 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal 3D Reconstruction of Clouds & Tropical Cyclones
Nov 06, 2025Accurate forecasting of tropical cyclones (TCs) remains challenging due to limited satellite observations probing TC structure and difficulties in resolving cloud properties involved in TC intensification. Recent research has demonstrated the capabilities of machine learning methods for 3D cloud reconstruction from satellite observations. However, existing approaches have been restricted to regions where TCs are uncommon, and are poorly validated for intense storms. We introduce a new framework, based on a pre-training--fine-tuning pipeline, that learns from multiple satellites with global coverage to translate 2D satellite imagery into 3D cloud maps of relevant cloud properties. We apply our model to a custom-built TC dataset to evaluate performance in the most challenging and relevant conditions. We show that we can - for the first time - create global instantaneous 3D cloud maps and accurately reconstruct the 3D structure of intense storms. Our model not only extends available satellite observations but also provides estimates when observations are missing entirely. This is crucial for advancing our understanding of TC intensification and improving forecasts.
3D Cloud reconstruction through geospatially-aware Masked Autoencoders
Jan 03, 2025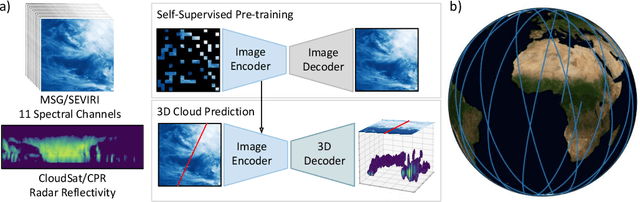
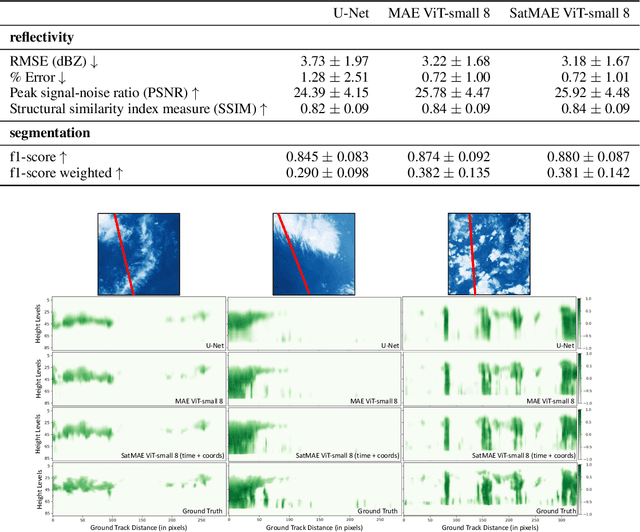
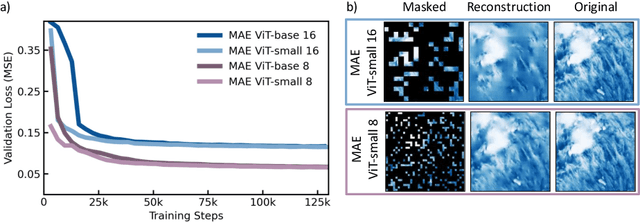
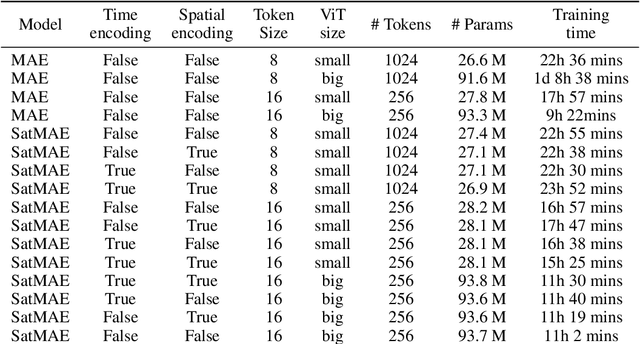
Clouds play a key role in Earth's radiation balance with complex effects that introduce large uncertainties into climate models. Real-time 3D cloud data is essential for improving climate predictions. This study leverages geostationary imagery from MSG/SEVIRI and radar reflectivity measurements of cloud profiles from CloudSat/CPR to reconstruct 3D cloud structures. We first apply self-supervised learning (SSL) methods-Masked Autoencoders (MAE) and geospatially-aware SatMAE on unlabelled MSG images, and then fine-tune our models on matched image-profile pairs. Our approach outperforms state-of-the-art methods like U-Nets, and our geospatial encoding further improves prediction results, demonstrating the potential of SSL for cloud reconstruction.
NightVision: Generating Nighttime Satellite Imagery from Infra-Red Observations
Dec 08, 2020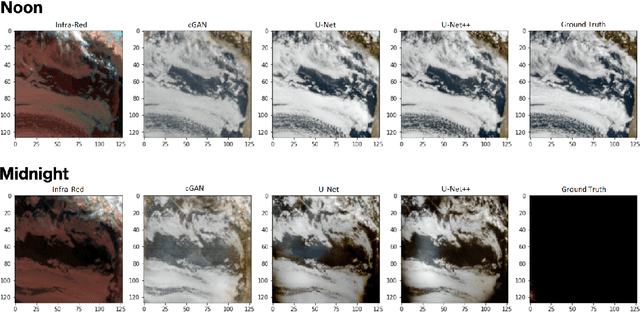
The recent explosion in applications of machine learning to satellite imagery often rely on visible images and therefore suffer from a lack of data during the night. The gap can be filled by employing available infra-red observations to generate visible images. This work presents how deep learning can be applied successfully to create those images by using U-Net based architectures. The proposed methods show promising results, achieving a structural similarity index (SSIM) up to 86\% on an independent test set and providing visually convincing output images, generated from infra-red observations.
Deep Learned Path Planning via Randomized Reward-Linked-Goals and Potential Space Applications
Sep 13, 2019

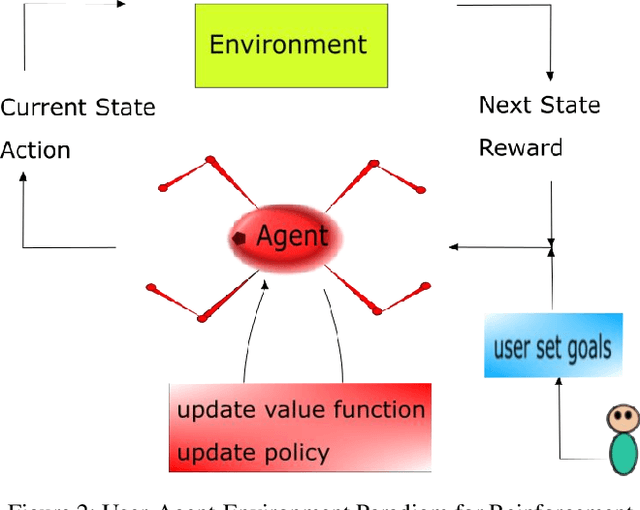
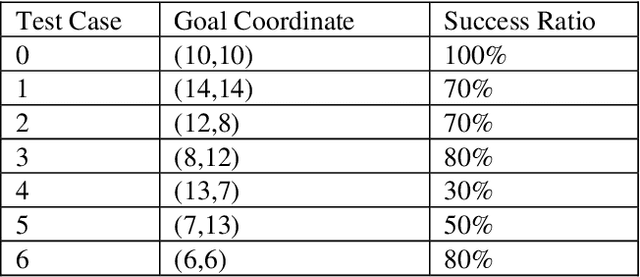
Space exploration missions have seen use of increasingly sophisticated robotic systems with ever more autonomy. Deep learning promises to take this even a step further, and has applications for high-level tasks, like path planning, as well as low-level tasks, like motion control, which are critical components for mission efficiency and success. Using deep reinforcement end-to-end learning with randomized reward function parameters during training, we teach a simulated 8 degree-of-freedom quadruped ant-like robot to travel anywhere within a perimeter, conducting path plan and motion control on a single neural network, without any system model or prior knowledge of the terrain or environment. Our approach also allows for user specified waypoints, which could translate well to either fully autonomous or semi-autonomous/teleoperated space applications that encounter delay times. We trained the agent using randomly generated waypoints linked to the reward function and passed waypoint coordinates as inputs to the neural network. Such applications show promise on a variety of space exploration robots, including high speed rovers for fast locomotion and legged cave robots for rough terrain.