 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning by Explaining: A Novel Criterion for Deep Neural Network Pruning
Dec 18, 2019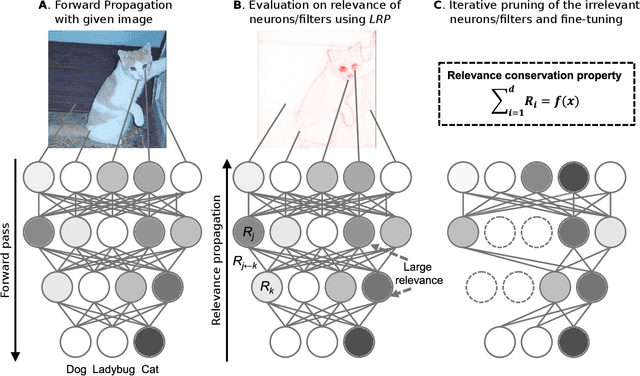
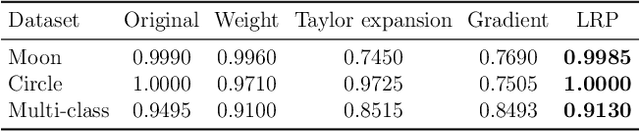
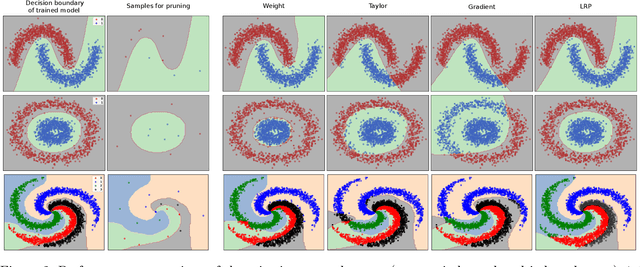

The success of convolutional neural networks (CNNs) in various applications is accompanied by a significant increase in computation and parameter storage costs. Recent efforts to reduce these overheads involve pruning and compressing the weights of various layers while at the same time aiming to not sacrifice performance. In this paper, we propose a novel criterion for CNN pruning inspired by neural network interpretability: The most relevant elements, i.e. weights or filters, are automatically found using their relevance score in the sense of explainable AI (XAI). By that we for the first time link the two disconnected lines of interpretability and model compression research. We show in particular that our proposed method can efficiently prune transfer-learned CNN models where networks pre-trained on large corpora are adapted to specialized tasks. To this end, the method is evaluated on a broad range of computer vision datasets. Notably, our novel criterion is not only competitive or better compared to state-of-the-art pruning criteria when successive retraining is performed, but clearly outperforms these previous criteria in the common application setting where the data of the task to be transferred to are very scarce and no retraining is possible. Our method can iteratively compress the model while maintaining or even improving accuracy. At the same time, it has a computational cost in the order of gradient computation and is comparatively simple to apply without the need for tuning hyperparameters for pruning.
On the Understanding and Interpretation of Machine Learning Predictions in Clinical Gait Analysis Using Explainable Artificial Intelligence
Dec 16, 2019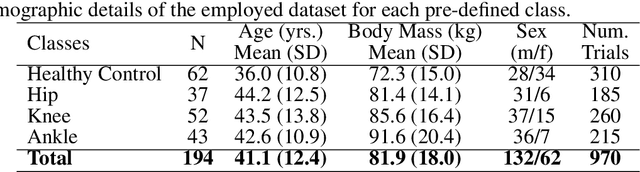
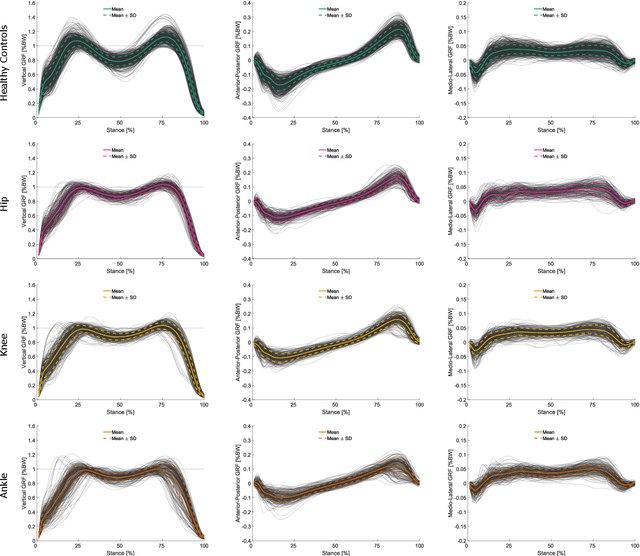
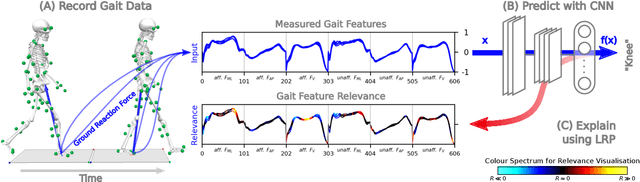
Systems incorporating Artificial Intelligence (AI) and machine learning (ML) techniques are increasingly used to guide decision-making in the healthcare sector. While AI-based systems provide powerful and promising results with regard to their classification and prediction accuracy (e.g., in differentiating between different disorders in human gait), most share a central limitation, namely their black-box character. Understanding which features classification models learn, whether they are meaningful and consequently whether their decisions are trustworthy is difficult and often impossible to comprehend. This severely hampers their applicability as decision-support systems in clinical practice. There is a strong need for AI-based systems to provide transparency and justification of predictions, which are necessary also for ethical and legal compliance. As a consequence, in recent years the field of explainable AI (XAI) has gained increasing importance. The primary aim of this article is to investigate whether XAI methods can enhance transparency, explainability and interpretability of predictions in automated clinical gait classification. We utilize a dataset comprising bilateral three-dimensional ground reaction force measurements from 132 patients with different lower-body gait disorders and 62 healthy controls. In our experiments, we included several gait classification tasks, employed a representative set of classification methods, and a well-established XAI method - Layer-wise Relevance Propagation - to explain decisions at the signal (input) level. The presented approach exemplifies how XAI can be used to understand and interpret state-of-the-art ML models trained for gait classification tasks, and shows that the features that are considered relevant for machine learning models can be attributed to meaningful and clinically relevant biomechanical gait characteristics.
Asymptotically Unbiased Generative Neural Sampling
Oct 29, 2019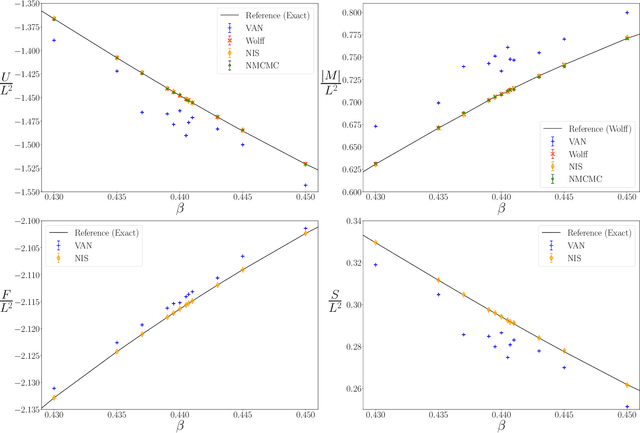
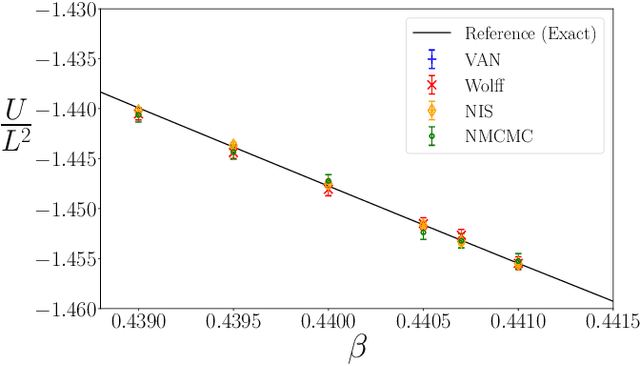
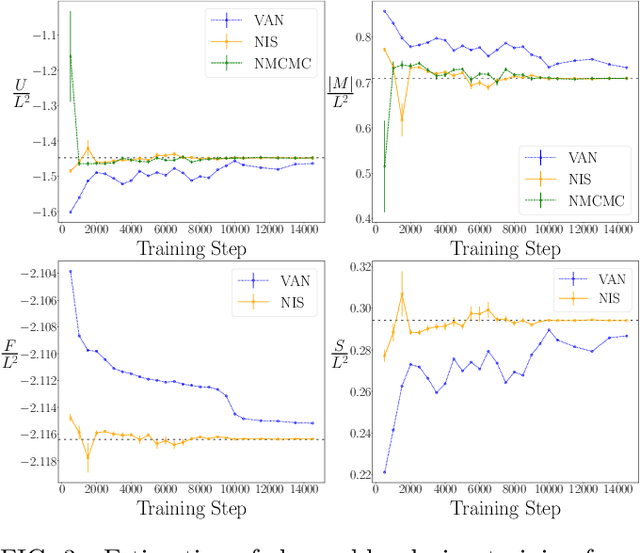
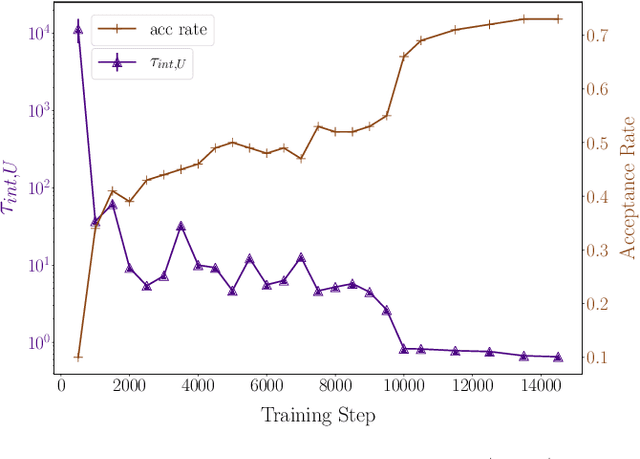
We propose a general framework for the estimation of observables with generative neural samplers focusing on modern deep generative neural networks that provide an exact sampling probability. In this framework, we present asymptotically unbiased estimators for generic observables, including those that explicitly depend on the partition function such as free energy or entropy, and derive corresponding variance estimators. We demonstrate their practical applicability by numerical experiments for the 2d Ising model which highlight the superiority over existing methods. Our approach greatly enhances the applicability of generative neural samplers to real-world physical systems.
Towards best practice in explaining neural network decisions with LRP
Oct 22, 2019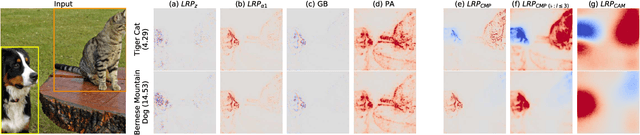
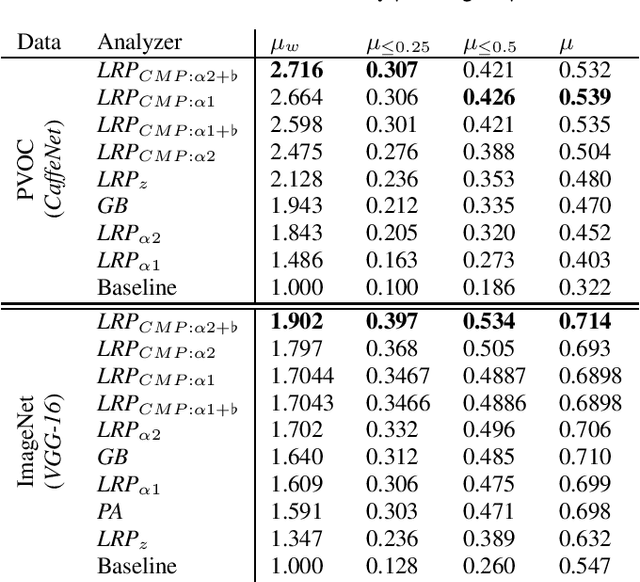
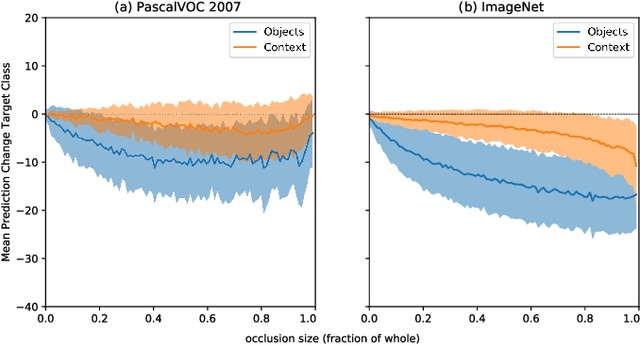
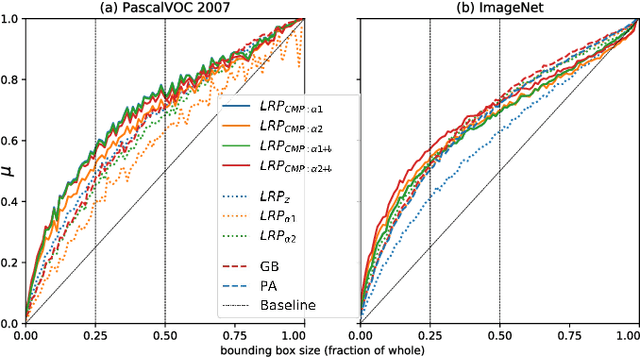
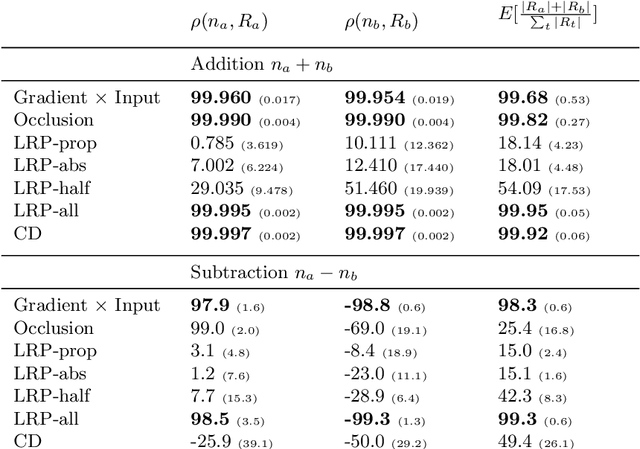
Within the last decade, neural network based predictors have demonstrated impressive - and at times super-human - capabilities. This performance is often paid for with an intransparent prediction process and thus has sparked numerous contributions in the novel field of explainable artificial intelligence (XAI). In this paper, we focus on a popular and widely used method of XAI, the Layer-wise Relevance Propagation (LRP). Since its initial proposition LRP has evolved as a method, and a best practice for applying the method has tacitly emerged, based on humanly observed evidence. We investigate - and for the first time quantify - the effect of this current best practice on feedforward neural networks in a visual object detection setting. The results verify that the current, layer-dependent approach to LRP applied in recent literature better represents the model's reasoning, and at the same time increases the object localization and class discriminativity of LRP.
Clustered Federated Learning: Model-Agnostic Distributed Multi-Task Optimization under Privacy Constraints
Oct 04, 2019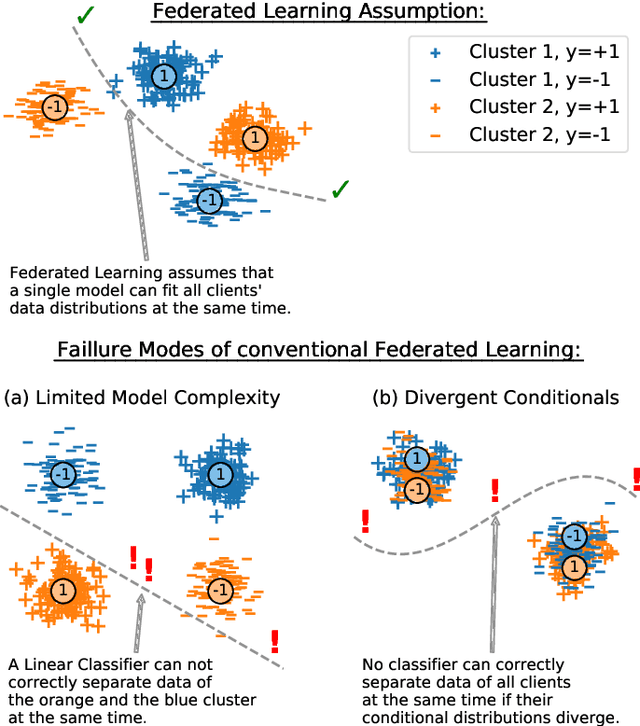
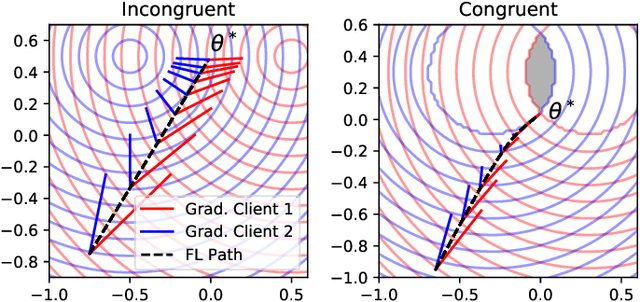
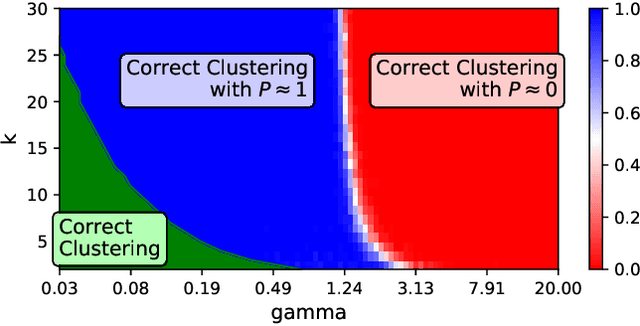
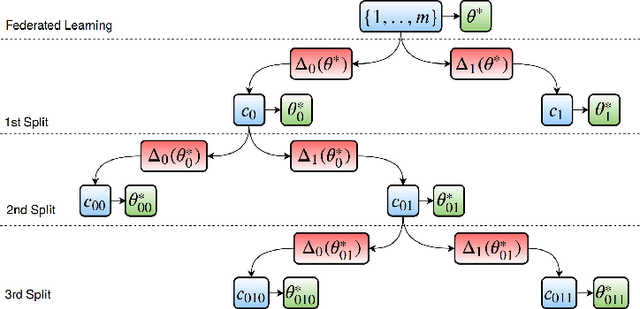
Federated Learning (FL) is currently the most widely adopted framework for collaborative training of (deep) machine learning models under privacy constraints. Albeit it's popularity, it has been observed that Federated Learning yields suboptimal results if the local clients' data distributions diverge. To address this issue, we present Clustered Federated Learning (CFL), a novel Federated Multi-Task Learning (FMTL) framework, which exploits geometric properties of the FL loss surface, to group the client population into clusters with jointly trainable data distributions. In contrast to existing FMTL approaches, CFL does not require any modifications to the FL communication protocol to be made, is applicable to general non-convex objectives (in particular deep neural networks) and comes with strong mathematical guarantees on the clustering quality. CFL is flexible enough to handle client populations that vary over time and can be implemented in a privacy preserving way. As clustering is only performed after Federated Learning has converged to a stationary point, CFL can be viewed as a post-processing method that will always achieve greater or equal performance than conventional FL by allowing clients to arrive at more specialized models. We verify our theoretical analysis in experiments with deep convolutional and recurrent neural networks on commonly used Federated Learning datasets.
Towards Explainable Artificial Intelligence
Sep 26, 2019In recent years, machine learning (ML) has become a key enabling technology for the sciences and industry. Especially through improvements in methodology, the availability of large databases and increased computational power, today's ML algorithms are able to achieve excellent performance (at times even exceeding the human level) on an increasing number of complex tasks. Deep learning models are at the forefront of this development. However, due to their nested non-linear structure, these powerful models have been generally considered "black boxes", not providing any information about what exactly makes them arrive at their predictions. Since in many applications, e.g., in the medical domain, such lack of transparency may be not acceptable, the development of methods for visualizing, explaining and interpreting deep learning models has recently attracted increasing attention. This introductory paper presents recent developments and applications in this field and makes a plea for a wider use of explainable learning algorithms in practice.
Explaining and Interpreting LSTMs
Sep 25, 2019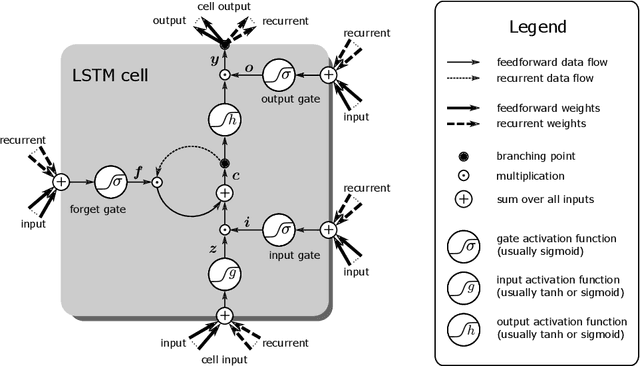

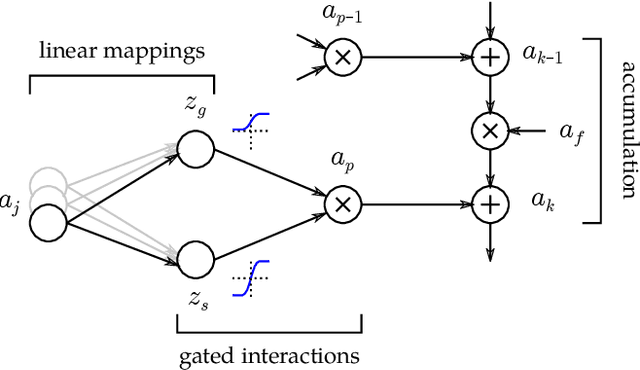
While neural networks have acted as a strong unifying force in the design of modern AI systems, the neural network architectures themselves remain highly heterogeneous due to the variety of tasks to be solved. In this chapter, we explore how to adapt the Layer-wise Relevance Propagation (LRP) technique used for explaining the predictions of feed-forward networks to the LSTM architecture used for sequential data modeling and forecasting. The special accumulators and gated interactions present in the LSTM require both a new propagation scheme and an extension of the underlying theoretical framework to deliver faithful explanations.
Resolving challenges in deep learning-based analyses of histopathological images using explanation methods
Aug 15, 2019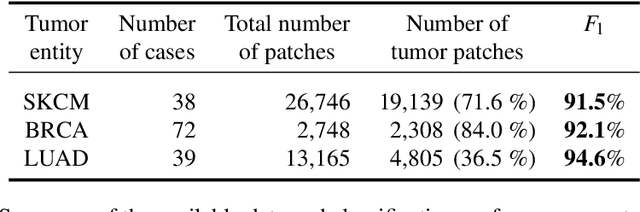
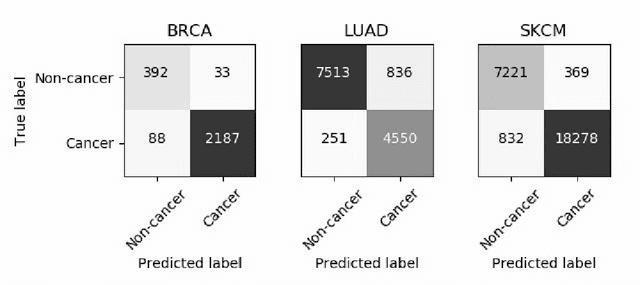

Deep learning has recently gained popularity in digital pathology due to its high prediction quality. However, the medical domain requires explanation and insight for a better understanding beyond standard quantitative performance evaluation. Recently, explanation methods have emerged, which are so far still rarely used in medicine. This work shows their application to generate heatmaps that allow to resolve common challenges encountered in deep learning-based digital histopathology analyses. These challenges comprise biases typically inherent to histopathology data. We study binary classification tasks of tumor tissue discrimination in publicly available haematoxylin and eosin slides of various tumor entities and investigate three types of biases: (1) biases which affect the entire dataset, (2) biases which are by chance correlated with class labels and (3) sampling biases. While standard analyses focus on patch-level evaluation, we advocate pixel-wise heatmaps, which offer a more precise and versatile diagnostic instrument and furthermore help to reveal biases in the data. This insight is shown to not only detect but also to be helpful to remove the effects of common hidden biases, which improves generalization within and across datasets. For example, we could see a trend of improved area under the receiver operating characteristic curve by 5% when reducing a labeling bias. Explanation techniques are thus demonstrated to be a helpful and highly relevant tool for the development and the deployment phases within the life cycle of real-world applications in digital pathology.
DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
Jul 27, 2019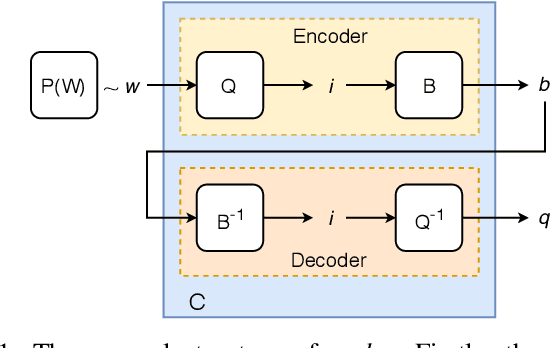
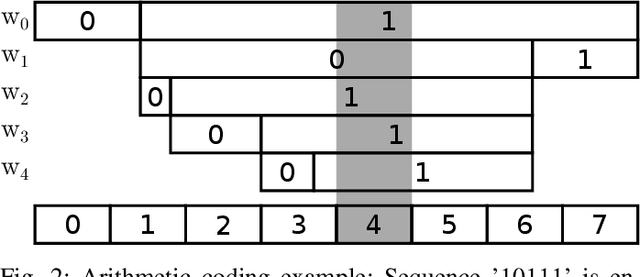
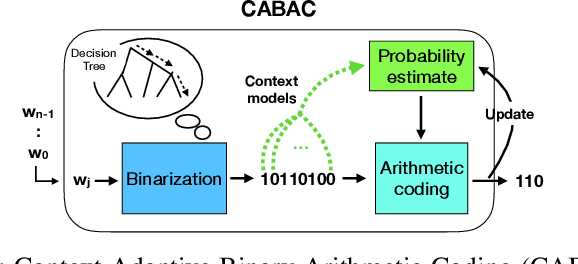
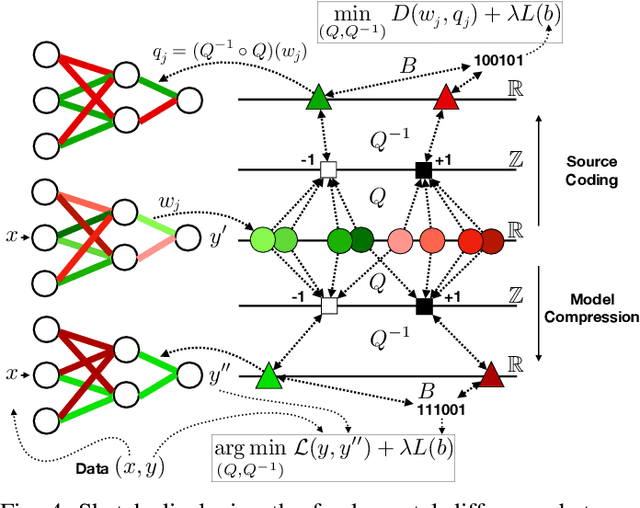
The field of video compression has developed some of the most sophisticated and efficient compression algorithms known in the literature, enabling very high compressibility for little loss of information. Whilst some of these techniques are domain specific, many of their underlying principles are universal in that they can be adapted and applied for compressing different types of data. In this work we present DeepCABAC, a compression algorithm for deep neural networks that is based on one of the state-of-the-art video coding techniques. Concretely, it applies a Context-based Adaptive Binary Arithmetic Coder (CABAC) to the network's parameters, which was originally designed for the H.264/AVC video coding standard and became the state-of-the-art for lossless compression. Moreover, DeepCABAC employs a novel quantization scheme that minimizes the rate-distortion function while simultaneously taking the impact of quantization onto the accuracy of the network into account. Experimental results show that DeepCABAC consistently attains higher compression rates than previously proposed coding techniques for neural network compression. For instance, it is able to compress the VGG16 ImageNet model by x63.6 with no loss of accuracy, thus being able to represent the entire network with merely 8.7MB. The source code for encoding and decoding can be found at https://github.com/fraunhoferhhi/DeepCABAC.
Deep Transfer Learning For Whole-Brain fMRI Analyses
Jul 02, 2019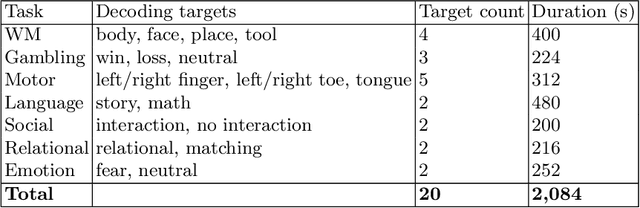
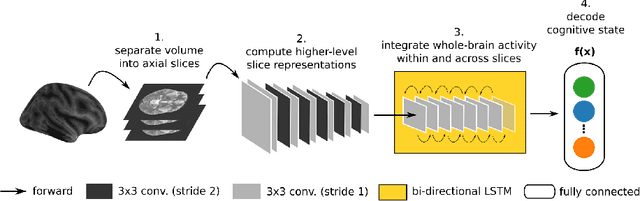
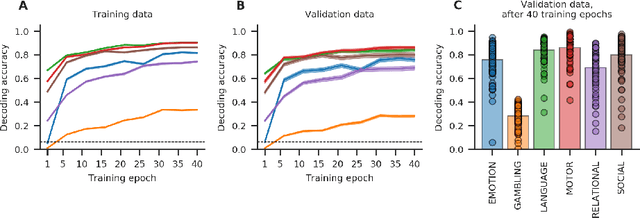
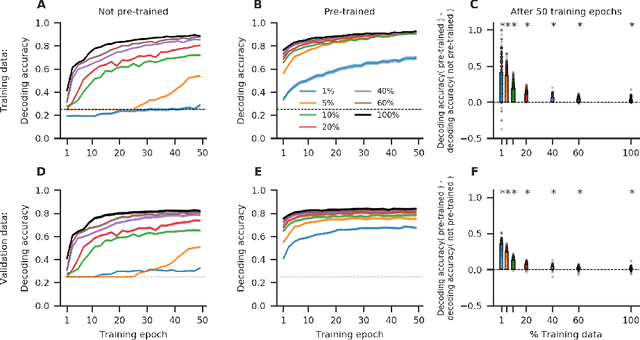
The application of deep learning (DL) models to the decoding of cognitive states from whole-brain functional Magnetic Resonance Imaging (fMRI) data is often hindered by the small sample size and high dimensionality of these datasets. Especially, in clinical settings, where patient data are scarce. In this work, we demonstrate that transfer learning represents a solution to this problem. Particularly, we show that a DL model, which has been previously trained on a large openly available fMRI dataset of the Human Connectome Project, outperforms a model variant with the same architecture, but which is trained from scratch, when both are applied to the data of a new, unrelated fMRI task. Even further, the pre-trained DL model variant is already able to correctly decode 67.51% of the cognitive states from a test dataset with 100 individuals, when fine-tuned on a dataset of the size of only three subjects.