 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvizo: Arabic Handwritten Document Optical Character Recognition Solution
Feb 07, 2025Converting images of Arabic text into plain text is a widely researched topic in academia and industry. However, recognition of Arabic handwritten and printed text presents difficult challenges due to the complex nature of variations of the Arabic script. This work proposes an end-to-end solution for recognizing Arabic handwritten, printed, and Arabic numbers and presents the data in a structured manner. We reached 81.66% precision, 78.82% Recall, and 79.07% F-measure on a Text Detection task that powers the proposed solution. The proposed recognition model incorporates state-of-the-art CNN-based feature extraction, and Transformer-based sequence modeling to accommodate variations in handwriting styles, stroke thicknesses, alignments, and noise conditions. The evaluation of the model suggests its strong performances on both printed and handwritten texts, yielding 0.59% CER and & 1.72% WER on printed text, and 7.91% CER and 31.41% WER on handwritten text. The overall proposed solution has proven to be relied on in real-life OCR tasks. Equipped with both detection and recognition models as well as other Feature Extraction and Matching helping algorithms. With the general purpose implementation, making the solution valid for any given document or receipt that is Arabic handwritten or printed. Thus, it is practical and useful for any given context.
Guided Code Generation with LLMs: A Multi-Agent Framework for Complex Code Tasks
Jan 11, 2025Large Language Models (LLMs) have shown remarkable capabilities in code generation tasks, yet they face significant limitations in handling complex, long-context programming challenges and demonstrating complex compositional reasoning abilities. This paper introduces a novel agentic framework for ``guided code generation'' that tries to address these limitations through a deliberately structured, fine-grained approach to code generation tasks. Our framework leverages LLMs' strengths as fuzzy searchers and approximate information retrievers while mitigating their weaknesses in long sequential reasoning and long-context understanding. Empirical evaluation using OpenAI's HumanEval benchmark with Meta's Llama 3.1 8B model (int4 precision) demonstrates a 23.79\% improvement in solution accuracy compared to direct one-shot generation. Our results indicate that structured, guided approaches to code generation can significantly enhance the practical utility of LLMs in software development while overcoming their inherent limitations in compositional reasoning and context handling.
* 4 pages, 3 figures
Arabic Music Classification and Generation using Deep Learning
Oct 25, 2024



This paper proposes a machine learning approach for classifying classical and new Egyptian music by composer and generating new similar music. The proposed system utilizes a convolutional neural network (CNN) for classification and a CNN autoencoder for generation. The dataset used in this project consists of new and classical Egyptian music pieces composed by different composers. To classify the music by composer, each sample is normalized and transformed into a mel spectrogram. The CNN model is trained on the dataset using the mel spectrograms as input features and the composer labels as output classes. The model achieves 81.4\% accuracy in classifying the music by composer, demonstrating the effectiveness of the proposed approach. To generate new music similar to the original pieces, a CNN autoencoder is trained on a similar dataset. The model is trained to encode the mel spectrograms of the original pieces into a lower-dimensional latent space and then decode them back into the original mel spectrogram. The generated music is produced by sampling from the latent space and decoding the samples back into mel spectrograms, which are then transformed into audio. In conclusion, the proposed system provides a promising approach to classifying and generating classical Egyptian music, which can be applied in various musical applications, such as music recommendation systems, music production, and music education.
Video Summarization Techniques: A Comprehensive Review
Oct 06, 2024The rapid expansion of video content across a variety of industries, including social media, education, entertainment, and surveillance, has made video summarization an essential field of study. The current work is a survey that explores the various approaches and methods created for video summarizing, emphasizing both abstractive and extractive strategies. The process of extractive summarization involves the identification of key frames or segments from the source video, utilizing methods such as shot boundary recognition, and clustering. On the other hand, abstractive summarization creates new content by getting the essential content from the video, using machine learning models like deep neural networks and natural language processing, reinforcement learning, attention mechanisms, generative adversarial networks, and multi-modal learning. We also include approaches that incorporate the two methodologies, along with discussing the uses and difficulties encountered in real-world implementations. The paper also covers the datasets used to benchmark these techniques. This review attempts to provide a state-of-the-art thorough knowledge of the current state and future directions of video summarization research.
Automated Detection of Defects on Metal Surfaces using Vision Transformers
Oct 06, 2024



Metal manufacturing often results in the production of defective products, leading to operational challenges. Since traditional manual inspection is time-consuming and resource-intensive, automatic solutions are needed. The study utilizes deep learning techniques to develop a model for detecting metal surface defects using Vision Transformers (ViTs). The proposed model focuses on the classification and localization of defects using a ViT for feature extraction. The architecture branches into two paths: classification and localization. The model must approach high classification accuracy while keeping the Mean Square Error (MSE) and Mean Absolute Error (MAE) as low as possible in the localization process. Experimental results show that it can be utilized in the process of automated defects detection, improve operational efficiency, and reduce errors in metal manufacturing.
Context-Based Meta Reinforcement Learning for Robust and Adaptable Peg-in-Hole Assembly Tasks
Sep 24, 2024



Peg-in-hole assembly in unknown environments is a challenging task due to onboard sensor errors, which result in uncertainty and variations in task parameters such as the hole position and orientation. Meta Reinforcement Learning (Meta RL) has been proposed to mitigate this problem as it learns how to quickly adapt to new tasks with different parameters. However, previous approaches either depend on a sample-inefficient procedure or human demonstrations to perform the task in the real world. Our work modifies the data used by the Meta RL agent and uses simple features that can be easily measured in the real world even with an uncalibrated camera. We further adapt the Meta RL agent to use data from a force/torque sensor, instead of the camera, to perform the assembly, using a small amount of training data. Finally, we propose a fine-tuning method that consistently and safely adapts to out-of-distribution tasks with parameters that differ by a factor of 10 from the training tasks. Our results demonstrate that the proposed data modification significantly enhances the training and adaptation efficiency and enables the agent to achieve 100% success in tasks with different hole positions and orientations. Experiments on a real robot confirm that both camera- and force/torque sensor-equipped agents achieve 100% success in tasks with unknown hole positions, matching their simulation performance and validating the approach's robustness and applicability. Compared to the previous work with sample-inefficient adaptation, our proposed methods are 10 times more sample-efficient in the real-world tasks.
Precision Aquaculture: An Integrated Computer Vision and IoT Approach for Optimized Tilapia Feeding
Sep 13, 2024



Traditional fish farming practices often lead to inefficient feeding, resulting in environmental issues and reduced productivity. We developed an innovative system combining computer vision and IoT technologies for precise Tilapia feeding. Our solution uses real-time IoT sensors to monitor water quality parameters and computer vision algorithms to analyze fish size and count, determining optimal feed amounts. A mobile app enables remote monitoring and control. We utilized YOLOv8 for keypoint detection to measure Tilapia weight from length, achieving \textbf{94\%} precision on 3,500 annotated images. Pixel-based measurements were converted to centimeters using depth estimation for accurate feeding calculations. Our method, with data collection mirroring inference conditions, significantly improved results. Preliminary estimates suggest this approach could increase production up to 58 times compared to traditional farms. Our models, code, and dataset are open-source~\footnote{The code, dataset, and models are available upon reasonable request.
ArzEn-LLM: Code-Switched Egyptian Arabic-English Translation and Speech Recognition Using LLMs
Jun 26, 2024Motivated by the widespread increase in the phenomenon of code-switching between Egyptian Arabic and English in recent times, this paper explores the intricacies of machine translation (MT) and automatic speech recognition (ASR) systems, focusing on translating code-switched Egyptian Arabic-English to either English or Egyptian Arabic. Our goal is to present the methodologies employed in developing these systems, utilizing large language models such as LLama and Gemma. In the field of ASR, we explore the utilization of the Whisper model for code-switched Egyptian Arabic recognition, detailing our experimental procedures including data preprocessing and training techniques. Through the implementation of a consecutive speech-to-text translation system that integrates ASR with MT, we aim to overcome challenges posed by limited resources and the unique characteristics of the Egyptian Arabic dialect. Evaluation against established metrics showcases promising results, with our methodologies yielding a significant improvement of $56\%$ in English translation over the state-of-the-art and $9.3\%$ in Arabic translation. Since code-switching is deeply inherent in spoken languages, it is crucial that ASR systems can effectively handle this phenomenon. This capability is crucial for enabling seamless interaction in various domains, including business negotiations, cultural exchanges, and academic discourse. Our models and code are available as open-source resources. Code: \url{http://github.com/ahmedheakl/arazn-llm}}, Models: \url{http://huggingface.co/collections/ahmedheakl/arazn-llm-662ceaf12777656607b9524e}.
DroneVis: Versatile Computer Vision Library for Drones
Jun 01, 2024



This paper introduces DroneVis, a novel library designed to automate computer vision algorithms on Parrot drones. DroneVis offers a versatile set of features and provides a diverse range of computer vision tasks along with a variety of models to choose from. Implemented in Python, the library adheres to high-quality code standards, facilitating effortless customization and feature expansion according to user requirements. In addition, comprehensive documentation is provided, encompassing usage guidelines and illustrative use cases. Our documentation, code, and examples are available in https://github.com/ahmedheakl/drone-vis.
Markov Switching Model for Driver Behavior Prediction: Use cases on Smartphones
Aug 29, 2021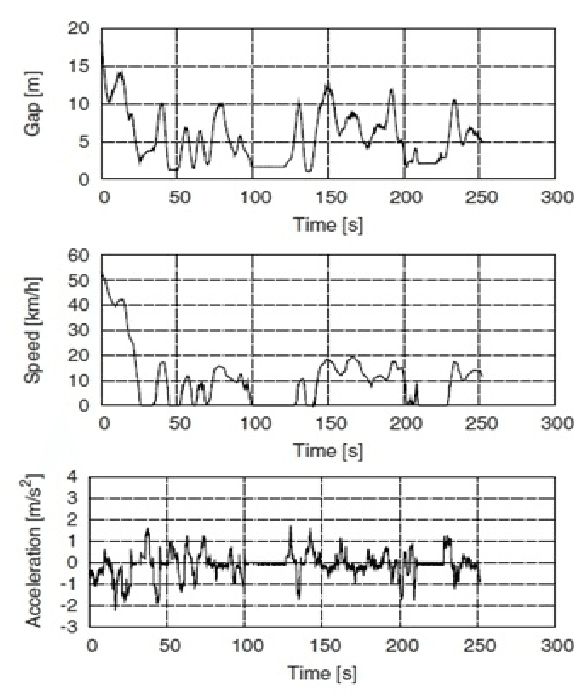


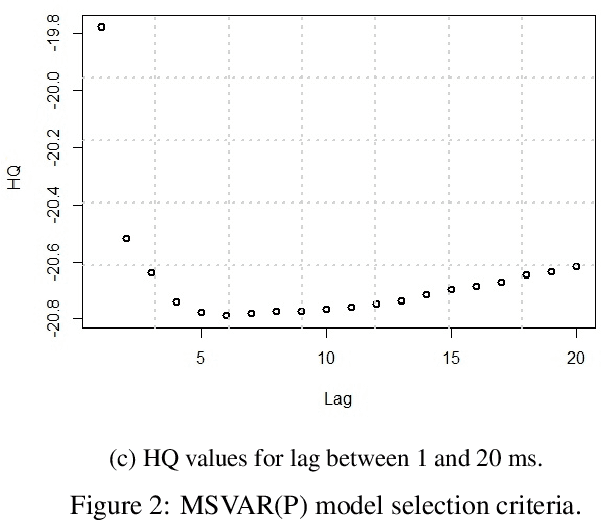
Several intelligent transportation systems focus on studying the various driver behaviors for numerous objectives. This includes the ability to analyze driver actions, sensitivity, distraction, and response time. As the data collection is one of the major concerns for learning and validating different driving situations, we present a driver behavior switching model validated by a low-cost data collection solution using smartphones. The proposed model is validated using a real dataset to predict the driver behavior in short duration periods. A literature survey on motion detection (specifically driving behavior detection using smartphones) is presented. Multiple Markov Switching Variable Auto-Regression (MSVAR) models are implemented to achieve a sophisticated fitting with the collected driver behavior data. This yields more accurate predictions not only for driver behavior but also for the entire driving situation. The performance of the presented models together with a suitable model selection criteria is also presented. The proposed driver behavior prediction framework can potentially be used in accident prediction and driver safety systems.