 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRoC: Context Refactoring Contrast for Graph Anomaly Detection with Limited Supervision
Aug 17, 2025Graph Neural Networks (GNNs) are widely used as the engine for various graph-related tasks, with their effectiveness in analyzing graph-structured data. However, training robust GNNs often demands abundant labeled data, which is a critical bottleneck in real-world applications. This limitation severely impedes progress in Graph Anomaly Detection (GAD), where anomalies are inherently rare, costly to label, and may actively camouflage their patterns to evade detection. To address these problems, we propose Context Refactoring Contrast (CRoC), a simple yet effective framework that trains GNNs for GAD by jointly leveraging limited labeled and abundant unlabeled data. Different from previous works, CRoC exploits the class imbalance inherent in GAD to refactor the context of each node, which builds augmented graphs by recomposing the attributes of nodes while preserving their interaction patterns. Furthermore, CRoC encodes heterogeneous relations separately and integrates them into the message-passing process, enhancing the model's capacity to capture complex interaction semantics. These operations preserve node semantics while encouraging robustness to adversarial camouflage, enabling GNNs to uncover intricate anomalous cases. In the training stage, CRoC is further integrated with the contrastive learning paradigm. This allows GNNs to effectively harness unlabeled data during joint training, producing richer, more discriminative node embeddings. CRoC is evaluated on seven real-world GAD datasets with varying scales. Extensive experiments demonstrate that CRoC achieves up to 14% AUC improvement over baseline GNNs and outperforms state-of-the-art GAD methods under limited-label settings.
GTEA: Representation Learning for Temporal Interaction Graphs via Edge Aggregation
Sep 28, 2020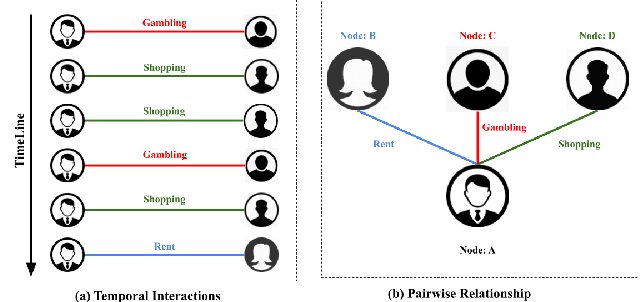

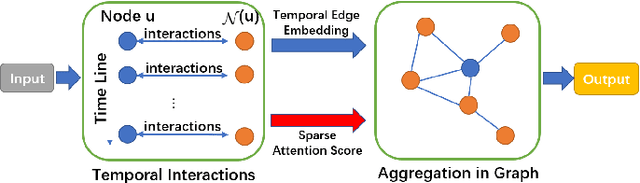
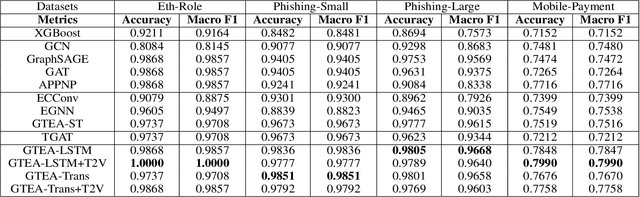
We consider the problem of representation learning for temporal interaction graphs where a network of entities with complex interactions over an extended period of time is modeled as a graph with a rich set of node and edge attributes. In particular, an edge between a node-pair within the graph corresponds to a multi-dimensional time-series. To fully capture and model the dynamics of the network, we propose GTEA, a framework of representation learning for temporal interaction graphs with per-edge time-based aggregation. Under GTEA, a Graph Neural Network (GNN) is integrated with a state-of-the-art sequence model, such as LSTM, Transformer and their time-aware variants. The sequence model generates edge embeddings to encode temporal interaction patterns between each pair of nodes, while the GNN-based backbone learns the topological dependencies and relationships among different nodes. GTEA also incorporates a sparsity-inducing self-attention mechanism to distinguish and focus on the more important neighbors of each node during the aggregation process. By capturing temporal interactive dynamics together with multi-dimensional node and edge attributes in a network, GTEA can learn fine-grained representations for a temporal interaction graph to enable or facilitate other downstream data analytic tasks. Experimental results show that GTEA outperforms state-of-the-art schemes including GraphSAGE, APPNP, and TGAT by delivering higher accuracy (100.00%, 98.51%, 98.05% ,79.90%) and macro-F1 score (100.00%, 98.51%, 96.68% ,79.90%) over four large-scale real-world datasets for binary/ multi-class node classification.
Identifying Illicit Accounts in Large Scale E-payment Networks -- A Graph Representation Learning Approach
Jun 13, 2019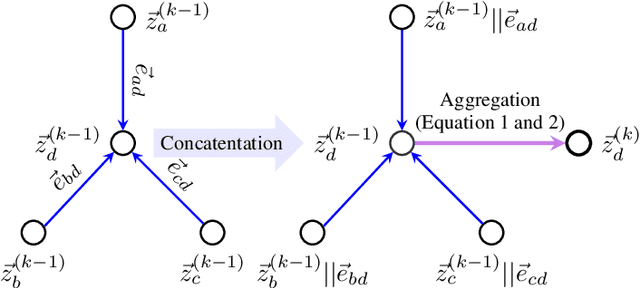


Rapid and massive adoption of mobile/ online payment services has brought new challenges to the service providers as well as regulators in safeguarding the proper uses such services/ systems. In this paper, we leverage recent advances in deep-neural-network-based graph representation learning to detect abnormal/ suspicious financial transactions in real-world e-payment networks. In particular, we propose an end-to-end Graph Convolution Network (GCN)-based algorithm to learn the embeddings of the nodes and edges of a large-scale time-evolving graph. In the context of e-payment transaction graphs, the resultant node and edge embeddings can effectively characterize the user-background as well as the financial transaction patterns of individual account holders. As such, we can use the graph embedding results to drive downstream graph mining tasks such as node-classification to identify illicit accounts within the payment networks. Our algorithm outperforms state-of-the-art schemes including GraphSAGE, Gradient Boosting Decision Tree and Random Forest to deliver considerably higher accuracy (94.62% and 86.98% respectively) in classifying user accounts within 2 practical e-payment transaction datasets. It also achieves outstanding accuracy (97.43%) for another biomedical entity identification task while using only edge-related information.
Robust and Fast Decoding of High-Capacity Color QR Codes for Mobile Applications
May 19, 2018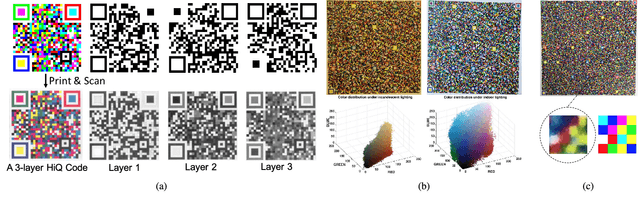
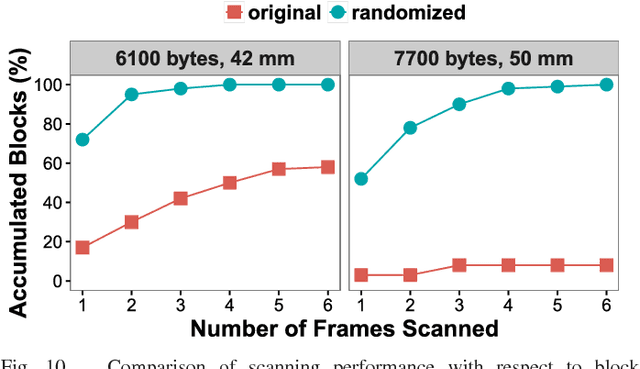
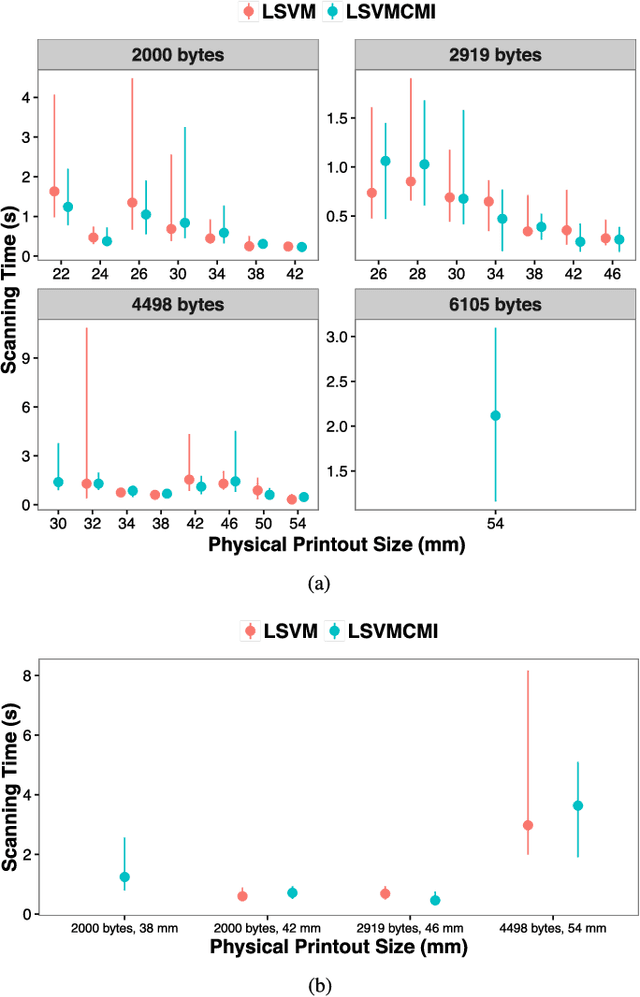

The use of color in QR codes brings extra data capacity, but also inflicts tremendous challenges on the decoding process due to chromatic distortion, cross-channel color interference and illumination variation. Particularly, we further discover a new type of chromatic distortion in high-density color QR codes, cross-module color interference, caused by the high density which also makes the geometric distortion correction more challenging. To address these problems, we propose two approaches, namely, LSVM-CMI and QDA-CMI, which jointly model these different types of chromatic distortion. Extended from SVM and QDA, respectively, both LSVM-CMI and QDA-CMI optimize over a particular objective function to learn a color classifier. Furthermore, a robust geometric transformation method and several pipeline refinements are proposed to boost the decoding performance for mobile applications. We put forth and implement a framework for high-capacity color QR codes equipped with our methods, called HiQ. To evaluate the performance of HiQ, we collect a challenging large-scale color QR code dataset, CUHK-CQRC, which consists of 5390 high-density color QR code samples. The comparison with the baseline method [2] on CUHK-CQRC shows that HiQ at least outperforms [2] by 188% in decoding success rate and 60% in bit error rate. Our implementation of HiQ in iOS and Android also demonstrates the effectiveness of our framework in real-world applications.
Secure Friend Discovery via Privacy-Preserving and Decentralized Community Detection
May 20, 2014The problem of secure friend discovery on a social network has long been proposed and studied. The requirement is that a pair of nodes can make befriending decisions with minimum information exposed to the other party. In this paper, we propose to use community detection to tackle the problem of secure friend discovery. We formulate the first privacy-preserving and decentralized community detection problem as a multi-objective optimization. We design the first protocol to solve this problem, which transforms community detection to a series of Private Set Intersection (PSI) instances using Truncated Random Walk (TRW). Preliminary theoretical results show that our protocol can uncover communities with overwhelming probability and preserve privacy. We also discuss future works, potential extensions and variations.
Localized Algorithm of Community Detection on Large-Scale Decentralized Social Networks
Dec 27, 2012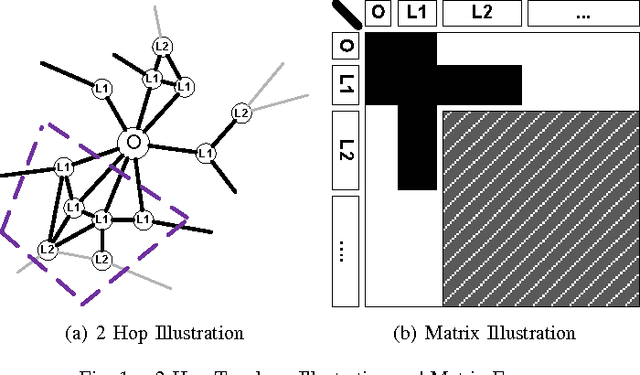
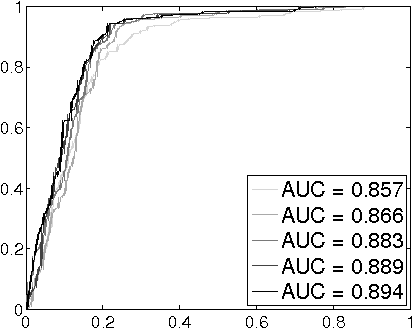
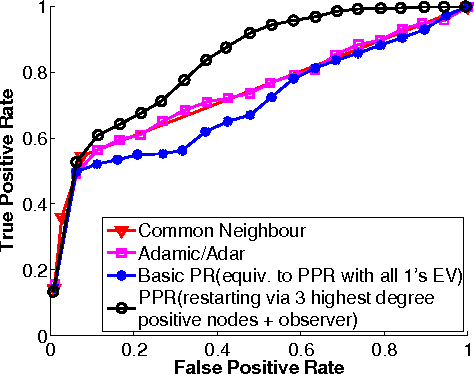
Despite the overwhelming success of the existing Social Networking Services (SNS), their centralized ownership and control have led to serious concerns in user privacy, censorship vulnerability and operational robustness of these services. To overcome these limitations, Distributed Social Networks (DSN) have recently been proposed and implemented. Under these new DSN architectures, no single party possesses the full knowledge of the entire social network. While this approach solves the above problems, the lack of global knowledge for the DSN nodes makes it much more challenging to support some common but critical SNS services like friends discovery and community detection. In this paper, we tackle the problem of community detection for a given user under the constraint of limited local topology information as imposed by common DSN architectures. By considering the Personalized Page Rank (PPR) approach as an ink spilling process, we justify its applicability for decentralized community detection using limited local topology information.Our proposed PPR-based solution has a wide range of applications such as friends recommendation, targeted advertisement, automated social relationship labeling and sybil defense. Using data collected from a large-scale SNS in practice, we demonstrate our adapted version of PPR can significantly outperform the basic PR as well as two other commonly used heuristics. The inclusion of a few manually labeled friends in the Escape Vector (EV) can boost the performance considerably (64.97% relative improvement in terms of Area Under the ROC Curve (AUC)).