 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydranet: Data Augmentation for Regression Neural Networks
Jul 12, 2018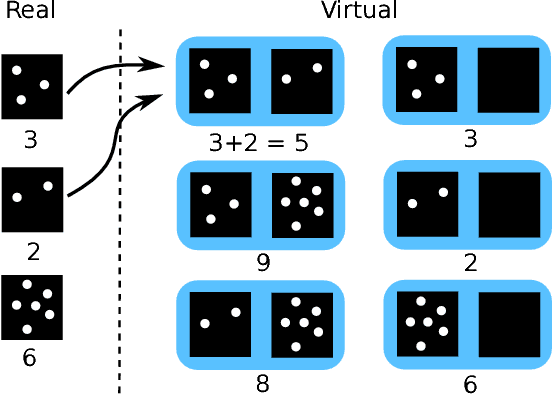
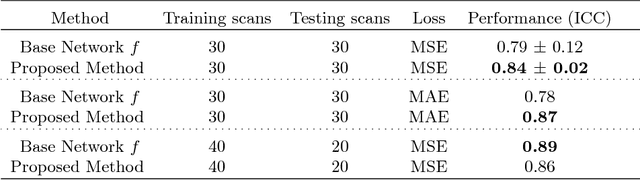
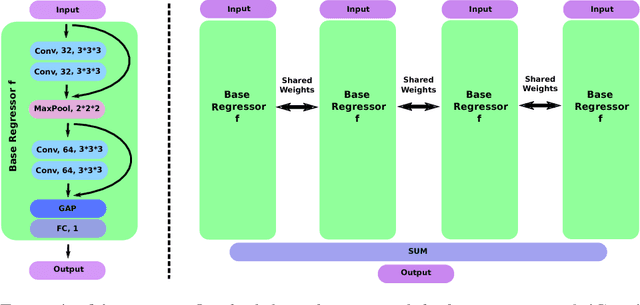
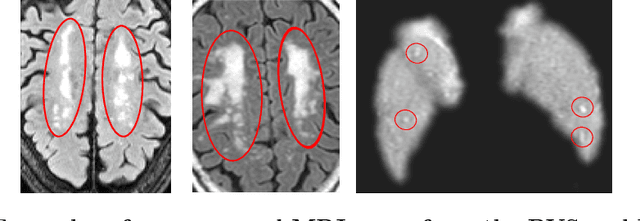
Despite recent efforts, deep learning techniques remain often heavily dependent on a large quantity of labeled data. This problem is even more challenging in medical image analysis where the annotator expertise is often scarce. In this paper we propose a novel data-augmentation method to regularize neural network regressors, learning from a single global label per image. The principle of the method is to create new samples by recombining existing ones. We demonstrate the performance of our algorithm on two tasks: the regression of number of enlarged perivascular spaces in the basal ganglia; and the regression of white matter hyperintensities volume. We show that the proposed method improves the performance even when more basic data augmentation is used. Furthermore we reached an intraclass correlation coefficient between ground truth and network predictions of 0.73 on the first task and 0.86 on the second task, only using between 25 and 30 scans with a single global label per scan for training. To achieve a similar correlation on the first task, state-of-the-art methods needed more than 1000 training scans.
Is the winner really the best? A critical analysis of common research practice in biomedical image analysis competitions
Jun 06, 2018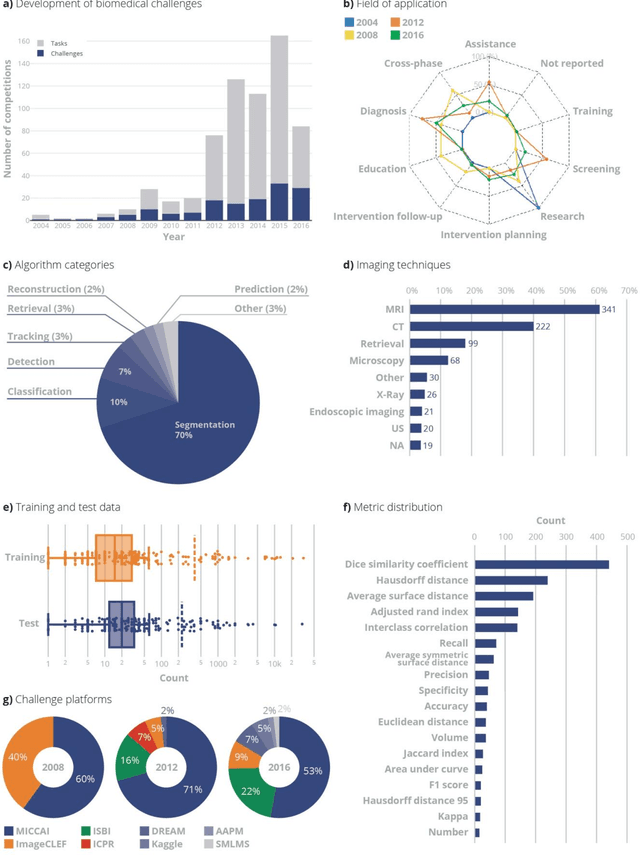
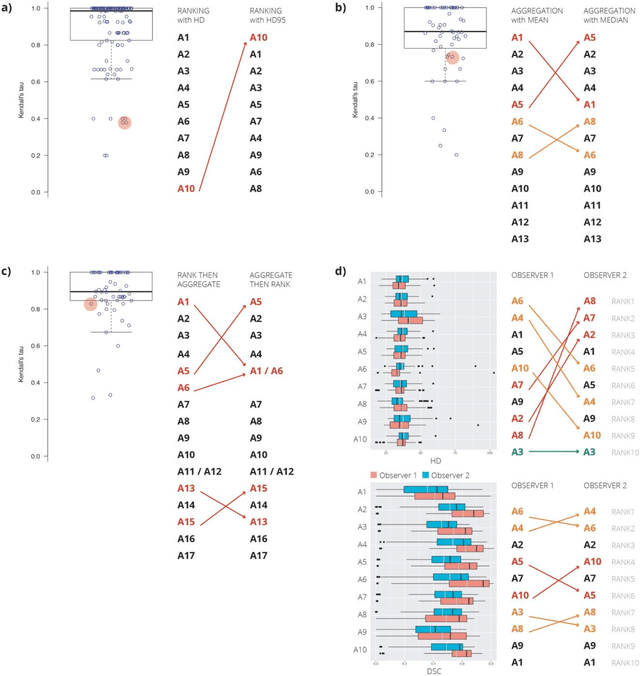
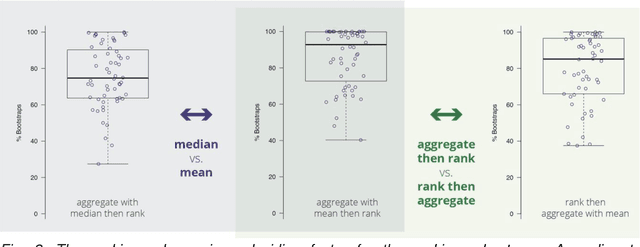
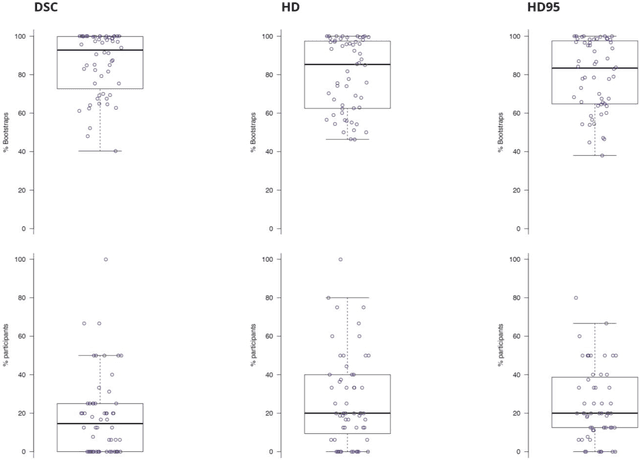
International challenges have become the standard for validation of biomedical image analysis methods. Given their scientific impact, it is surprising that a critical analysis of common practices related to the organization of challenges has not yet been performed. In this paper, we present a comprehensive analysis of biomedical image analysis challenges conducted up to now. We demonstrate the importance of challenges and show that the lack of quality control has critical consequences. First, reproducibility and interpretation of the results is often hampered as only a fraction of relevant information is typically provided. Second, the rank of an algorithm is generally not robust to a number of variables such as the test data used for validation, the ranking scheme applied and the observers that make the reference annotations. To overcome these problems, we recommend best practice guidelines and define open research questions to be addressed in the future.
GP-Unet: Lesion Detection from Weak Labels with a 3D Regression Network
Oct 30, 2017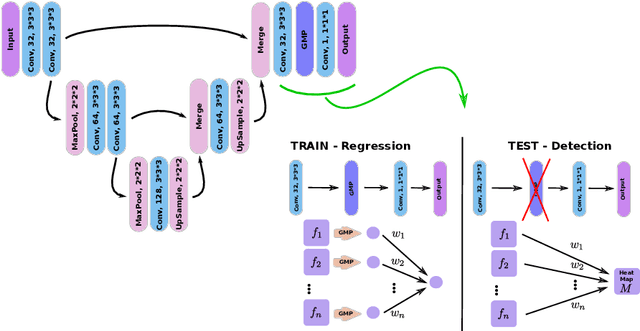
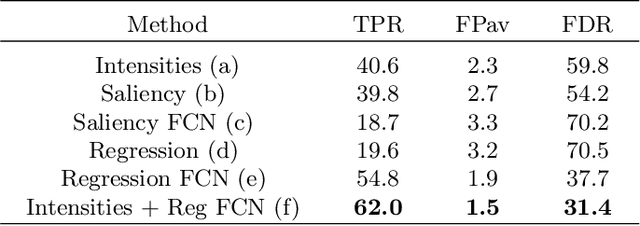
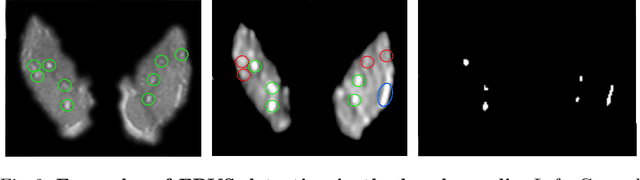
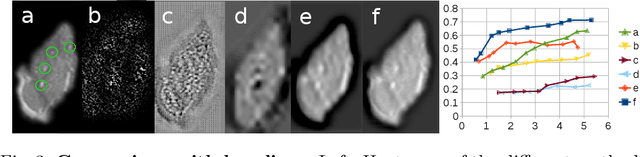
We propose a novel convolutional neural network for lesion detection from weak labels. Only a single, global label per image - the lesion count - is needed for training. We train a regression network with a fully convolutional architecture combined with a global pooling layer to aggregate the 3D output into a scalar indicating the lesion count. When testing on unseen images, we first run the network to estimate the number of lesions. Then we remove the global pooling layer to compute localization maps of the size of the input image. We evaluate the proposed network on the detection of enlarged perivascular spaces in the basal ganglia in MRI. Our method achieves a sensitivity of 62% with on average 1.5 false positives per image. Compared with four other approaches based on intensity thresholding, saliency and class maps, our method has a 20% higher sensitivity.
A Discriminative Event Based Model for Alzheimer's Disease Progression Modeling
Feb 21, 2017
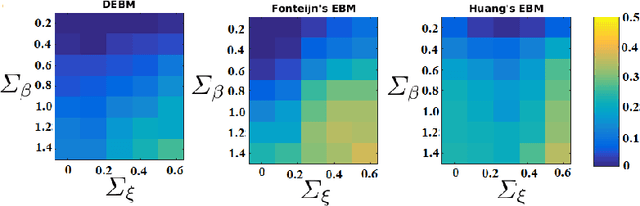
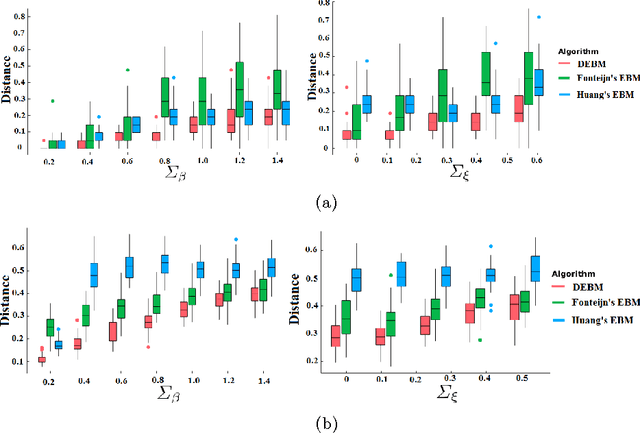
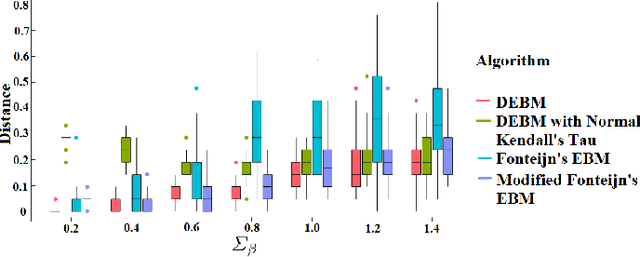
The event-based model (EBM) for data-driven disease progression modeling estimates the sequence in which biomarkers for a disease become abnormal. This helps in understanding the dynamics of disease progression and facilitates early diagnosis by staging patients on a disease progression timeline. Existing EBM methods are all generative in nature. In this work we propose a novel discriminative approach to EBM, which is shown to be more accurate as well as computationally more efficient than existing state-of-the art EBM methods. The method first estimates for each subject an approximate ordering of events, by ranking the posterior probabilities of individual biomarkers being abnormal. Subsequently, the central ordering over all subjects is estimated by fitting a generalized Mallows model to these approximate subject-specific orderings based on a novel probabilistic Kendall's Tau distance. To evaluate the accuracy, we performed extensive experiments on synthetic data simulating the progression of Alzheimer's disease. Subsequently, the method was applied to the Alzheimer's Disease Neuroimaging Initiative (ADNI) data to estimate the central event ordering in the dataset. The experiments benchmark the accuracy of the new model under various conditions and compare it with existing state-of-the-art EBM methods. The results indicate that discriminative EBM could be a simple and elegant approach to disease progression modeling.