 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Knowledge Graph Foundation Models via Enhanced Negative Sampling
May 26, 2026Knowledge graphs (KGs) have become the core backbone of numerous downstream tasks such as question answering and recommender systems. However, despite all this, KGs are often very incomplete. To perform zero-shot knowledge graph completion in unseen KGs, which have different relational vocabularies from those used for pre-training, KG foundation models (KGFMs) receive a wide range of attention. Existing KGFMs often perform training using random negative triples, which are constructed by replacing the head or tail entity of a positive triple with a random entity. However, these negative triples are often constructed with limited quality, providing weak supervision for KGFM training. In this paper, we propose a simple yet effective adaptive negative sampling approach, KMAS, to enhance existing KGFMs. KMAS constructs hard negative triples through the updated relation embeddings generated from the existing KGFM's relation encoder. To further adaptively align with the evolving capability of the KGFM during the training process, KMAS adjusts the ratio of hard negative triples dynamically throughout the whole training process: after a warmup phrase, it increases the ratio linearly and then decreases linearly. Extensive experiments are conducted over 44 data sets. Experimental results demonstrate that our proposed negative sampling method can enhance many SOTA KGFMs without requiring excessive additional time or memory consumption.
Automatic Construction of Enterprise Knowledge Base
Jun 29, 2021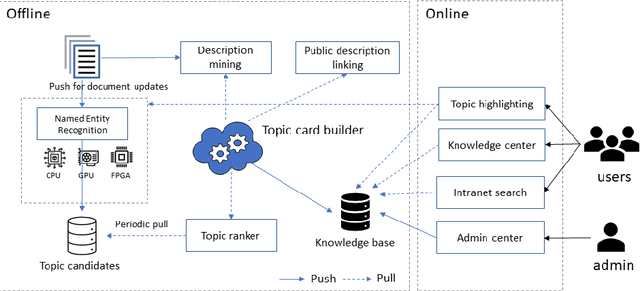

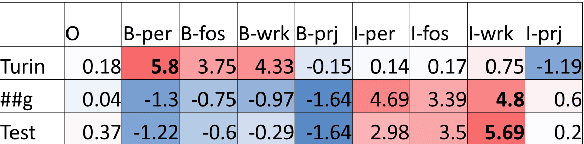
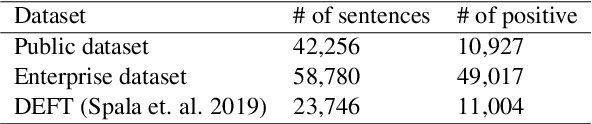
In this paper, we present an automatic knowledge base construction system from large scale enterprise documents with minimal efforts of human intervention. In the design and deployment of such a knowledge mining system for enterprise, we faced several challenges including data distributional shift, performance evaluation, compliance requirements and other practical issues. We leveraged state-of-the-art deep learning models to extract information (named entities and definitions) at per document level, then further applied classical machine learning techniques to process global statistical information to improve the knowledge base. Experimental results are reported on actual enterprise documents. This system is currently serving as part of a Microsoft 365 service.
Cross-Lingual Named Entity Recognition Using Parallel Corpus: A New Approach Using XLM-RoBERTa Alignment
Jan 26, 2021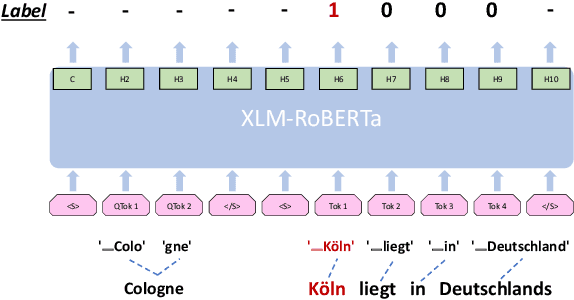
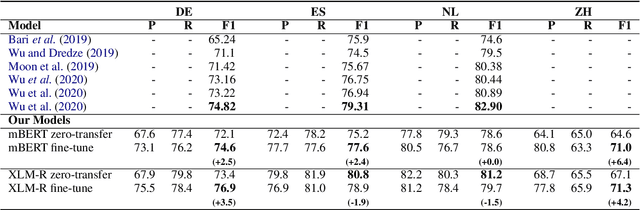
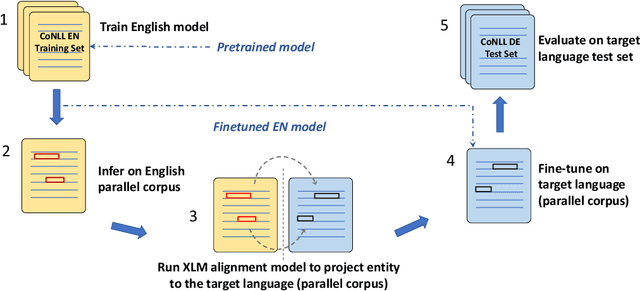
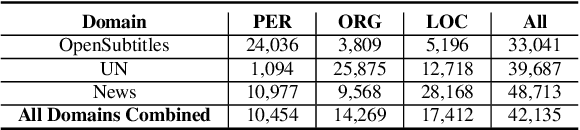
We propose a novel approach for cross-lingual Named Entity Recognition (NER) zero-shot transfer using parallel corpora. We built an entity alignment model on top of XLM-RoBERTa to project the entities detected on the English part of the parallel data to the target language sentences, whose accuracy surpasses all previous unsupervised models. With the alignment model we can get pseudo-labeled NER data set in the target language to train task-specific model. Unlike using translation methods, this approach benefits from natural fluency and nuances in target-language original corpus. We also propose a modified loss function similar to focal loss but assigns weights in the opposite direction to further improve the model training on noisy pseudo-labeled data set. We evaluated this proposed approach over 4 target languages on benchmark data sets and got competitive F1 scores compared to most recent SOTA models. We also gave extra discussions about the impact of parallel corpus size and domain on the final transfer performance.