 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Semantic Querying of Text
May 03, 2018
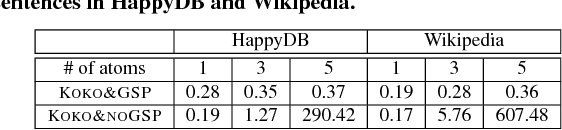
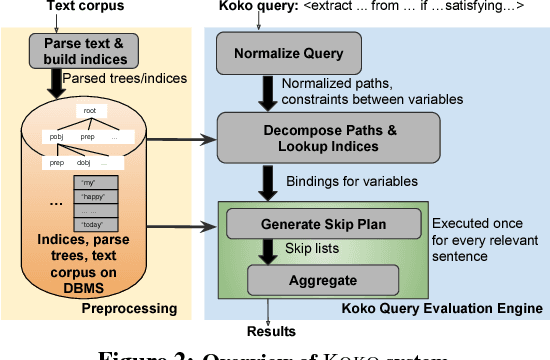
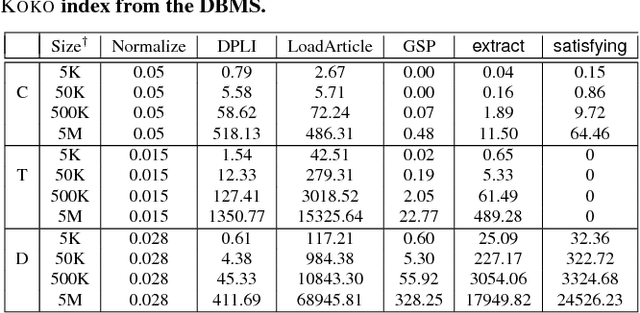
We present the KOKO system that takes declarative information extraction to a new level by incorporating advances in natural language processing techniques in its extraction language. KOKO is novel in that its extraction language simultaneously supports conditions on the surface of the text and on the structure of the dependency parse tree of sentences, thereby allowing for more refined extractions. KOKO also supports conditions that are forgiving to linguistic variation of expressing concepts and allows to aggregate evidence from the entire document in order to filter extractions. To scale up, KOKO exploits a multi-indexing scheme and heuristics for efficient extractions. We extensively evaluate KOKO over publicly available text corpora. We show that KOKO indices take up the smallest amount of space, are notably faster and more effective than a number of prior indexing schemes. Finally, we demonstrate KOKO's scale up on a corpus of 5 million Wikipedia articles.
HappyDB: A Corpus of 100,000 Crowdsourced Happy Moments
Jan 25, 2018
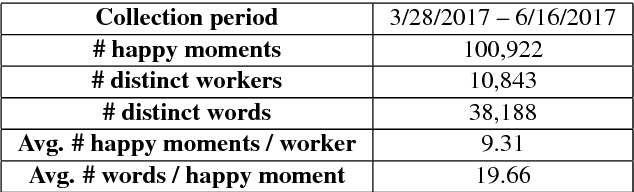
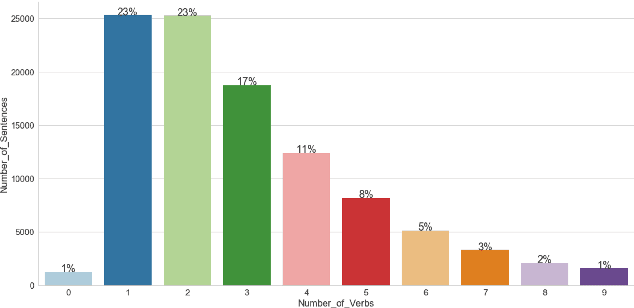
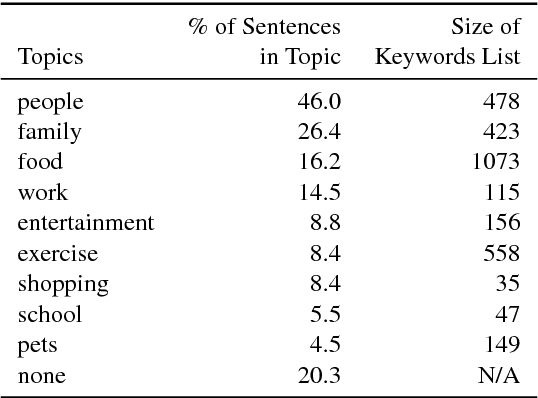
The science of happiness is an area of positive psychology concerned with understanding what behaviors make people happy in a sustainable fashion. Recently, there has been interest in developing technologies that help incorporate the findings of the science of happiness into users' daily lives by steering them towards behaviors that increase happiness. With the goal of building technology that can understand how people express their happy moments in text, we crowd-sourced HappyDB, a corpus of 100,000 happy moments that we make publicly available. This paper describes HappyDB and its properties, and outlines several important NLP problems that can be studied with the help of the corpus. We also apply several state-of-the-art analysis techniques to analyze HappyDB. Our results demonstrate the need for deeper NLP techniques to be developed which makes HappyDB an exciting resource for follow-on research.
Towards a query language for annotation graphs
Jul 13, 2000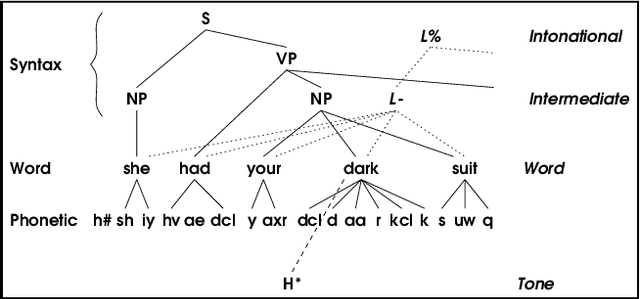
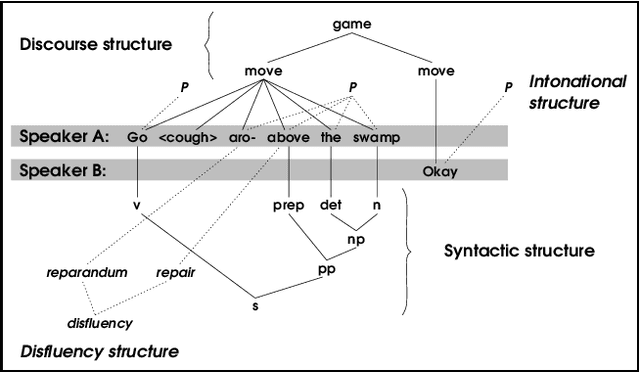

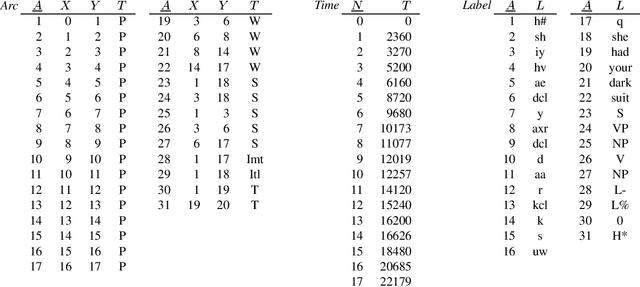
The multidimensional, heterogeneous, and temporal nature of speech databases raises interesting challenges for representation and query. Recently, annotation graphs have been proposed as a general-purpose representational framework for speech databases. Typical queries on annotation graphs require path expressions similar to those used in semistructured query languages. However, the underlying model is rather different from the customary graph models for semistructured data: the graph is acyclic and unrooted, and both temporal and inclusion relationships are important. We develop a query language and describe optimization techniques for an underlying relational representation.
* 8 pages, 10 figures