 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASP: Topology-aware Sequence Parallelism
Sep 30, 2025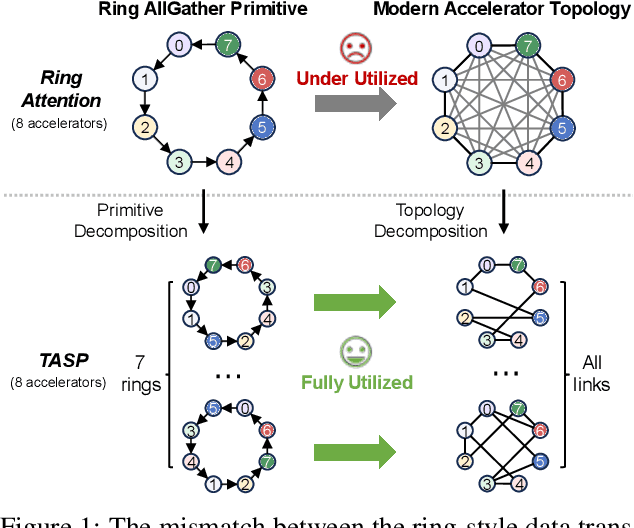


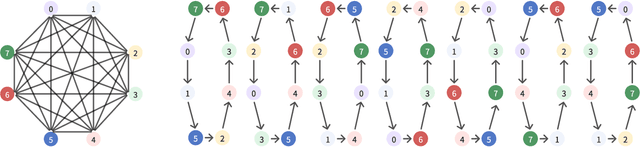
Long-context large language models (LLMs) face constraints due to the quadratic complexity of the self-attention mechanism. The mainstream sequence parallelism (SP) method, Ring Attention, attempts to solve this by distributing the query into multiple query chunks across accelerators and enable each Q tensor to access all KV tensors from other accelerators via the Ring AllGather communication primitive. However, it exhibits low communication efficiency, restricting its practical applicability. This inefficiency stems from the mismatch between the Ring AllGather communication primitive it adopts and the AlltoAll topology of modern accelerators. A Ring AllGather primitive is composed of iterations of ring-styled data transfer, which can only utilize a very limited fraction of an AlltoAll topology. Inspired by the Hamiltonian decomposition of complete directed graphs, we identify that modern accelerator topology can be decomposed into multiple orthogonal ring datapaths which can concurrently transfer data without interference. Based on this, we further observe that the Ring AllGather primitive can also be decomposed into the same number of concurrent ring-styled data transfer at every iteration. Based on these insights, we propose TASP, a topology-aware SP method for long-context LLMs that fully utilizes the communication capacity of modern accelerators via topology decomposition and primitive decomposition. Experimental results on both single-node and multi-node NVIDIA H100 systems and a single-node AMD MI300X system demonstrate that TASP achieves higher communication efficiency than Ring Attention on these modern accelerator topologies and achieves up to 3.58 speedup than Ring Attention and its variant Zigzag-Ring Attention. The code is available at https://github.com/infinigence/HamiltonAttention.
Block-Wise Dynamic-Precision Neural Network Training Acceleration via Online Quantization Sensitivity Analytics
Oct 31, 2022



Data quantization is an effective method to accelerate neural network training and reduce power consumption. However, it is challenging to perform low-bit quantized training: the conventional equal-precision quantization will lead to either high accuracy loss or limited bit-width reduction, while existing mixed-precision methods offer high compression potential but failed to perform accurate and efficient bit-width assignment. In this work, we propose DYNASTY, a block-wise dynamic-precision neural network training framework. DYNASTY provides accurate data sensitivity information through fast online analytics, and maintains stable training convergence with an adaptive bit-width map generator. Network training experiments on CIFAR-100 and ImageNet dataset are carried out, and compared to 8-bit quantization baseline, DYNASTY brings up to $5.1\times$ speedup and $4.7\times$ energy consumption reduction with no accuracy drop and negligible hardware overhead.