 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Progressive Visual-Logic-Aligned Framework for Ride-Hailing Adjudication
Mar 18, 2026The efficient adjudication of responsibility disputes is pivotal for maintaining marketplace fairness. However, the exponential surge in ride-hailing volume renders manual review intractable, while conventional automated methods lack the reasoning transparency required for quasi-judicial decisions. Although Multimodal LLMs offer a promising paradigm, they fundamentally struggle to bridge the gap between general visual semantics and rigorous evidentiary protocols, often leading to perceptual hallucinations and logical looseness. To address these systemic misalignments, we introduce RideJudge, a Progressive Visual-Logic-Aligned Framework. Instead of relying on generic pre-training, we bridge the semantic gap via SynTraj, a synthesis engine that grounds abstract liability concepts into concrete trajectory patterns. To resolve the conflict between massive regulation volume and limited context windows, we propose an Adaptive Context Optimization strategy that distills expert knowledge, coupled with a Chain-of-Adjudication mechanism to enforce active evidentiary inquiry. Furthermore, addressing the inadequacy of sparse binary feedback for complex liability assessment, we implement a novel Ordinal-Sensitive Reinforcement Learning mechanism that calibrates decision boundaries against hierarchical severity. Extensive experiments show that our RideJudge-8B achieves 88.41\% accuracy, surpassing 32B-scale baselines and establishing a new standard for interpretable adjudication.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
NeSyGeo: A Neuro-Symbolic Framework for Multimodal Geometric Reasoning Data Generation
May 21, 2025



Obtaining large-scale, high-quality data with reasoning paths is crucial for improving the geometric reasoning capabilities of multi-modal large language models (MLLMs). However, existing data generation methods, whether based on predefined templates or constrained symbolic provers, inevitably face diversity and numerical generalization limitations. To address these limitations, we propose NeSyGeo, a novel neuro-symbolic framework for generating geometric reasoning data. First, we propose a domain-specific language grounded in the entity-relation-constraint paradigm to comprehensively represent all components of plane geometry, along with generative actions defined within this symbolic space. We then design a symbolic-visual-text pipeline that synthesizes symbolic sequences, maps them to corresponding visual and textual representations, and generates diverse question-answer (Q&A) pairs using large language models (LLMs). To the best of our knowledge, we are the first to propose a neuro-symbolic approach in generating multimodal reasoning data. Based on this framework, we construct NeSyGeo-CoT and NeSyGeo-Caption datasets, containing 100k samples, and release a new benchmark NeSyGeo-Test for evaluating geometric reasoning abilities in MLLMs. Experiments demonstrate that the proposal significantly and consistently improves the performance of multiple MLLMs under both reinforcement and supervised fine-tuning. With only 4k samples and two epochs of reinforcement fine-tuning, base models achieve improvements of up to +15.8% on MathVision, +8.4% on MathVerse, and +7.3% on GeoQA. Notably, a 4B model can be improved to outperform an 8B model from the same series on geometric reasoning tasks.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Generalizing Teacher Networks for Effective Knowledge Distillation Across Student Architectures
Jul 22, 2024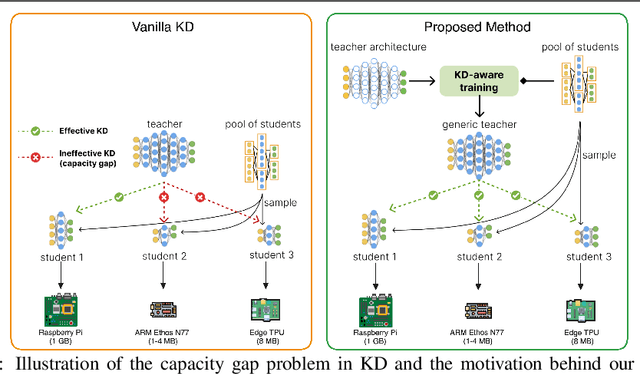

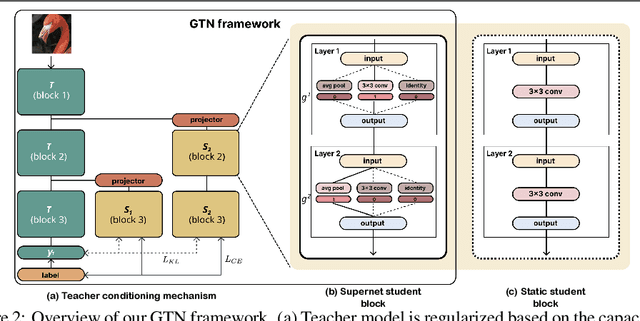
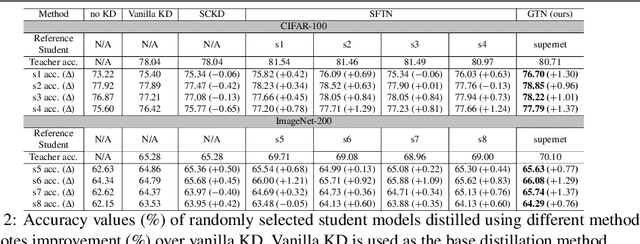
Knowledge distillation (KD) is a model compression method that entails training a compact student model to emulate the performance of a more complex teacher model. However, the architectural capacity gap between the two models limits the effectiveness of knowledge transfer. Addressing this issue, previous works focused on customizing teacher-student pairs to improve compatibility, a computationally expensive process that needs to be repeated every time either model changes. Hence, these methods are impractical when a teacher model has to be compressed into different student models for deployment on multiple hardware devices with distinct resource constraints. In this work, we propose Generic Teacher Network (GTN), a one-off KD-aware training to create a generic teacher capable of effectively transferring knowledge to any student model sampled from a given finite pool of architectures. To this end, we represent the student pool as a weight-sharing supernet and condition our generic teacher to align with the capacities of various student architectures sampled from this supernet. Experimental evaluation shows that our method both improves overall KD effectiveness and amortizes the minimal additional training cost of the generic teacher across students in the pool.