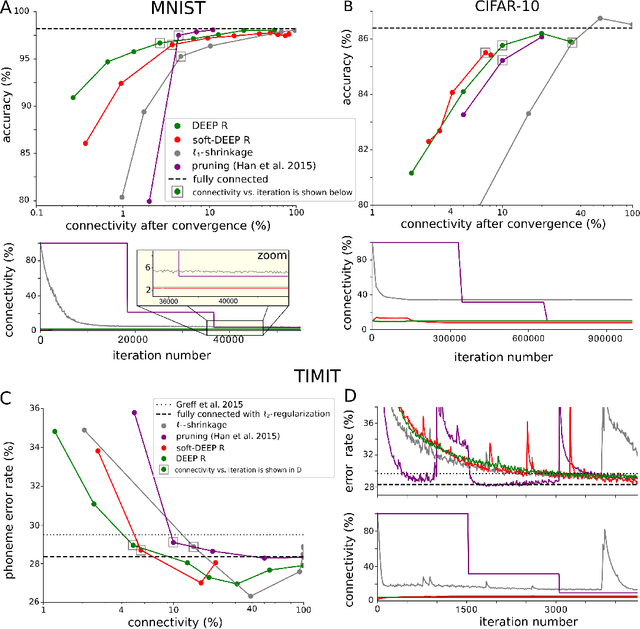
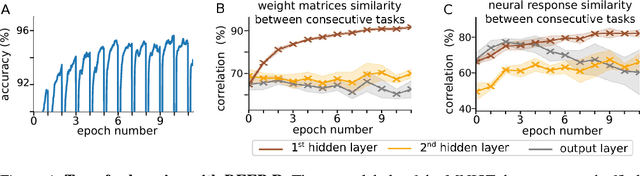
Neuromorphic hardware tends to pose limits on the connectivity of deep networks that one can run on them. But also generic hardware and software implementations of deep learning run more efficiently for sparse networks. Several methods exist for pruning connections of a neural network after it was trained without connectivity constraints. We present an algorithm, DEEP R, that enables us to train directly a sparsely connected neural network. DEEP R automatically rewires the network during supervised training so that connections are there where they are most needed for the task, while its total number is all the time strictly bounded. We demonstrate that DEEP R can be used to train very sparse feedforward and recurrent neural networks on standard benchmark tasks with just a minor loss in performance. DEEP R is based on a rigorous theoretical foundation that views rewiring as stochastic sampling of network configurations from a posterior.
CaMKII activation supports reward-based neural network optimization through Hamiltonian sampling
May 15, 2018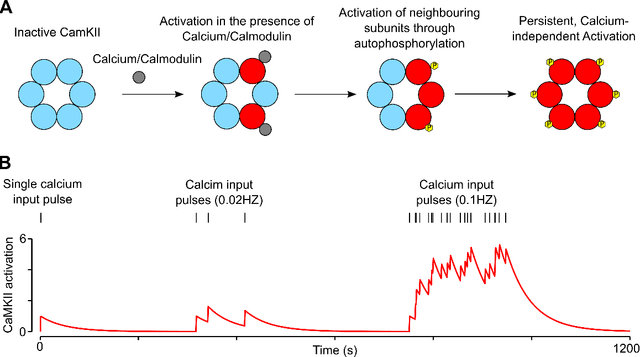
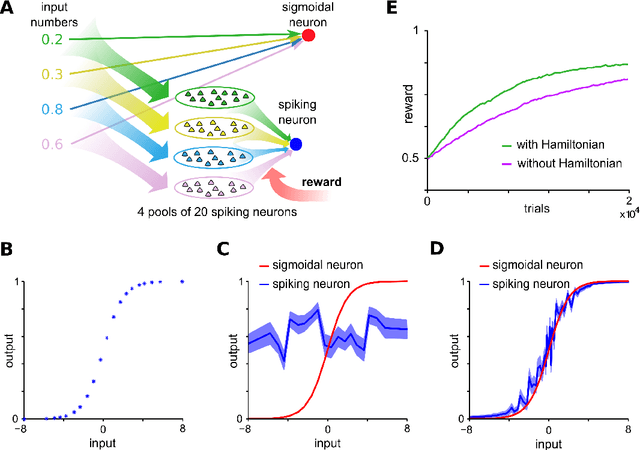
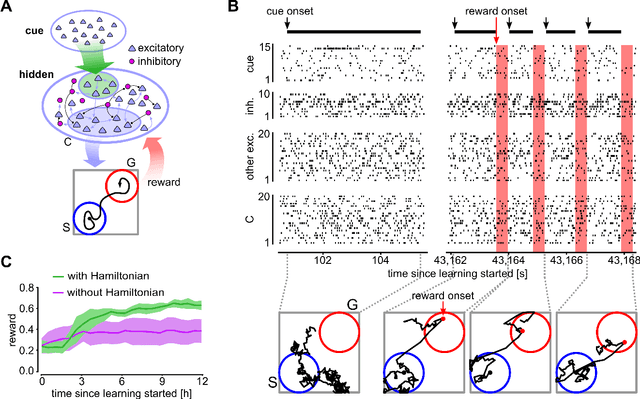
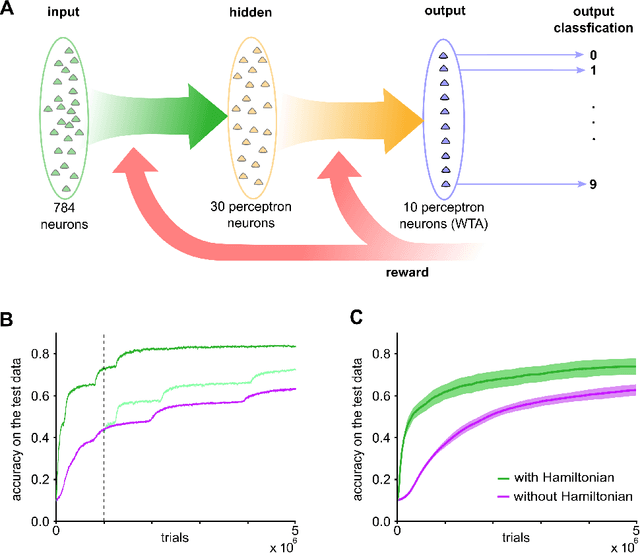
Synaptic plasticity is implemented and controlled through over thousand different types of molecules in the postsynaptic density and presynaptic boutons that assume a staggering array of different states through phosporylation and other mechanisms. One of the most prominent molecule in the postsynaptic density is CaMKII, that is described in molecular biology as a "memory molecule" that can integrate through auto-phosporylation Ca-influx signals on a relatively large time scale of dozens of seconds. The functional impact of this memory mechanism is largely unknown. We show that the experimental data on the specific role of CaMKII activation in dopamine-gated spine consolidation suggest a general functional role in speeding up reward-guided search for network configurations that maximize reward expectation. Our theoretical analysis shows that stochastic search could in principle even attain optimal network configurations by emulating one of the most well-known nonlinear optimization methods, simulated annealing. But this optimization is usually impeded by slowness of stochastic search at a given temperature. We propose that CaMKII contributes a momentum term that substantially speeds up this search. In particular, it allows the network to overcome saddle points of the fitness function. The resulting improved stochastic policy search can be understood on a more abstract level as Hamiltonian sampling, which is known to be one of the most efficient stochastic search methods.
A dynamic connectome supports the emergence of stable computational function of neural circuits through reward-based learning
Jan 05, 2018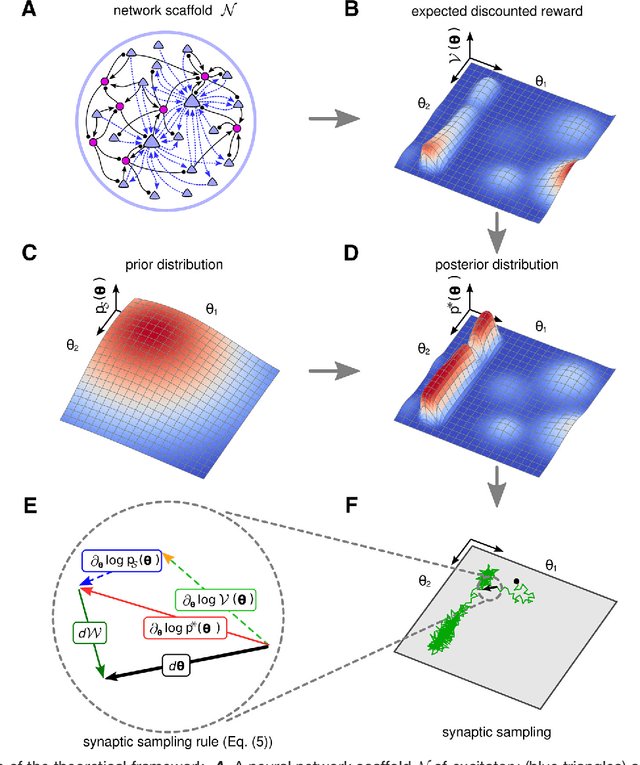

Synaptic connections between neurons in the brain are dynamic because of continuously ongoing spine dynamics, axonal sprouting, and other processes. In fact, it was recently shown that the spontaneous synapse-autonomous component of spine dynamics is at least as large as the component that depends on the history of pre- and postsynaptic neural activity. These data are inconsistent with common models for network plasticity, and raise the questions how neural circuits can maintain a stable computational function in spite of these continuously ongoing processes, and what functional uses these ongoing processes might have. Here, we present a rigorous theoretical framework for these seemingly stochastic spine dynamics and rewiring processes in the context of reward-based learning tasks. We show that spontaneous synapse-autonomous processes, in combination with reward signals such as dopamine, can explain the capability of networks of neurons in the brain to configure themselves for specific computational tasks, and to compensate automatically for later changes in the network or task. Furthermore we show theoretically and through computer simulations that stable computational performance is compatible with continuously ongoing synapse-autonomous changes. After reaching good computational performance it causes primarily a slow drift of network architecture and dynamics in task-irrelevant dimensions, as observed for neural activity in motor cortex and other areas. On the more abstract level of reinforcement learning the resulting model gives rise to an understanding of reward-driven network plasticity as continuous sampling of network configurations.