 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDithered backprop: A sparse and quantized backpropagation algorithm for more efficient deep neural network training
Apr 16, 2020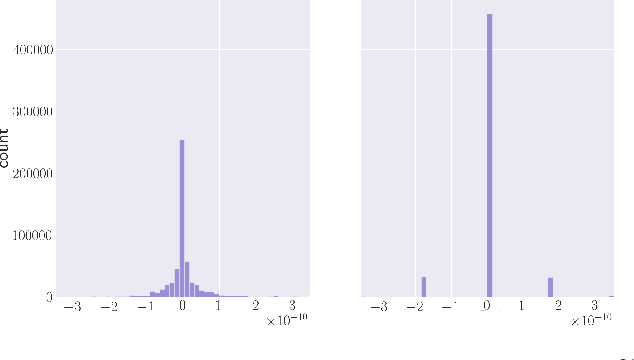
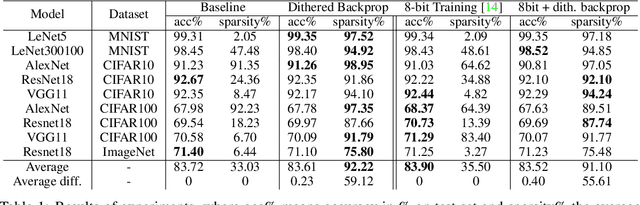
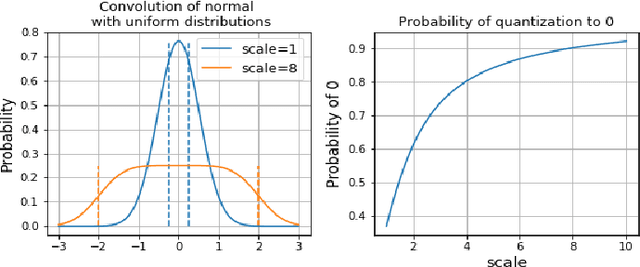
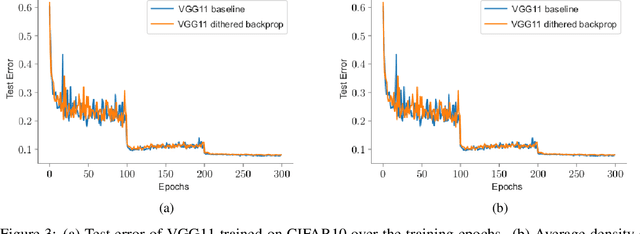
Deep Neural Networks are successful but highly computationally expensive learning systems. One of the main sources of time and energy drains is the well known backpropagation (backprop) algorithm, which roughly accounts for 2/3 of the computational complexity of training. In this work we propose a method for reducing the computational cost of backprop, which we named dithered backprop. It consists in applying a stochastic quantization scheme to intermediate results of the method. The particular quantisation scheme, called non-subtractive dither (NSD), induces sparsity which can be exploited by computing efficient sparse matrix multiplications. Experiments on popular image classification tasks show that it induces 92% sparsity on average across a wide set of models at no or negligible accuracy drop in comparison to state-of-the-art approaches, thus significantly reducing the computational complexity of the backward pass. Moreover, we show that our method is fully compatible to state-of-the-art training methods that reduce the bit-precision of training down to 8-bits, as such being able to further reduce the computational requirements. Finally we discuss and show potential benefits of applying dithered backprop in a distributed training setting, where both communication as well as compute efficiency may increase simultaneously with the number of participant nodes.
Learning Sparse & Ternary Neural Networks with Entropy-Constrained Trained Ternarization (EC2T)
Apr 02, 2020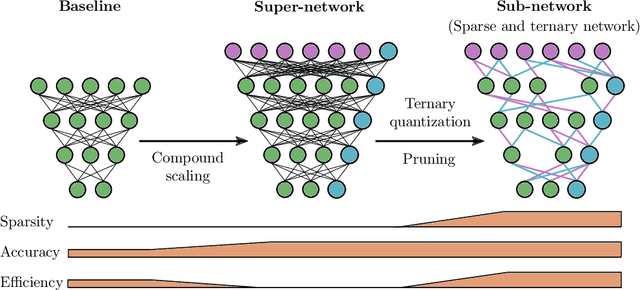
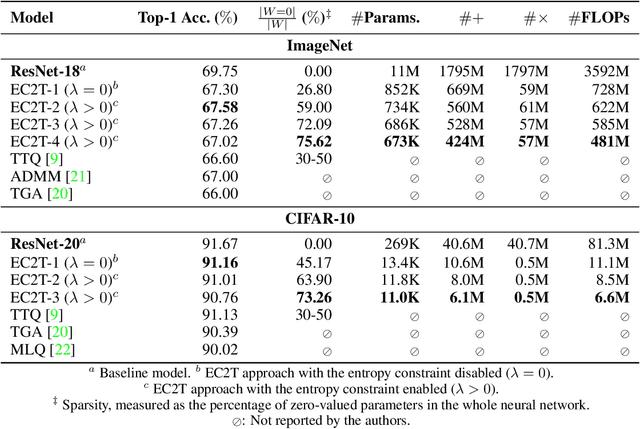
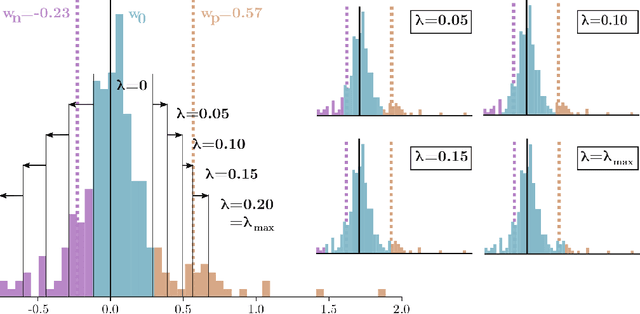
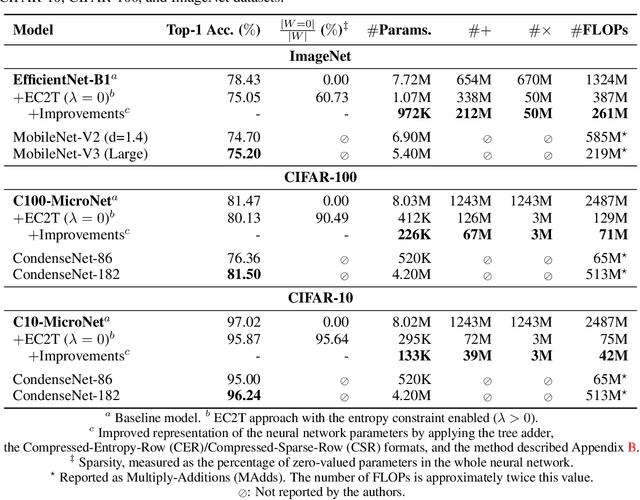
Deep neural networks (DNN) have shown remarkable success in a variety of machine learning applications. The capacity of these models (i.e., number of parameters), endows them with expressive power and allows them to reach the desired performance. In recent years, there is an increasing interest in deploying DNNs to resource-constrained devices (i.e., mobile devices) with limited energy, memory, and computational budget. To address this problem, we propose Entropy-Constrained Trained Ternarization (EC2T), a general framework to create sparse and ternary neural networks which are efficient in terms of storage (e.g., at most two binary-masks and two full-precision values are required to save a weight matrix) and computation (e.g., MAC operations are reduced to a few accumulations plus two multiplications). This approach consists of two steps. First, a super-network is created by scaling the dimensions of a pre-trained model (i.e., its width and depth). Subsequently, this super-network is simultaneously pruned (using an entropy constraint) and quantized (that is, ternary values are assigned layer-wise) in a training process, resulting in a sparse and ternary network representation. We validate the proposed approach in CIFAR-10, CIFAR-100, and ImageNet datasets, showing its effectiveness in image classification tasks.
Interval Neural Networks as Instability Detectors for Image Reconstructions
Mar 27, 2020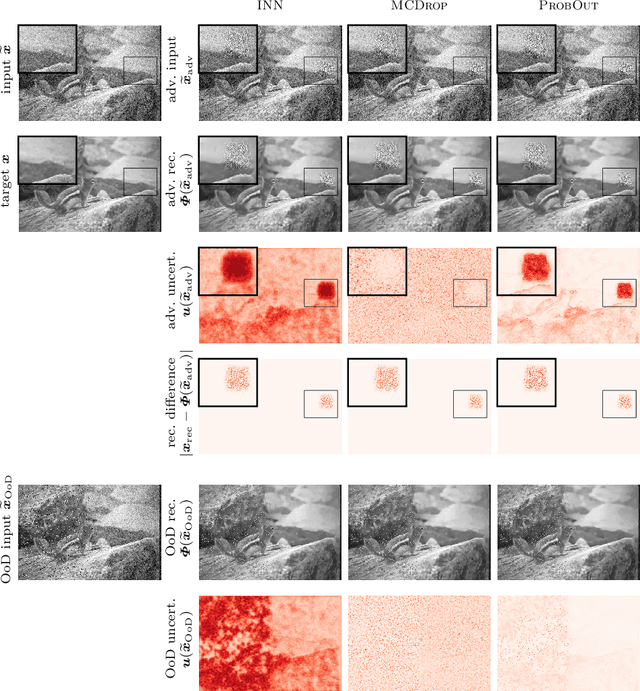
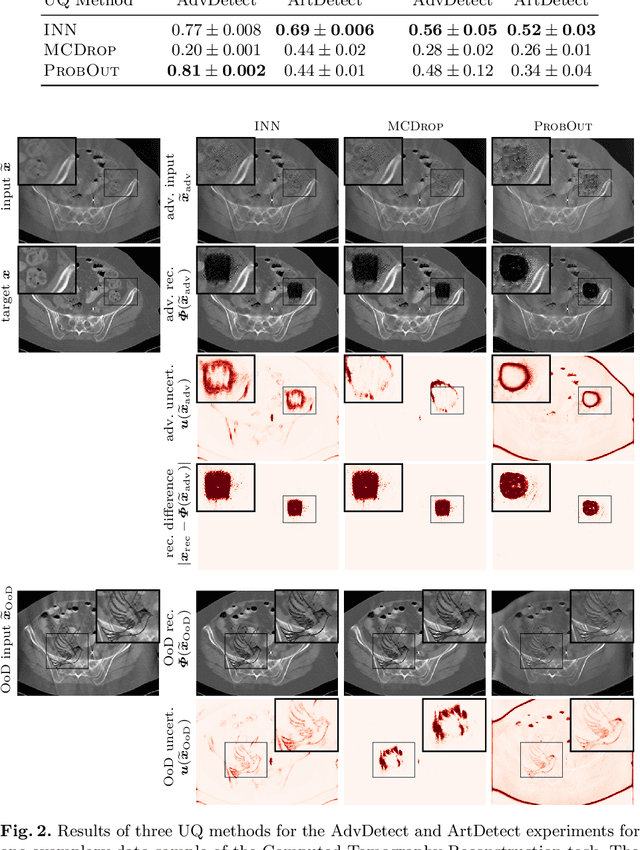
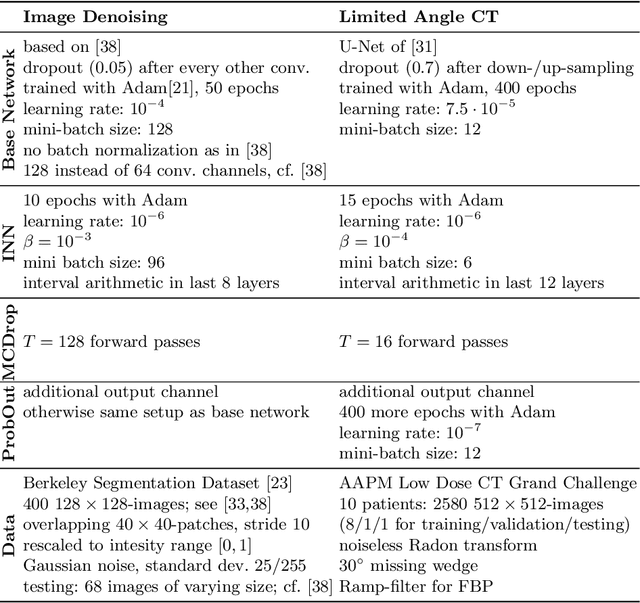
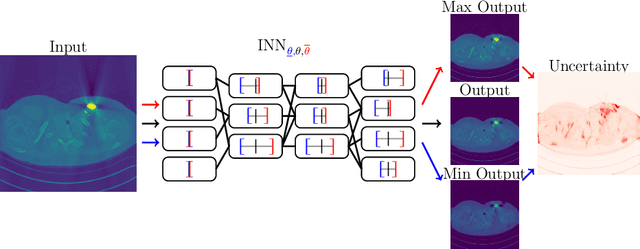
This work investigates the detection of instabilities that may occur when utilizing deep learning models for image reconstruction tasks. Although neural networks often empirically outperform traditional reconstruction methods, their usage for sensitive medical applications remains controversial. Indeed, in a recent series of works, it has been demonstrated that deep learning approaches are susceptible to various types of instabilities, caused for instance by adversarial noise or out-of-distribution features. It is argued that this phenomenon can be observed regardless of the underlying architecture and that there is no easy remedy. Based on this insight, the present work demonstrates on two use cases how uncertainty quantification methods can be employed as instability detectors. In particular, it is shown that the recently proposed Interval Neural Networks are highly effective in revealing instabilities of reconstructions. Such an ability is crucial to ensure a safe use of deep learning-based methods for medical image reconstruction.
Interval Neural Networks: Uncertainty Scores
Mar 25, 2020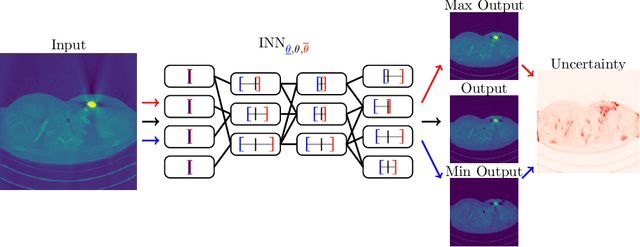
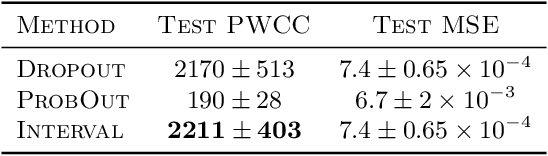
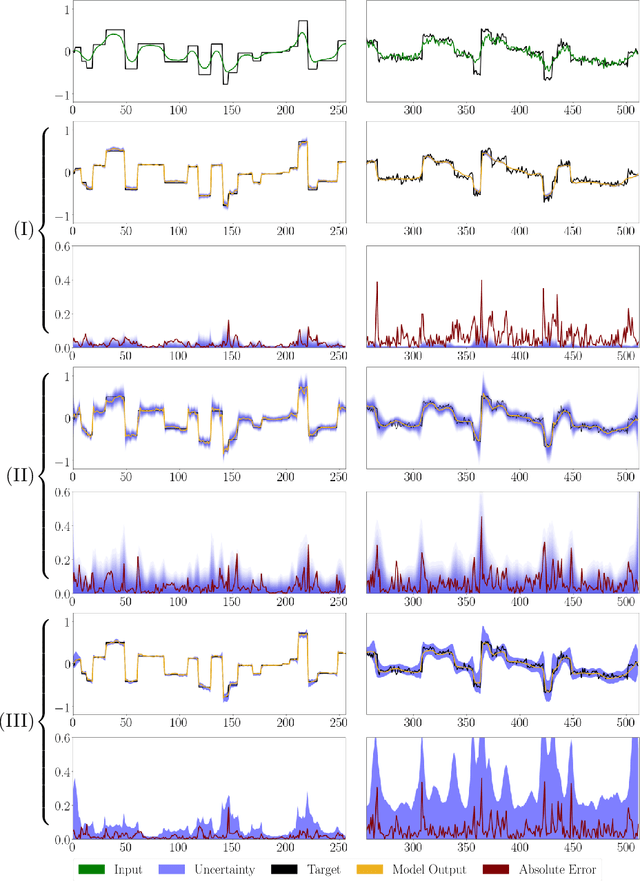
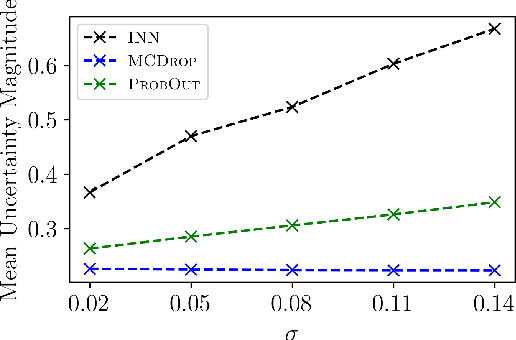
We propose a fast, non-Bayesian method for producing uncertainty scores in the output of pre-trained deep neural networks (DNNs) using a data-driven interval propagating network. This interval neural network (INN) has interval valued parameters and propagates its input using interval arithmetic. The INN produces sensible lower and upper bounds encompassing the ground truth. We provide theoretical justification for the validity of these bounds. Furthermore, its asymmetric uncertainty scores offer additional, directional information beyond what Gaussian-based, symmetric variance estimation can provide. We find that noise in the data is adequately captured by the intervals produced with our method. In numerical experiments on an image reconstruction task, we demonstrate the practical utility of INNs as a proxy for the prediction error in comparison to two state-of-the-art uncertainty quantification methods. In summary, INNs produce fast, theoretically justified uncertainty scores for DNNs that are easy to interpret, come with added information and pose as improved error proxies - features that may prove useful in advancing the usability of DNNs especially in sensitive applications such as health care.
Toward Interpretable Machine Learning: Transparent Deep Neural Networks and Beyond
Mar 17, 2020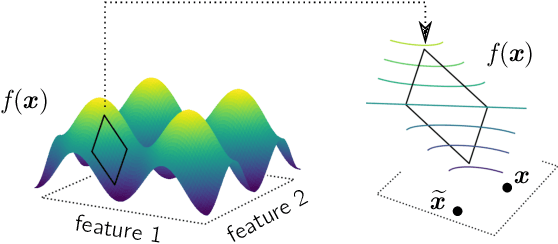
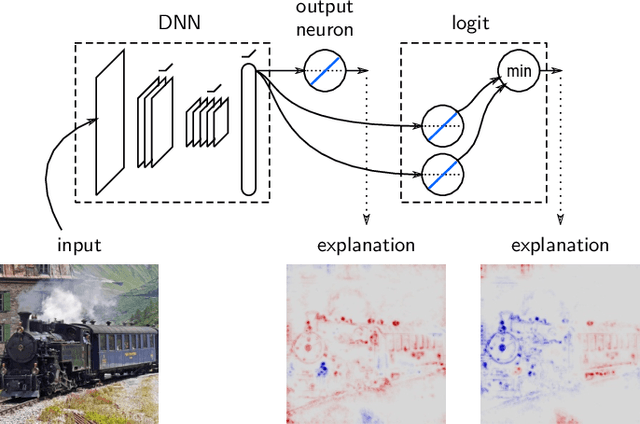
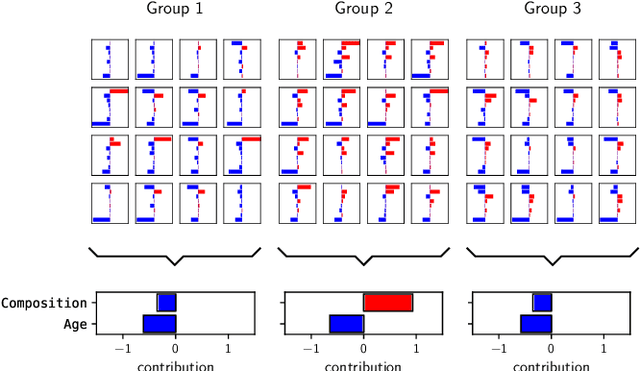
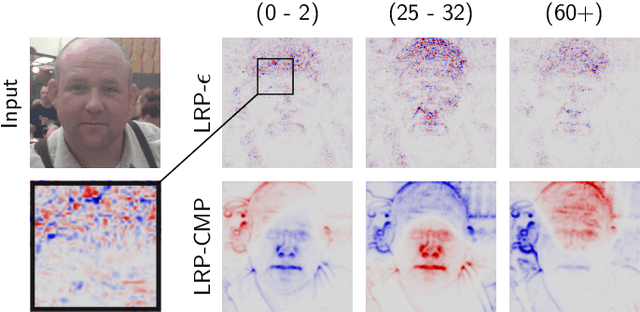
With the broader and highly successful usage of machine learning in industry and the sciences, there has been a growing demand for explainable AI. Interpretability and explanation methods for gaining a better understanding about the problem solving abilities and strategies of nonlinear Machine Learning such as Deep Learning (DL), LSTMs, and kernel methods are therefore receiving increased attention. In this work we aim to (1) provide a timely overview of this active emerging field and explain its theoretical foundations, (2) put interpretability algorithms to a test both from a theory and comparative evaluation perspective using extensive simulations, (3) outline best practice aspects i.e. how to best include interpretation methods into the standard usage of machine learning and (4) demonstrate successful usage of explainable AI in a representative selection of application scenarios. Finally, we discuss challenges and possible future directions of this exciting foundational field of machine learning.
Towards Ground Truth Evaluation of Visual Explanations
Mar 16, 2020
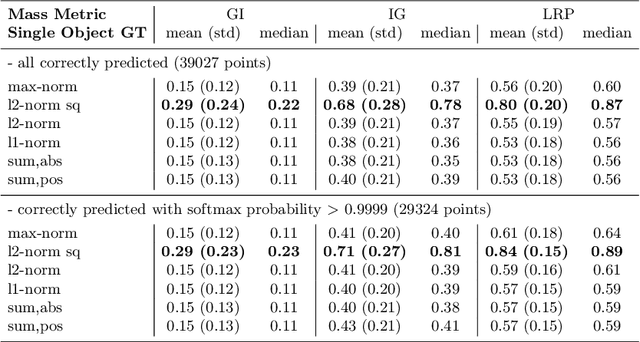
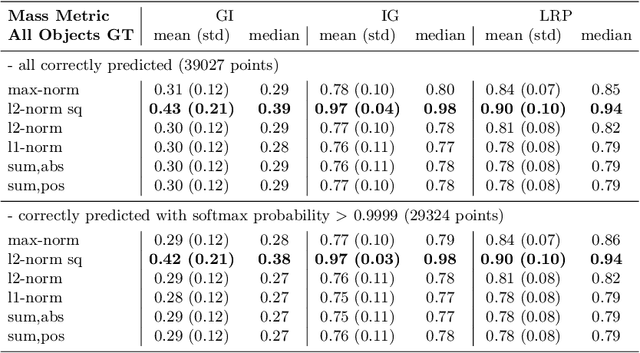
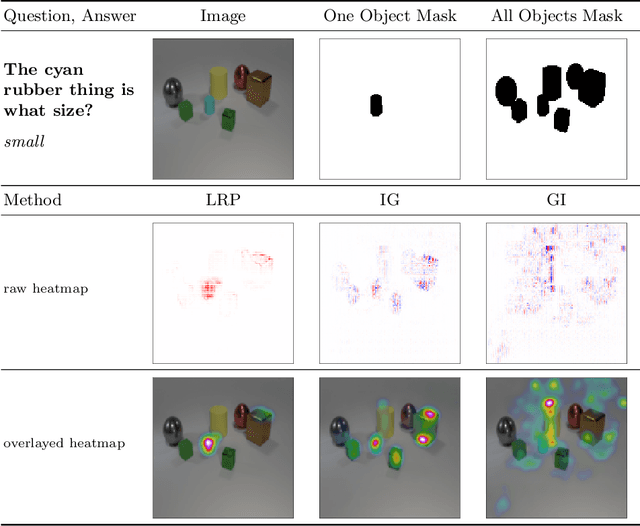
Several methods have been proposed to explain the decisions of neural networks in the visual domain via saliency heatmaps (aka relevances/feature importance scores). Thus far, these methods were mainly validated on real-world images, using either pixel perturbation experiments or bounding box localization accuracies. In the present work, we propose instead to evaluate explanations in a restricted and controlled setup using a synthetic dataset of rendered 3D shapes. To this end, we generate a CLEVR-alike visual question answering benchmark with around 40,000 questions, where the ground truth pixel coordinates of relevant objects are known, which allows us to validate explanations in a fair and transparent way. We further introduce two straightforward metrics to evaluate explanations in this setup, and compare their outcomes to standard pixel perturbation using a Relation Network model and three decomposition-based explanation methods: Gradient x Input, Integrated Gradients and Layer-wise Relevance Propagation. Among the tested methods, Layer-wise Relevance Propagation was shown to perform best, followed by Integrated Gradients. More generally, we expect the release of our dataset and code to support the development and comparison of methods on a well-defined common ground.
Trends and Advancements in Deep Neural Network Communication
Mar 06, 2020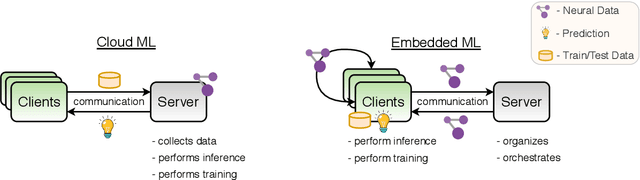
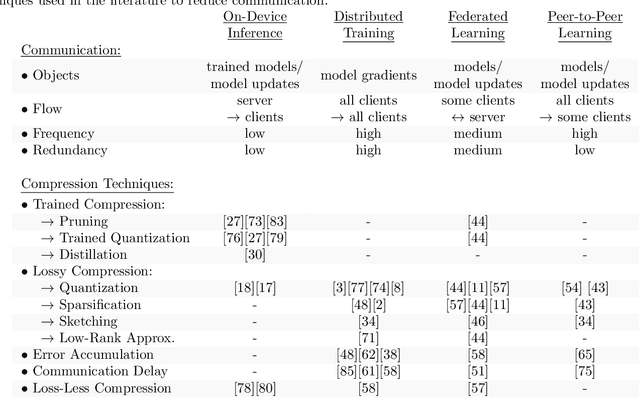
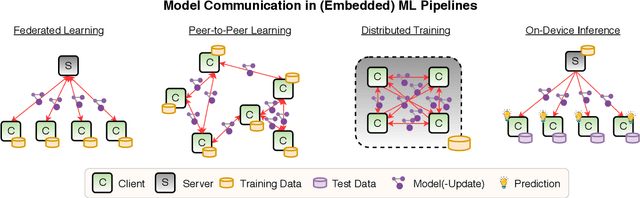
Due to their great performance and scalability properties neural networks have become ubiquitous building blocks of many applications. With the rise of mobile and IoT, these models now are also being increasingly applied in distributed settings, where the owners of the data are separated by limited communication channels and privacy constraints. To address the challenges of these distributed environments, a wide range of training and evaluation schemes have been developed, which require the communication of neural network parametrizations. These novel approaches, which bring the "intelligence to the data" have many advantages over traditional cloud solutions such as privacy-preservation, increased security and device autonomy, communication efficiency and high training speed. This paper gives an overview over the recent advancements and challenges in this new field of research at the intersection of machine learning and communications.
Understanding Image Captioning Models beyond Visualizing Attention
Jan 22, 2020

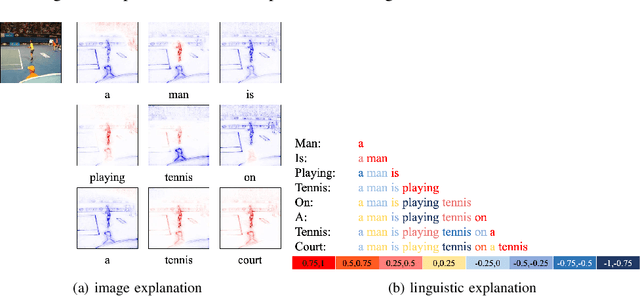
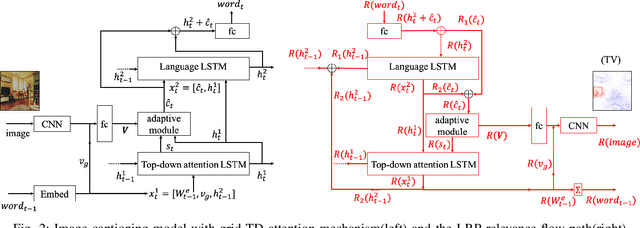
This paper explains predictions of image captioning models with attention mechanisms beyond visualizing the attention itself. In this paper, we develop variants of layer-wise relevance backpropagation (LRP) and gradient backpropagation, tailored to image captioning with attention. The result provides simultaneously pixel-wise image explanation and linguistic explanation for each word in the captions. We show that given a word in the caption to be explained, explanation methods such as LRP reveal supporting and opposing pixels as well as words. We compare the properties of attention heatmaps systematically against those computed with explanation methods such as LRP, Grad-CAM and Guided Grad-CAM. We show that explanation methods, firstly, correlate to object locations with higher precision than attention, secondly, are able to identify object words that are unsupported by image content, and thirdly, provide guidance to debias and improve the model. Results are reported for image captioning using two different attention models trained with Flickr30K and MSCOCO2017 datasets. Experimental analyses show the strength of explanation methods for understanding image captioning attention models.
Analyzing ImageNet with Spectral Relevance Analysis: Towards ImageNet un-Hans'ed
Dec 22, 2019
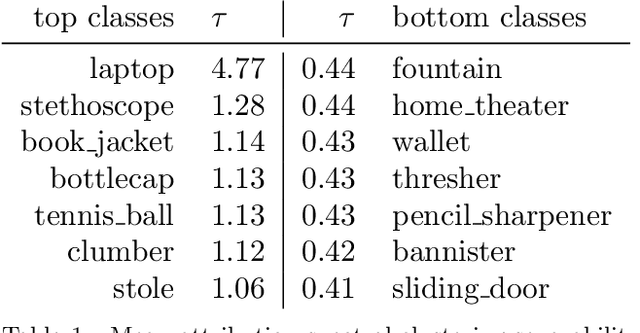

Today's machine learning models for computer vision are typically trained on very large (benchmark) data sets with millions of samples. These may, however, contain biases, artifacts, or errors that have gone unnoticed and are exploited by the model. In the worst case, the trained model may become a 'Clever Hans' predictor that does not learn a valid and generalizable strategy to solve the problem it was trained for, but bases its decisions on spurious correlations in the training data. Recently developed techniques allow to explain individual model decisions and thus to gain deeper insights into the model's prediction strategies. In this paper, we contribute by providing a comprehensive analysis framework based on a scalable statistical analysis of attributions from explanation methods for large data corpora, here ImageNet. Based on a recent technique - Spectral Relevance Analysis (SpRAy) - we propose three technical contributions and resulting findings: (a) novel similarity metrics based on Wasserstein for comparing attributions to allow for the first time scale, translational, and rotational invariant comparisons of attributions, (b) a scalable quantification of artifactual and poisoned classes where the ML models under study exhibit Clever Hans behavior, (c) a cleaning procedure that allows to relief data of artifacts and biases in a systematic manner yielding significantly reduced Clever Hans behavior, i.e. we un-Hans the ImageNet data corpus. Using this novel method set, we provide qualitative and quantitative analyses of the biases and artifacts in ImageNet and demonstrate that the usage of these insights can give rise to improved models and functionally cleaned data corpora.
Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning
Dec 18, 2019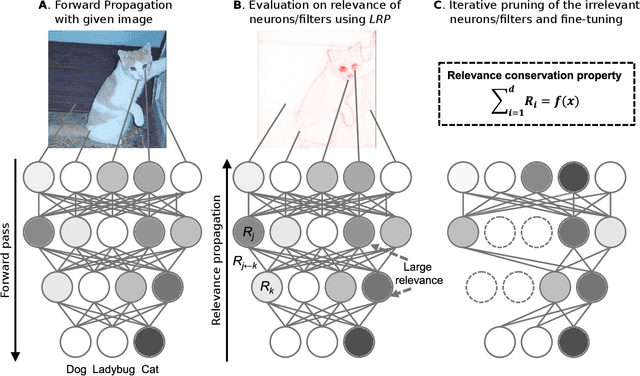
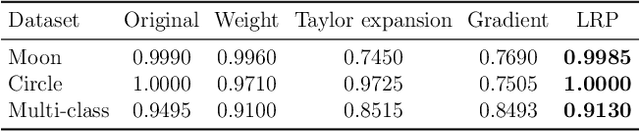
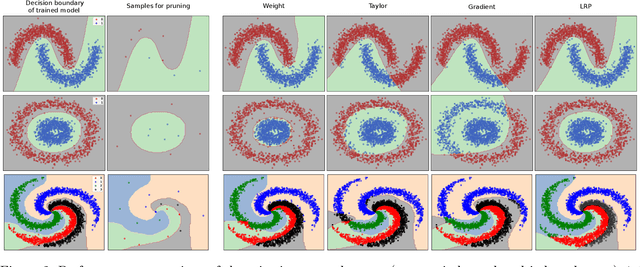

The success of convolutional neural networks (CNNs) in various applications is accompanied by a significant increase in computation and parameter storage costs. Recent efforts to reduce these overheads involve pruning and compressing the weights of various layers while at the same time aiming to not sacrifice performance. In this paper, we propose a novel criterion for CNN pruning inspired by neural network interpretability: The most relevant elements, i.e. weights or filters, are automatically found using their relevance score in the sense of explainable AI (XAI). By that we for the first time link the two disconnected lines of interpretability and model compression research. We show in particular that our proposed method can efficiently prune transfer-learned CNN models where networks pre-trained on large corpora are adapted to specialized tasks. To this end, the method is evaluated on a broad range of computer vision datasets. Notably, our novel criterion is not only competitive or better compared to state-of-the-art pruning criteria when successive retraining is performed, but clearly outperforms these previous criteria in the common application setting where the data of the task to be transferred to are very scarce and no retraining is possible. Our method can iteratively compress the model while maintaining or even improving accuracy. At the same time, it has a computational cost in the order of gradient computation and is comparatively simple to apply without the need for tuning hyperparameters for pruning.