 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM100: An Orchestrated Dataflow Architecture Powering General AI Computing
Apr 20, 2026As deep learning-based AI technologies gain momentum, the demand for general-purpose AI computing architectures continues to grow. While GPGPU-based architectures offer versatility for diverse AI workloads, they often fall short in efficiency and cost-effectiveness. Various Domain-Specific Architectures (DSAs) excel at particular AI tasks but struggle to extend across broader applications or adapt to the rapidly evolving AI landscape. M100 is Li Auto's response: a performant, cost-effective architecture for AI inference in Autonomous Driving (AD), Large Language Models (LLMs), and intelligent human interactions, domains crucial to today's most competitive automobile platforms. M100 employs a dataflow parallel architecture, where compiler-architecture co-design orchestrates not only computation but, more critically, data movement across time and space. Leveraging dataflow computing efficiency, our hardware-software co-design improves system performance while reducing hardware complexity and cost. M100 largely eliminates caching: tensor computations are driven by compiler- and runtime-managed data streams flowing between computing elements and on/off-chip memories, yielding greater efficiency and scalability than cache-based systems. Another key principle was selecting the right operational granularity for scheduling, issuing, and execution across compiler, firmware, and hardware. Recognizing commonalities in AI workloads, we chose the tensor as the fundamental data element. M100 demonstrates general AI computing capability across diverse inference applications, including UniAD (for AD) and LLaMA (for LLMs). Benchmarks show M100 outperforms GPGPU architectures in AD applications with higher utilization, representing a promising direction for future general AI computing.
Beyond Prompt: Fine-grained Simulation of Cognitively Impaired Standardized Patients via Stochastic Steering
Apr 14, 2026Simulating Standardized Patients with cognitive impairment offers a scalable and ethical solution for clinical training. However, existing methods rely on discrete prompt engineering and fail to capture the heterogeneity of deficits across varying domains and severity levels. To address this limitation, we propose StsPatient for the fine-grained simulation of cognitively impaired patients. We innovatively capture domain-specific features by extracting steering vectors from contrastive pairs of instructions and responses. Furthermore, we introduce a Stochastic Token Modulation (STM) mechanism to regulate the intervention probability. STM enables precise control over impairment severity while mitigating the instability of conventional vector methods. Comprehensive experiments demonstrate that StsPatient significantly outperforms baselines in both clinical authenticity and severity controllability.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
Optically-triggered deterministic spiking regimes in nanostructure resonant tunnelling diode-photodetectors
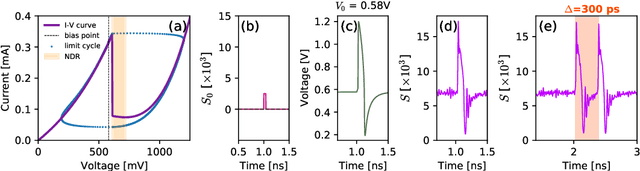
Apr 23, 2023This work reports a nanostructure resonant tunnelling diode-photodetector (RTD-PD) device and demonstrates its operation as a controllable, optically-triggered excitable spike generator. The top contact layer of the device is designed with a nanopillar structure 500 nm in diameter) to restrain the injection current, yielding therefore lower energy operation for spike generation. We demonstrate experimentally the deterministic optical triggering of controllable and repeatable neuron-like spike patterns in the nanostructure RTD-PDs. Moreover, we show the device's ability to deliver spiking responses when biased in both regions adjacent to the negative differential conductance (NDC) region, the so-called 'peak' and 'valley' points of the current-voltage ($I$-$V$) characteristic. This work also demonstrates experimentally key neuron-like dynamical features in the nanostructure RTD-PD, such as a well-defined threshold (in input optical intensity) for spike firing, as well as the presence of spike firing refractory time. The optoelectronic and chip-scale character of the proposed system together with the deterministic, repeatable and well controllable nature of the optically-elicited spiking responses render this nanostructure RTD-PD element as a highly promising solution for high-speed, energy-efficient optoelectronic artificial spiking neurons for novel light-enabled neuromorphic computing hardware.
Artificial optoelectronic spiking neuron based on a resonant tunnelling diode coupled to a vertical cavity surface emitting laser
Jun 22, 2022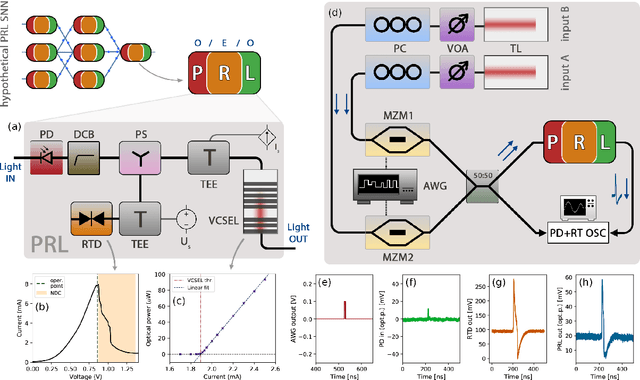
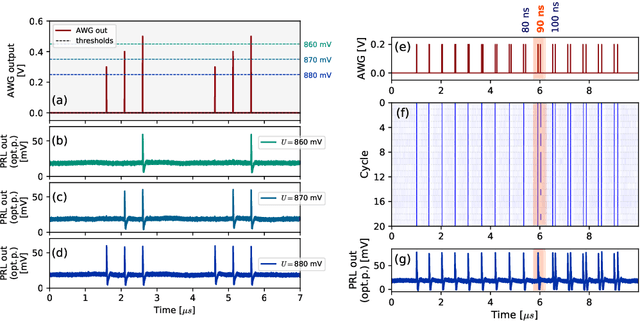
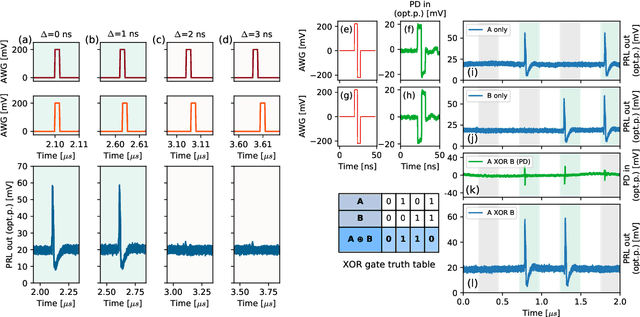
Excitable optoelectronic devices represent one of the key building blocks for implementation of artificial spiking neurons in neuromorphic (brain-inspired) photonic systems. This work introduces and experimentally investigates an opto-electro-optical (O/E/O) artificial neuron built with a resonant tunnelling diode (RTD) coupled to a photodetector as a receiver and a vertical cavity surface emitting laser as a the transmitter. We demonstrate a well defined excitability threshold, above which this neuron produces 100 ns optical spiking responses with characteristic neural-like refractory period. We utilise its fan-in capability to perform in-device coincidence detection (logical AND) and exclusive logical OR (XOR) tasks. These results provide first experimental validation of deterministic triggering and tasks in an RTD-based spiking optoelectronic neuron with both input and output optical (I/O) terminals. Furthermore, we also investigate in theory the prospects of the proposed system for its nanophotonic implementation with a monolithic design combining a nanoscale RTD element and a nanolaser; therefore demonstrating the potential of integrated RTD-based excitable nodes for low footprint, high-speed optoelectronic spiking neurons in future neuromorphic photonic hardware.