 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedHM: Efficient Federated Learning for Heterogeneous Models via Low-rank Factorization
Nov 29, 2021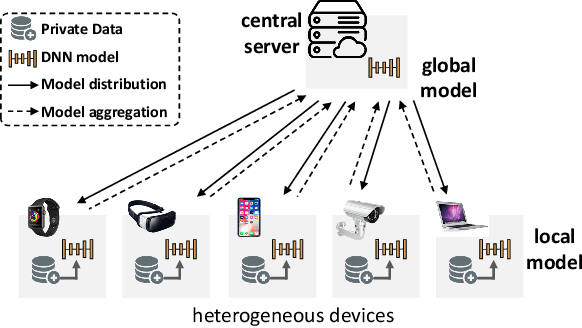

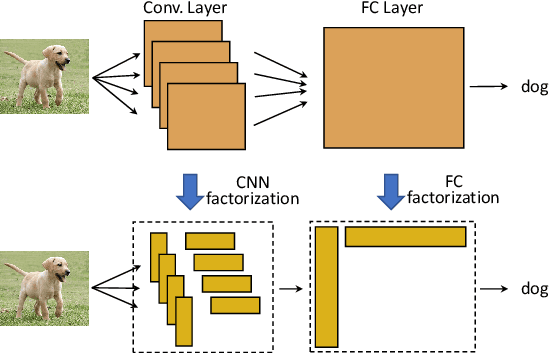
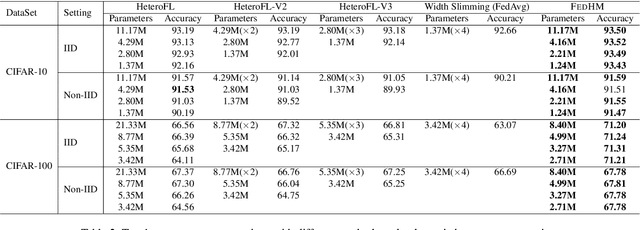
The underlying assumption of recent federated learning (FL) paradigms is that local models usually share the same network architecture as the global model, which becomes impractical for mobile and IoT devices with different setups of hardware and infrastructure. A scalable federated learning framework should address heterogeneous clients equipped with different computation and communication capabilities. To this end, this paper proposes FedHM, a novel federated model compression framework that distributes the heterogeneous low-rank models to clients and then aggregates them into a global full-rank model. Our solution enables the training of heterogeneous local models with varying computational complexities and aggregates a single global model. Furthermore, FedHM not only reduces the computational complexity of the device, but also reduces the communication cost by using low-rank models. Extensive experimental results demonstrate that our proposed \system outperforms the current pruning-based FL approaches in terms of test Top-1 accuracy (4.6% accuracy gain on average), with smaller model size (1.5x smaller on average) under various heterogeneous FL settings.
Global Knowledge Distillation in Federated Learning
Jun 30, 2021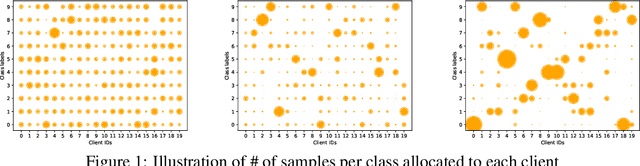
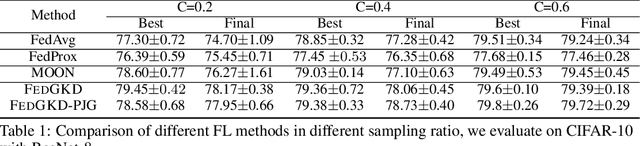
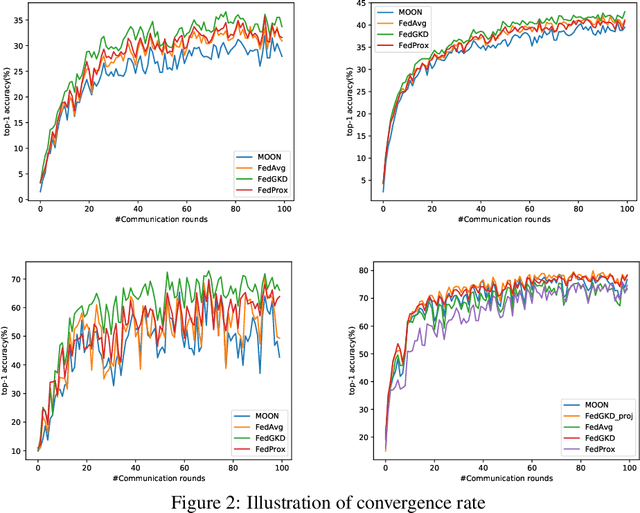
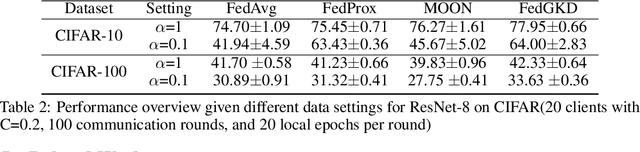
Knowledge distillation has caught a lot of attention in Federated Learning (FL) recently. It has the advantage for FL to train on heterogeneous clients which have different data size and data structure. However, data samples across all devices are usually not independent and identically distributed (non-i.i.d), posing additional challenges to the convergence and speed of federated learning. As FL randomly asks the clients to join the training process and each client only learns from local non-i.i.d data, which makes learning processing even slower. In order to solve this problem, an intuitive idea is using the global model to guide local training. In this paper, we propose a novel global knowledge distillation method, named FedGKD, which learns the knowledge from past global models to tackle down the local bias training problem. By learning from global knowledge and consistent with current local models, FedGKD learns a global knowledge model in FL. To demonstrate the effectiveness of the proposed method, we conduct extensive experiments on various CV datasets (CIFAR-10/100) and settings (non-i.i.d data). The evaluation results show that FedGKD outperforms previous state-of-the-art methods.