 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Low-Rank Tensor Model for Video Completion
Sep 07, 2015
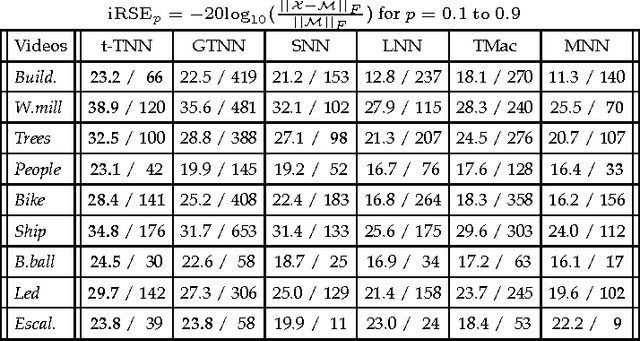
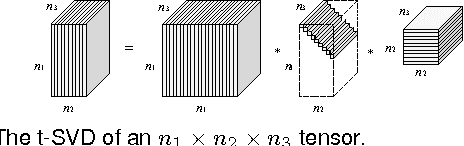
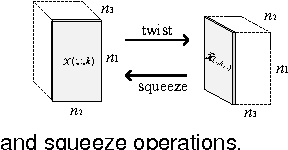
In this paper, we propose a new low-rank tensor model based on the circulant algebra, namely, twist tensor nuclear norm or t-TNN for short. The twist tensor denotes a 3-way tensor representation to laterally store 2D data slices in order. On one hand, t-TNN convexly relaxes the tensor multi-rank of the twist tensor in the Fourier domain, which allows an efficient computation using FFT. On the other, t-TNN is equal to the nuclear norm of block circulant matricization of the twist tensor in the original domain, which extends the traditional matrix nuclear norm in a block circulant way. We test the t-TNN model on a video completion application that aims to fill missing values and the experiment results validate its effectiveness, especially when dealing with video recorded by a non-stationary panning camera. The block circulant matricization of the twist tensor can be transformed into a circulant block representation with nuclear norm invariance. This representation, after transformation, exploits the horizontal translation relationship between the frames in a video, and endows the t-TNN model with a more powerful ability to reconstruct panning videos than the existing state-of-the-art low-rank models.
Distortion-driven Turbulence Effect Removal using Variational Model
Jan 17, 2014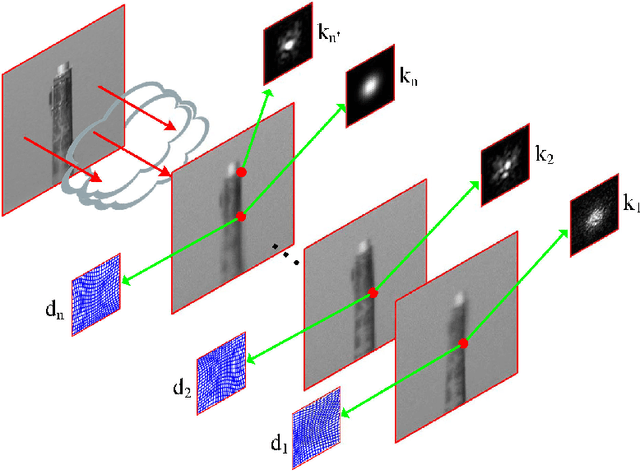



It remains a challenge to simultaneously remove geometric distortion and space-time-varying blur in frames captured through a turbulent atmospheric medium. To solve, or at least reduce these effects, we propose a new scheme to recover a latent image from observed frames by integrating a new variational model and distortion-driven spatial-temporal kernel regression. The proposed scheme first constructs a high-quality reference image from the observed frames using low-rank decomposition. Then, to generate an improved registered sequence, the reference image is iteratively optimized using a variational model containing a new spatial-temporal regularization. The proposed fast algorithm efficiently solves this model without the use of partial differential equations (PDEs). Next, to reduce blur variation, distortion-driven spatial-temporal kernel regression is carried out to fuse the registered sequence into one image by introducing the concept of the near-stationary patch. Applying a blind deconvolution algorithm to the fused image produces the final output. Extensive experimental testing shows, both qualitatively and quantitatively, that the proposed method can effectively alleviate distortion and blur and recover details of the original scene compared to state-of-the-art methods.