 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Control of a Low-cost Non-backdrivable End-effector Upper Limb Rehabilitation Device
Jun 20, 2024This paper presents the development of an upper limb end-effector based rehabilitation device for stroke patients, offering assistance or resistance along any 2-dimensional trajectory during physical therapy. It employs a non-backdrivable ball-screw-driven mechanism for enhanced control accuracy. The control system features three novel algorithms: First, the Implicit Euler velocity control algorithm (IEVC) highlighted for its state-of-the-art accuracy, stability, efficiency and generalizability in motion restriction control. Second, an Admittance Virtual Dynamics simulation algorithm that achieves a smooth and natural human interaction with the non-backdrivable end-effector. Third, a generalized impedance force calculation algorithm allowing efficient impedance control on any trajectory or area boundary. Experimental validation demonstrated the system's effectiveness in accurate end-effector position control across various trajectories and configurations. The proposed upper limb end-effector-based rehabilitation device, with its high performance and adaptability, holds significant promise for extensive clinical application, potentially improving rehabilitation outcomes for stroke patients.
QuadFormer: Quadruple Transformer for Unsupervised Domain Adaptation in Power Line Segmentation of Aerial Images
Nov 29, 2022Accurate segmentation of power lines in aerial images is essential to ensure the flight safety of aerial vehicles. Acquiring high-quality ground truth annotations for training a deep learning model is a laborious process. Therefore, developing algorithms that can leverage knowledge from labelled synthetic data to unlabelled real images is highly demanded. This process is studied in Unsupervised domain adaptation (UDA). Recent approaches to self-training have achieved remarkable performance in UDA for semantic segmentation, which trains a model with pseudo labels on the target domain. However, the pseudo labels are noisy due to a discrepancy in the two data distributions. We identify that context dependency is important for bridging this domain gap. Motivated by this, we propose QuadFormer, a novel framework designed for domain adaptive semantic segmentation. The hierarchical quadruple transformer combines cross-attention and self-attention mechanisms to adapt transferable context. Based on cross-attentive and self-attentive feature representations, we introduce a pseudo label correction scheme to online denoise the pseudo labels and reduce the domain gap. Additionally, we present two datasets - ARPLSyn and ARPLReal to further advance research in unsupervised domain adaptive powerline segmentation. Finally, experimental results indicate that our method achieves state-of-the-art performance for the domain adaptive power line segmentation on ARPLSyn$\rightarrow$TTTPLA and ARPLSyn$\rightarrow$ARPLReal.
Gen-LaneNet: A Generalized and Scalable Approach for 3D Lane Detection
Mar 24, 2020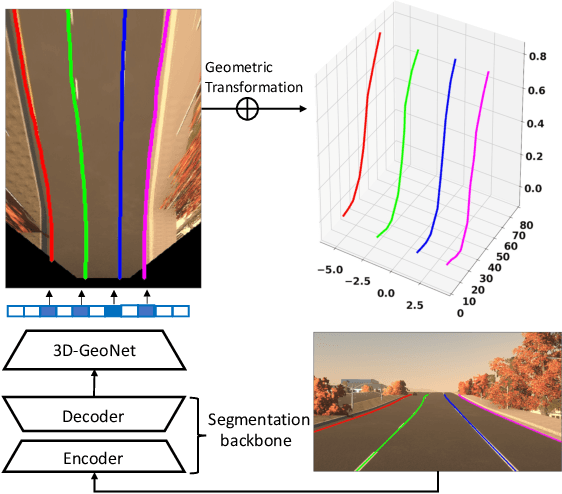
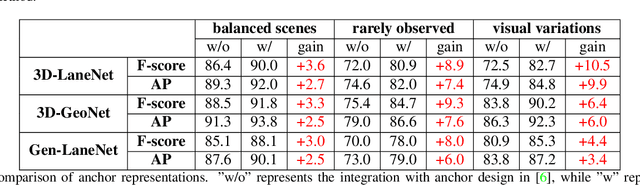
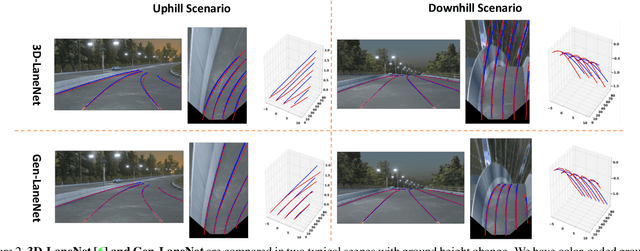
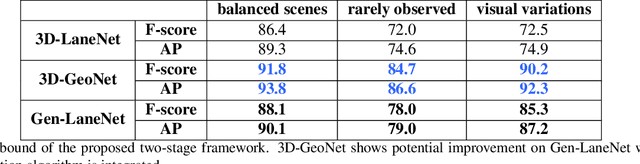
We present a generalized and scalable method, called Gen-LaneNet, to detect 3D lanes from a single image. The method, inspired by the latest state-of-the-art 3D-LaneNet, is a unified framework solving image encoding, spatial transform of features and 3D lane prediction in a single network. However, we propose unique designs for Gen-LaneNet in two folds. First, we introduce a new geometry-guided lane anchor representation in a new coordinate frame and apply a specific geometric transformation to directly calculate real 3D lane points from the network output. We demonstrate that aligning the lane points with the underlying top-view features in the new coordinate frame is critical towards a generalized method in handling unfamiliar scenes. Second, we present a scalable two-stage framework that decouples the learning of image segmentation subnetwork and geometry encoding subnetwork. Compared to 3D-LaneNet, the proposed Gen-LaneNet drastically reduces the amount of 3D lane labels required to achieve a robust solution in real-world application. Moreover, we release a new synthetic dataset and its construction strategy to encourage the development and evaluation of 3D lane detection methods. In experiments, we conduct extensive ablation study to substantiate the proposed Gen-LaneNet significantly outperforms 3D-LaneNet in average precision(AP) and F-score.