 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel ILP Framework for Summarizing Content with High Lexical Variety
Jul 25, 2018

Summarizing content contributed by individuals can be challenging, because people make different lexical choices even when describing the same events. However, there remains a significant need to summarize such content. Examples include the student responses to post-class reflective questions, product reviews, and news articles published by different news agencies related to the same events. High lexical diversity of these documents hinders the system's ability to effectively identify salient content and reduce summary redundancy. In this paper, we overcome this issue by introducing an integer linear programming-based summarization framework. It incorporates a low-rank approximation to the sentence-word co-occurrence matrix to intrinsically group semantically-similar lexical items. We conduct extensive experiments on datasets of student responses, product reviews, and news documents. Our approach compares favorably to a number of extractive baselines as well as a neural abstractive summarization system. The paper finally sheds light on when and why the proposed framework is effective at summarizing content with high lexical variety.
An Improved Phrase-based Approach to Annotating and Summarizing Student Course Responses
May 25, 2018



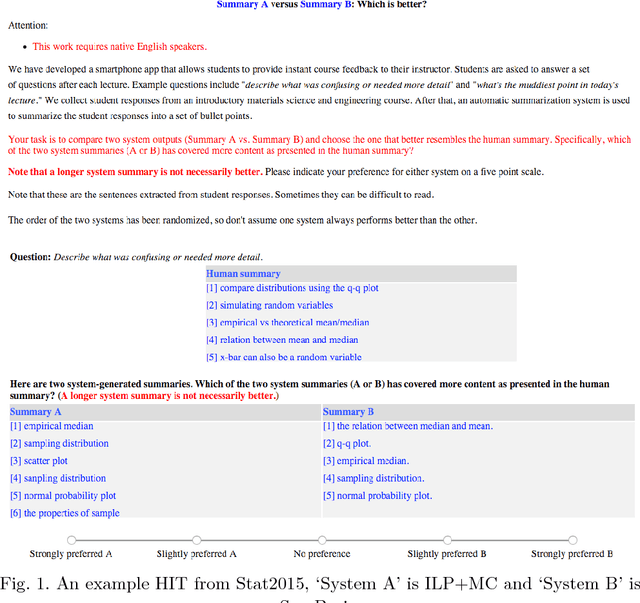
Teaching large classes remains a great challenge, primarily because it is difficult to attend to all the student needs in a timely manner. Automatic text summarization systems can be leveraged to summarize the student feedback, submitted immediately after each lecture, but it is left to be discovered what makes a good summary for student responses. In this work we explore a new methodology that effectively extracts summary phrases from the student responses. Each phrase is tagged with the number of students who raise the issue. The phrases are evaluated along two dimensions: with respect to text content, they should be informative and well-formed, measured by the ROUGE metric; additionally, they shall attend to the most pressing student needs, measured by a newly proposed metric. This work is enabled by a phrase-based annotation and highlighting scheme, which is new to the summarization task. The phrase-based framework allows us to summarize the student responses into a set of bullet points and present to the instructor promptly.
Automatic Summarization of Student Course Feedback
May 25, 2018
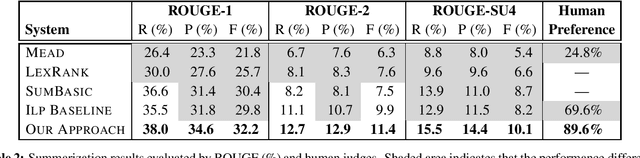
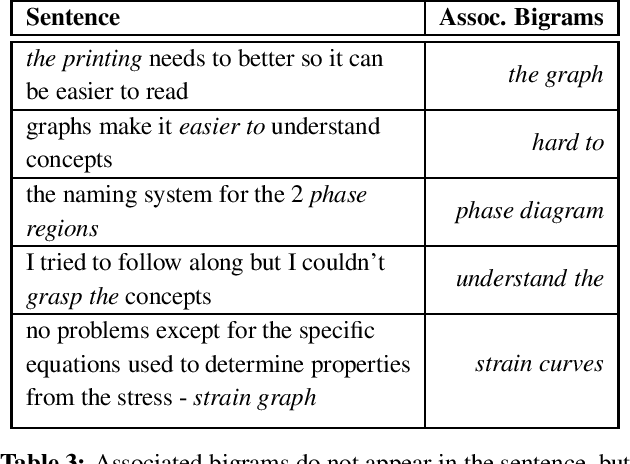

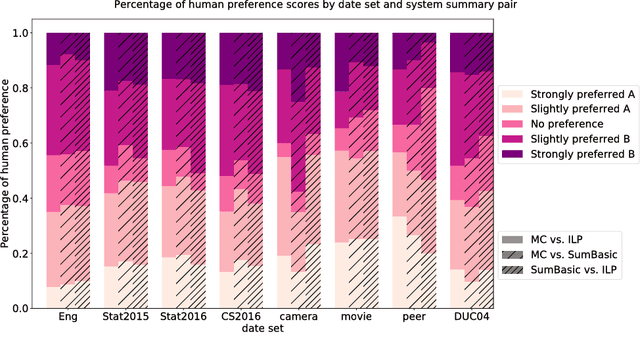
Student course feedback is generated daily in both classrooms and online course discussion forums. Traditionally, instructors manually analyze these responses in a costly manner. In this work, we propose a new approach to summarizing student course feedback based on the integer linear programming (ILP) framework. Our approach allows different student responses to share co-occurrence statistics and alleviates sparsity issues. Experimental results on a student feedback corpus show that our approach outperforms a range of baselines in terms of both ROUGE scores and human evaluation.