 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025



Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
Federated Learning for Semantic Parsing: Task Formulation, Evaluation Setup, New Algorithms
May 26, 2023This paper studies a new task of federated learning (FL) for semantic parsing, where multiple clients collaboratively train one global model without sharing their semantic parsing data. By leveraging data from multiple clients, the FL paradigm can be especially beneficial for clients that have little training data to develop a data-hungry neural semantic parser on their own. We propose an evaluation setup to study this task, where we re-purpose widely-used single-domain text-to-SQL datasets as clients to form a realistic heterogeneous FL setting and collaboratively train a global model. As standard FL algorithms suffer from the high client heterogeneity in our realistic setup, we further propose a novel LOss Reduction Adjusted Re-weighting (Lorar) mechanism to mitigate the performance degradation, which adjusts each client's contribution to the global model update based on its training loss reduction during each round. Our intuition is that the larger the loss reduction, the further away the current global model is from the client's local optimum, and the larger weight the client should get. By applying Lorar to three widely adopted FL algorithms (FedAvg, FedOPT and FedProx), we observe that their performance can be improved substantially on average (4%-20% absolute gain under MacroAvg) and that clients with smaller datasets enjoy larger performance gains. In addition, the global model converges faster for almost all the clients.
Model Pruning Enables Efficient Federated Learning on Edge Devices
Sep 26, 2019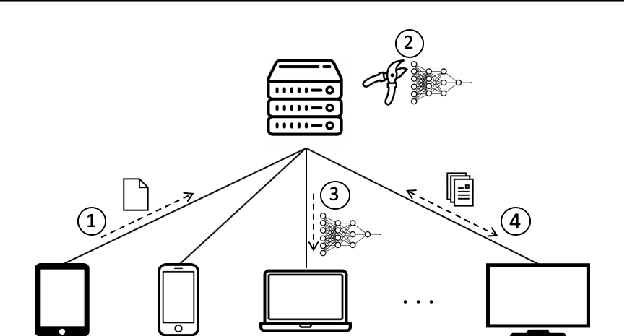
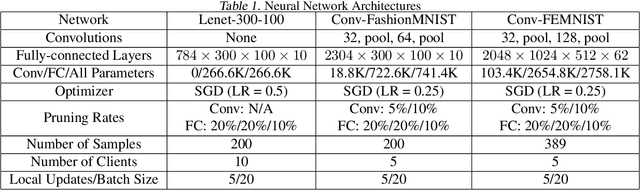
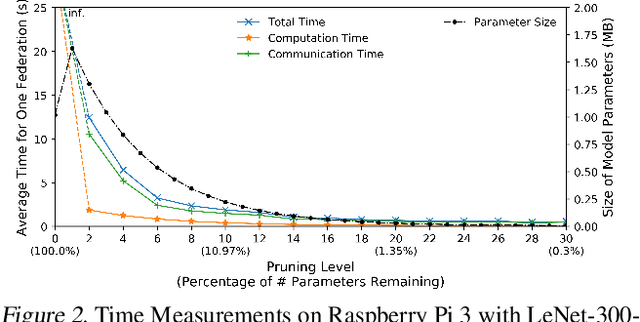
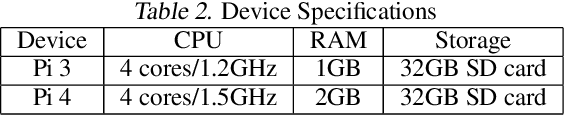
Federated learning is a recent approach for distributed model training without sharing the raw data of clients. It allows model training using the large amount of user data collected by edge and mobile devices, while preserving data privacy. A challenge in federated learning is that the devices usually have much lower computational power and communication bandwidth than machines in data centers. Training large-sized deep neural networks in such a federated setting can consume a large amount of time and resources. To overcome this challenge, we propose a method that integrates model pruning with federated learning in this paper, which includes initial model pruning at the server, further model pruning as part of the federated learning process, followed by the regular federated learning procedure. Our proposed approach can save the computation, communication, and storage costs compared to standard federated learning approaches. Extensive experiments on real edge devices validate the benefit of our proposed method.
Time Series Segmentation through Automatic Feature Learning
Jan 26, 2018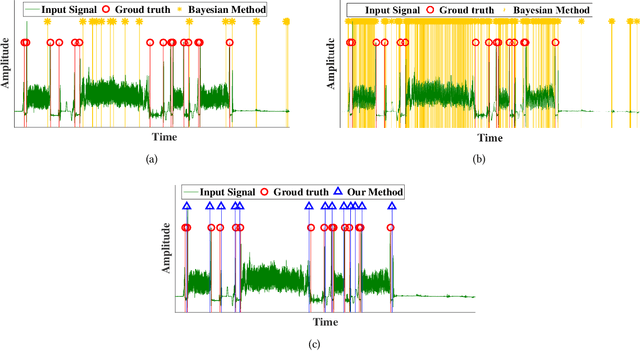
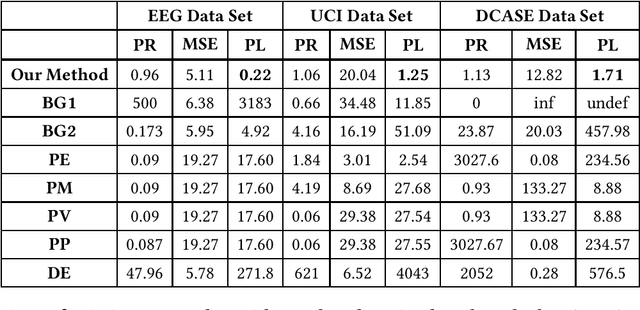
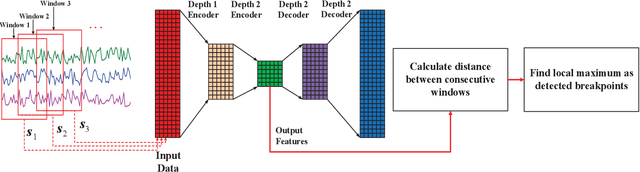
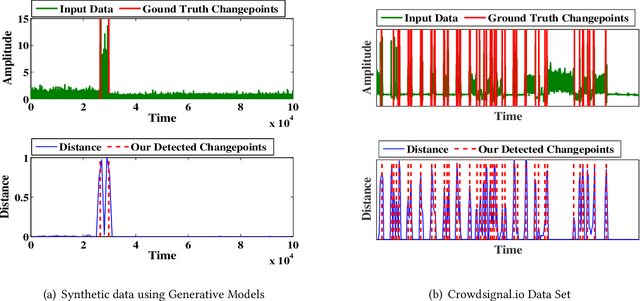
Internet of things (IoT) applications have become increasingly popular in recent years, with applications ranging from building energy monitoring to personal health tracking and activity recognition. In order to leverage these data, automatic knowledge extraction - whereby we map from observations to interpretable states and transitions - must be done at scale. As such, we have seen many recent IoT data sets include annotations with a human expert specifying states, recorded as a set of boundaries and associated labels in a data sequence. These data can be used to build automatic labeling algorithms that produce labels as an expert would. Here, we refer to human-specified boundaries as breakpoints. Traditional changepoint detection methods only look for statistically-detectable boundaries that are defined as abrupt variations in the generative parameters of a data sequence. However, we observe that breakpoints occur on more subtle boundaries that are non-trivial to detect with these statistical methods. In this work, we propose a new unsupervised approach, based on deep learning, that outperforms existing techniques and learns the more subtle, breakpoint boundaries with a high accuracy. Through extensive experiments on various real-world data sets - including human-activity sensing data, speech signals, and electroencephalogram (EEG) activity traces - we demonstrate the effectiveness of our algorithm for practical applications. Furthermore, we show that our approach achieves significantly better performance than previous methods.