 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncated Laplacian Mechanism for Approximate Differential Privacy
Oct 01, 2018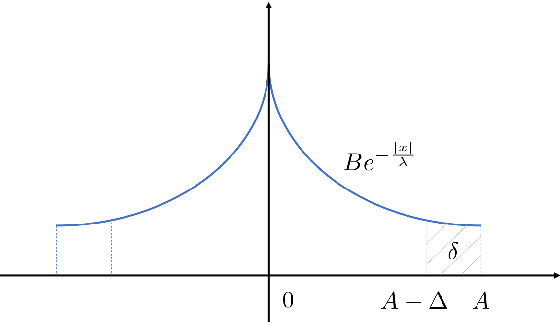
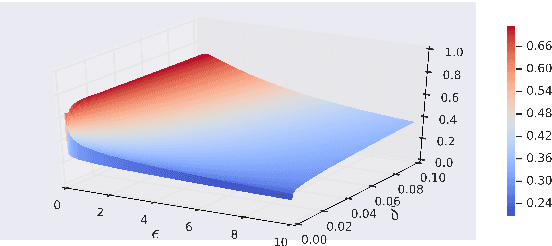
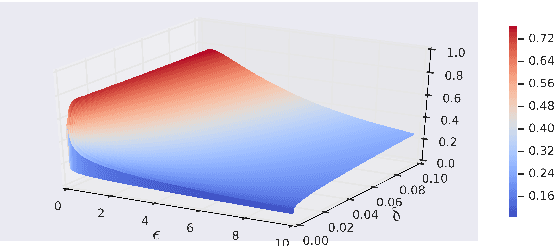
We derive a class of noise probability distributions to preserve $(\epsilon, \delta)$-differential privacy for single real-valued query function. The proposed noise distribution has a truncated exponential probability density function, which can be viewed as a truncated Laplacian distribution. We show the near-optimality of the proposed \emph{truncated Laplacian} mechanism in various privacy regimes in the context of minimizing the noise amplitude and noise power. Numeric experiments show the improvement of the truncated Laplacian mechanism over the optimal Gaussian mechanism by significantly reducing the noise amplitude and noise power in various privacy regions.
Optimal Noise-Adding Mechanism in Additive Differential Privacy
Sep 26, 2018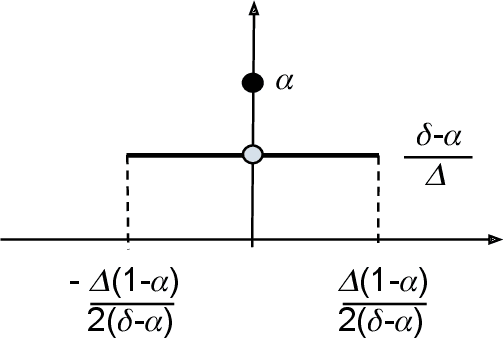

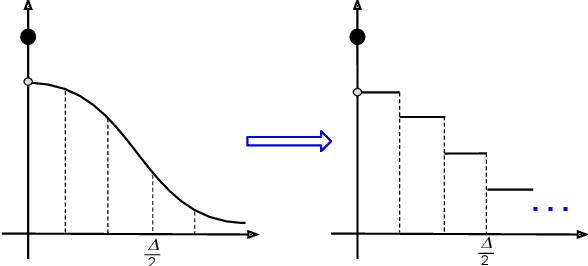
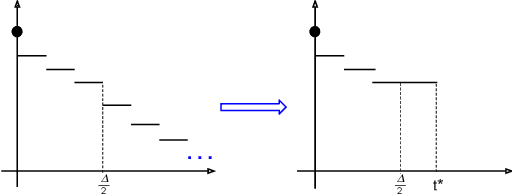
We derive the optimal $(0, \delta)$-differentially private query-output independent noise-adding mechanism for single real-valued query function under a general cost-minimization framework. Under a mild technical condition, we show that the optimal noise probability distribution is a uniform distribution with a probability mass at the origin. We explicitly derive the optimal noise distribution for general $\ell^n$ cost functions, including $\ell^1$ (for noise magnitude) and $\ell^2$ (for noise power) cost functions, and show that the probability concentration on the origin occurs when $\delta > \frac{n}{n+1}$. Our result demonstrates an improvement over the existing Gaussian mechanisms by a factor of two and three for $(0,\delta)$-differential privacy in the high privacy regime in the context of minimizing the noise magnitude and noise power, and the gain is more pronounced in the low privacy regime. Our result is consistent with the existing result for $(0,\delta)$-differential privacy in the discrete setting, and identifies a probability concentration phenomenon in the continuous setting.
A Semantic QA-Based Approach for Text Summarization Evaluation
Apr 11, 2018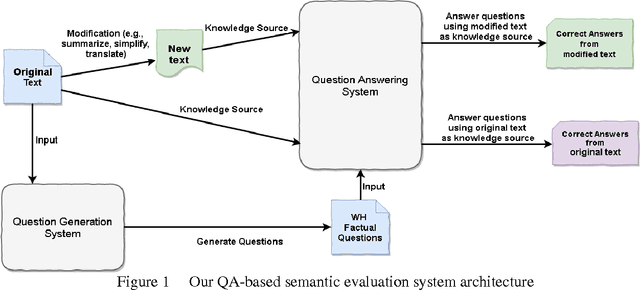
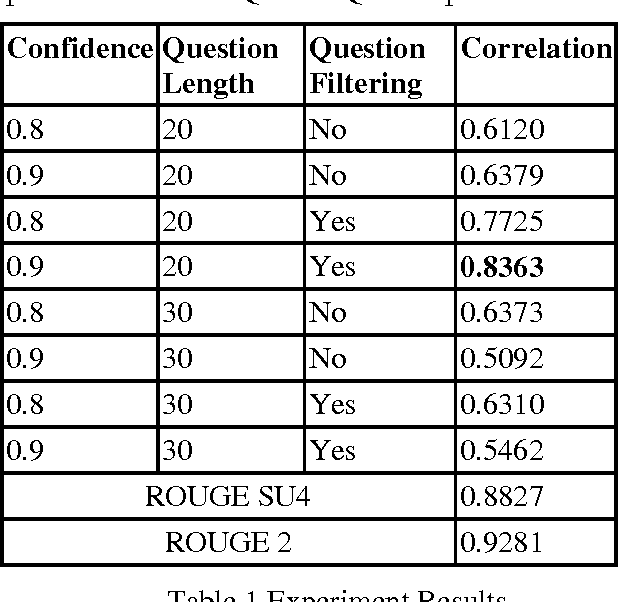
Many Natural Language Processing and Computational Linguistics applications involves the generation of new texts based on some existing texts, such as summarization, text simplification and machine translation. However, there has been a serious problem haunting these applications for decades, that is, how to automatically and accurately assess quality of these applications. In this paper, we will present some preliminary results on one especially useful and challenging problem in NLP system evaluation: how to pinpoint content differences of two text passages (especially for large pas-sages such as articles and books). Our idea is intuitive and very different from existing approaches. We treat one text passage as a small knowledge base, and ask it a large number of questions to exhaustively identify all content points in it. By comparing the correctly answered questions from two text passages, we will be able to compare their content precisely. The experiment using 2007 DUC summarization corpus clearly shows promising results.
RandomOut: Using a convolutional gradient norm to rescue convolutional filters
May 29, 2017
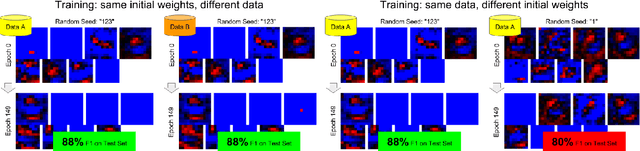
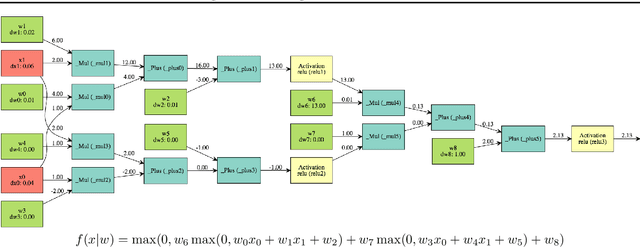
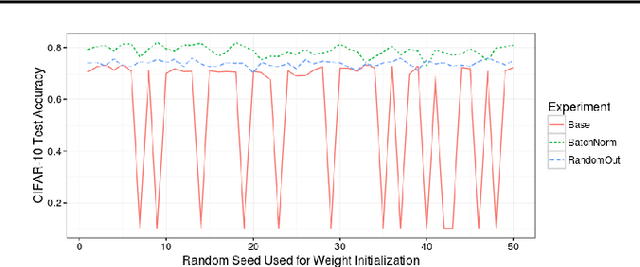
Filters in convolutional neural networks are sensitive to their initialization. The random numbers used to initialize filters are a bias and determine if you will "win" and converge to a satisfactory local minimum so we call this The Filter Lottery. We observe that the 28x28 Inception-V3 model without Batch Normalization fails to train 26% of the time when varying the random seed alone. This is a problem that affects the trial and error process of designing a network. Because random seeds have a large impact it makes it hard to evaluate a network design without trying many different random starting weights. This work aims to reduce the bias imposed by the initial weights so a network converges more consistently. We propose to evaluate and replace specific convolutional filters that have little impact on the prediction. We use the gradient norm to evaluate the impact of a filter on error, and re-initialize filters when the gradient norm of its weights falls below a specific threshold. This consistently improves accuracy on the 28x28 Inception-V3 with a median increase of +3.3%. In effect our method RandomOut increases the number of filters explored without increasing the size of the network. We observe that the RandomOut method has more consistent generalization performance, having a standard deviation of 1.3% instead of 2% when varying random seeds, and does so faster and with fewer parameters.
Bag-of-Words Method Applied to Accelerometer Measurements for the Purpose of Classification and Energy Estimation
Apr 12, 2017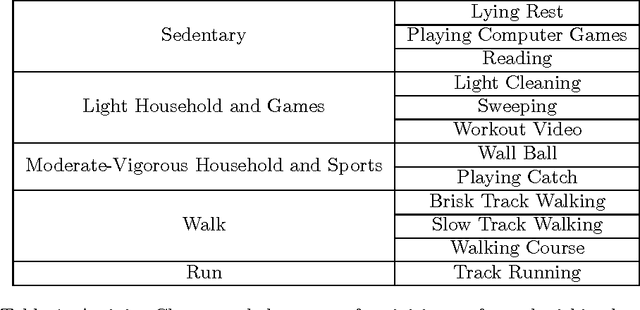
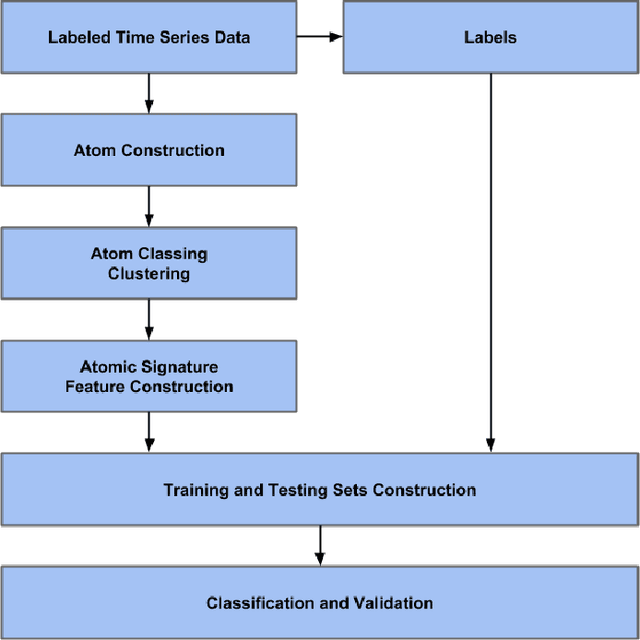
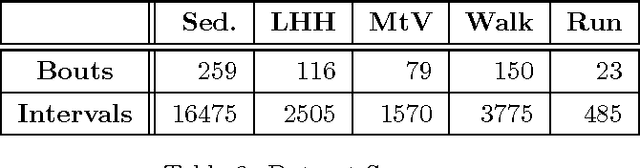
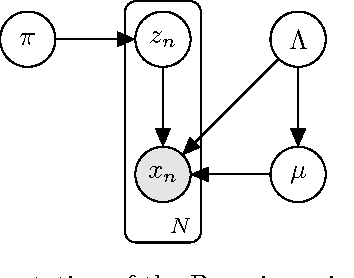
Accelerometer measurements are the prime type of sensor information most think of when seeking to measure physical activity. On the market, there are many fitness measuring devices which aim to track calories burned and steps counted through the use of accelerometers. These measurements, though good enough for the average consumer, are noisy and unreliable in terms of the precision of measurement needed in a scientific setting. The contribution of this paper is an innovative and highly accurate regression method which uses an intermediary two-stage classification step to better direct the regression of energy expenditure values from accelerometer counts. We show that through an additional unsupervised layer of intermediate feature construction, we can leverage latent patterns within accelerometer counts to provide better grounds for activity classification than expert-constructed timeseries features. For this, our approach utilizes a mathematical model originating in natural language processing, the bag-of-words model, that has in the past years been appearing in diverse disciplines outside of the natural language processing field such as image processing. Further emphasizing the natural language connection to stochastics, we use a gaussian mixture model to learn the dictionary upon which the bag-of-words model is built. Moreover, we show that with the addition of these features, we're able to improve regression root mean-squared error of energy expenditure by approximately 1.4 units over existing state-of-the-art methods.
Scalable and Accurate Online Feature Selection for Big Data
Jul 28, 2016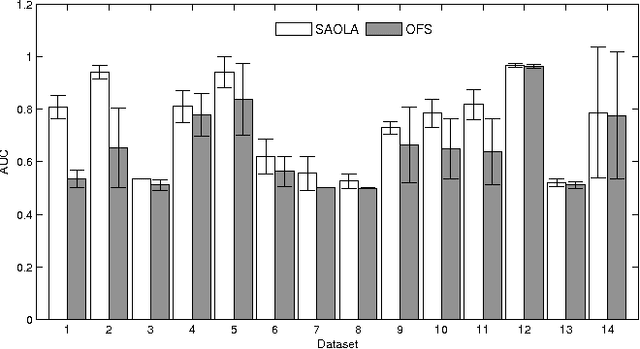
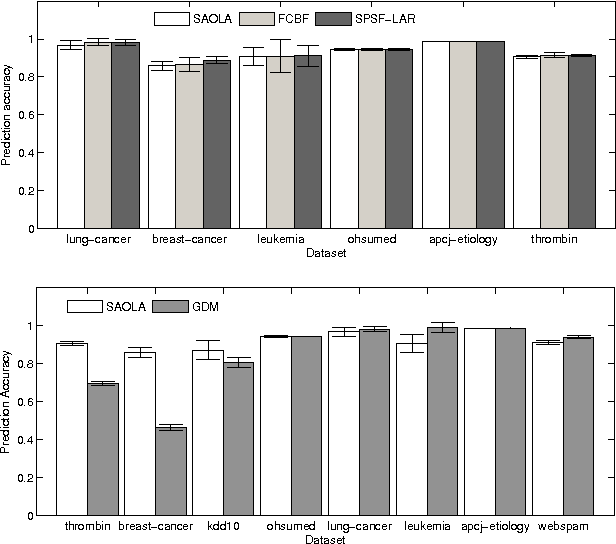
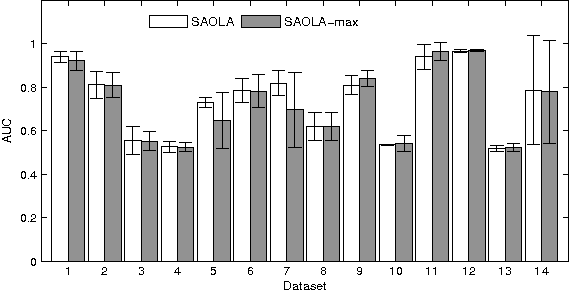
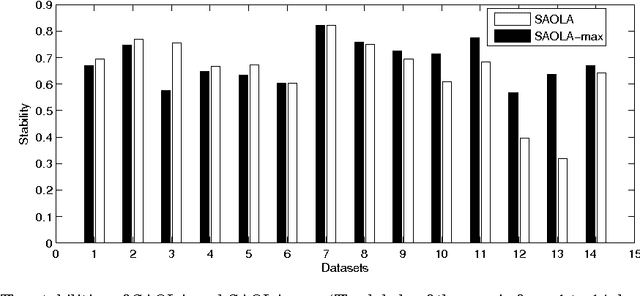
Feature selection is important in many big data applications. Two critical challenges closely associate with big data. Firstly, in many big data applications, the dimensionality is extremely high, in millions, and keeps growing. Secondly, big data applications call for highly scalable feature selection algorithms in an online manner such that each feature can be processed in a sequential scan. We present SAOLA, a Scalable and Accurate OnLine Approach for feature selection in this paper. With a theoretical analysis on bounds of the pairwise correlations between features, SAOLA employs novel pairwise comparison techniques and maintain a parsimonious model over time in an online manner. Furthermore, to deal with upcoming features that arrive by groups, we extend the SAOLA algorithm, and then propose a new group-SAOLA algorithm for online group feature selection. The group-SAOLA algorithm can online maintain a set of feature groups that is sparse at the levels of both groups and individual features simultaneously. An empirical study using a series of benchmark real data sets shows that our two algorithms, SAOLA and group-SAOLA, are scalable on data sets of extremely high dimensionality, and have superior performance over the state-of-the-art feature selection methods.
Scale Normalization
Apr 26, 2016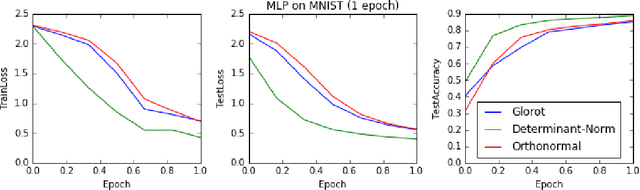
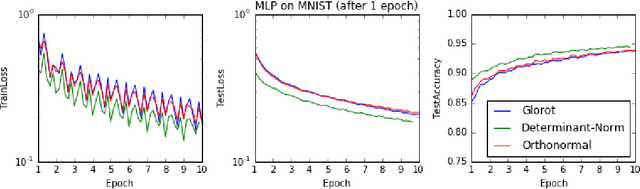
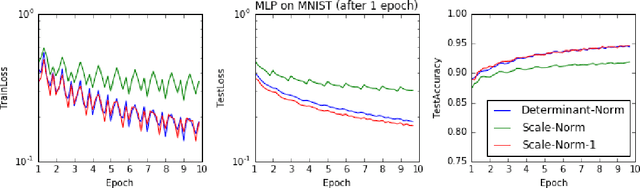
One of the difficulties of training deep neural networks is caused by improper scaling between layers. Scaling issues introduce exploding / gradient problems, and have typically been addressed by careful scale-preserving initialization. We investigate the value of preserving scale, or isometry, beyond the initial weights. We propose two methods of maintaing isometry, one exact and one stochastic. Preliminary experiments show that for both determinant and scale-normalization effectively speeds up learning. Results suggest that isometry is important in the beginning of learning, and maintaining it leads to faster learning.
Rapid building detection using machine learning
Mar 14, 2016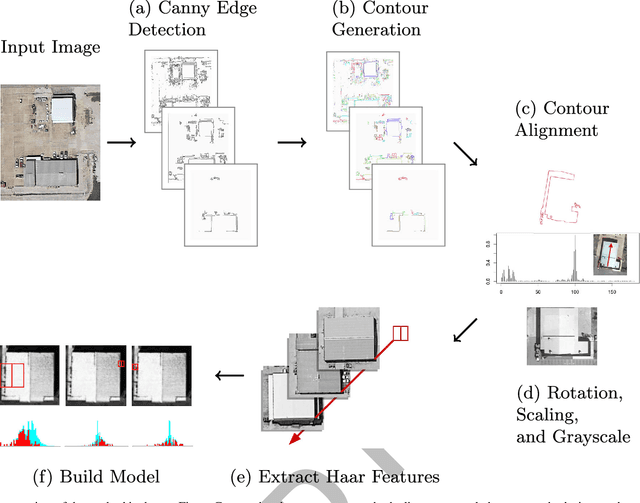
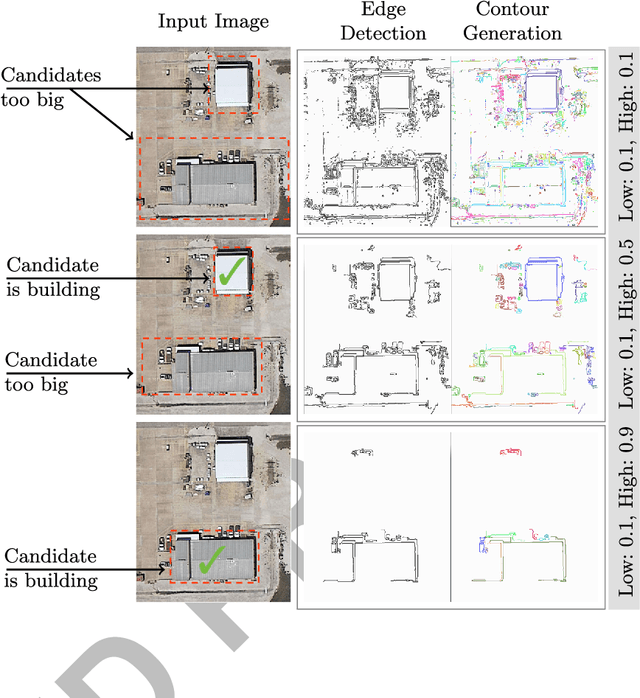
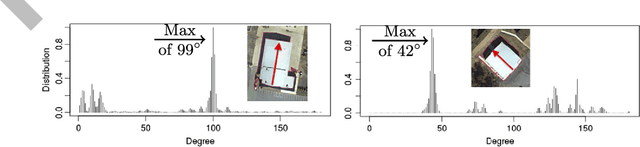
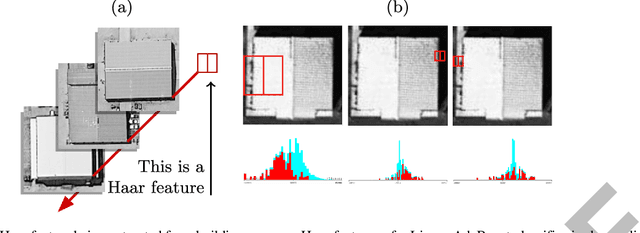
This work describes algorithms for performing discrete object detection, specifically in the case of buildings, where usually only low quality RGB-only geospatial reflective imagery is available. We utilize new candidate search and feature extraction techniques to reduce the problem to a machine learning (ML) classification task. Here we can harness the complex patterns of contrast features contained in training data to establish a model of buildings. We avoid costly sliding windows to generate candidates; instead we innovatively stitch together well known image processing techniques to produce candidates for building detection that cover 80-85% of buildings. Reducing the number of possible candidates is important due to the scale of the problem. Each candidate is subjected to classification which, although linear, costs time and prohibits large scale evaluation. We propose a candidate alignment algorithm to boost classification performance to 80-90% precision with a linear time algorithm and show it has negligible cost. Also, we propose a new concept called a Permutable Haar Mesh (PHM) which we use to form and traverse a search space to recover candidate buildings which were lost in the initial preprocessing phase.
LOFS: Library of Online Streaming Feature Selection
Mar 02, 2016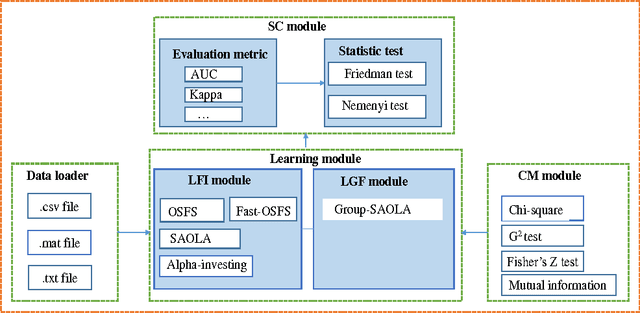
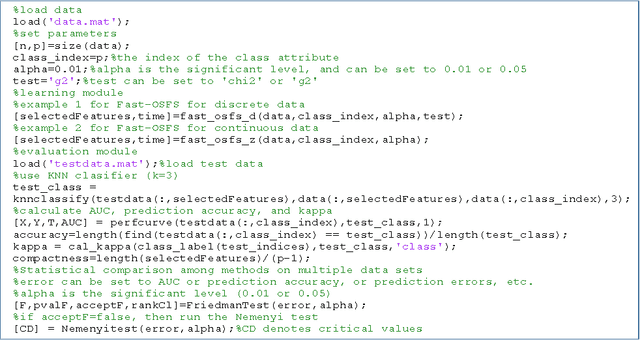
As an emerging research direction, online streaming feature selection deals with sequentially added dimensions in a feature space while the number of data instances is fixed. Online streaming feature selection provides a new, complementary algorithmic methodology to enrich online feature selection, especially targets to high dimensionality in big data analytics. This paper introduces the first comprehensive open-source library for use in MATLAB that implements the state-of-the-art algorithms of online streaming feature selection. The library is designed to facilitate the development of new algorithms in this exciting research direction and make comparisons between the new methods and existing ones available.
Crater Detection via Convolutional Neural Networks
Jan 05, 2016


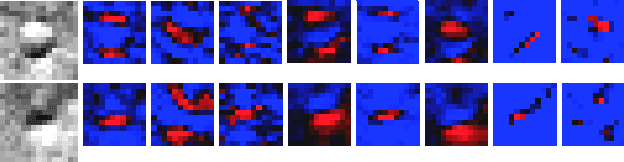
Craters are among the most studied geomorphic features in the Solar System because they yield important information about the past and present geological processes and provide information about the relative ages of observed geologic formations. We present a method for automatic crater detection using advanced machine learning to deal with the large amount of satellite imagery collected. The challenge of automatically detecting craters comes from their is complex surface because their shape erodes over time to blend into the surface. Bandeira provided a seminal dataset that embodied this challenge that is still an unsolved pattern recognition problem to this day. There has been work to solve this challenge based on extracting shape and contrast features and then applying classification models on those features. The limiting factor in this existing work is the use of hand crafted filters on the image such as Gabor or Sobel filters or Haar features. These hand crafted methods rely on domain knowledge to construct. We would like to learn the optimal filters and features based on training examples. In order to dynamically learn filters and features we look to Convolutional Neural Networks (CNNs) which have shown their dominance in computer vision. The power of CNNs is that they can learn image filters which generate features for high accuracy classification.