 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study on Energy-Efficient Edge AI Crack Segmentation
Apr 15, 2026Crack segmentation on edge devices can support continuous infrastructure monitoring and maintenance and thereby help to preserve public safety. Furthermore, autonomous infrastructure monitoring by using Unmanned Aerial Vehicles (UAVs) can reduce inspection risks, as human operators no longer need to enter hazardous areas. Edge processing reduces the cost of inspection by eliminating the need for high resolution image storage for offline processing and mitigates the security risks and bandwidth requirements of streaming to cloud servers. Edge inference is difficult due to the limited memory and computational capabilities of edge devices, which can affect both accuracy and latency. Furthermore, battery-powered devices are subject to strict power and energy constraints. Together, these limitations impose restrictions on the model size and computational complexity that can be deployed close to the sensor. In recent years, Transformers have achieved state-of-the-art accuracy in a variety of applications, including semantic segmentation. However, Transformer-based models are typically large and computationally intensive, making efficient edge deployment difficult. To address this, we first apply knowledge distillation to enhance the performance of the base models. We then use PTQ to compress the models further. Additionally, we consider the deployment of these models across multiple edge platforms. To maximize energy efficiency, we design and implement a custom hardware architecture for the models on an FPGA. Our results show that Knowledge Distillation (KD) improves all tested U-Net variants. Among the evaluated platforms, the selected FPGA implementation achieves 398 FPS at 204.99 Frames/J while maintaining a mean IoU of 69.42%. In addition, our best model reaches 71.92% mean IoU, which is 8.82 percentage points (pps) higher than the previously reported result on the CrackVision12K dataset.
HALF: Holistic Auto Machine Learning for FPGAs
Jun 28, 2021
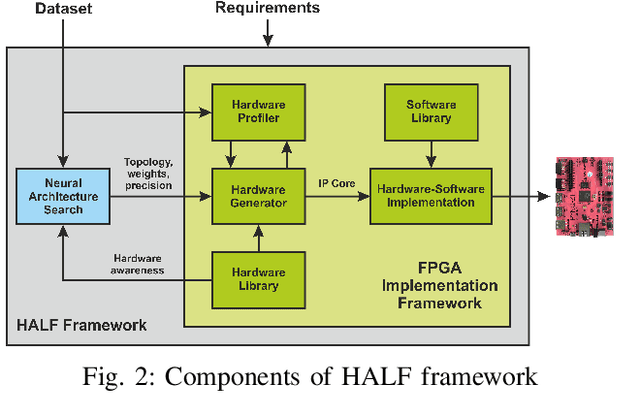

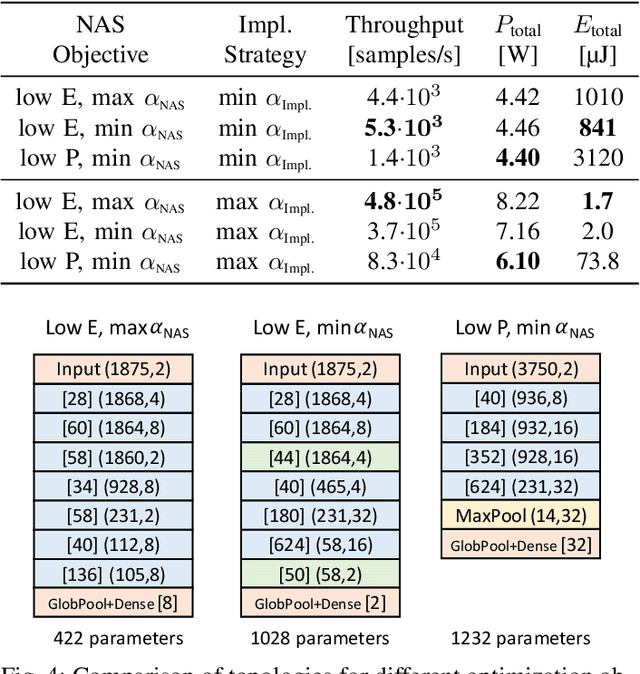
Deep Neural Networks (DNNs) are capable of solving complex problems in domains related to embedded systems, such as image and natural language processing. To efficiently implement DNNs on a specific FPGA platform for a given cost criterion, e.g. energy efficiency, an enormous amount of design parameters has to be considered from the topology down to the final hardware implementation. Interdependencies between the different design layers have to be taken into account and explored efficiently, making it hardly possible to find optimized solutions manually. An automatic, holistic design approach can improve the quality of DNN implementations on FPGA significantly. To this end, we present a cross-layer design space exploration methodology. It comprises optimizations starting from a hardware-aware topology search for DNNs down to the final optimized implementation for a given FPGA platform. The methodology is implemented in our Holistic Auto machine Learning for FPGAs (HALF) framework, which combines an evolutionary search algorithm, various optimization steps and a library of parametrizable hardware DNN modules. HALF automates both the exploration process and the implementation of optimized solutions on a target FPGA platform for various applications. We demonstrate the performance of HALF on a medical use case for arrhythmia detection for three different design goals, i.e. low-energy, low-power and high-throughput respectively. Our FPGA implementation outperforms a TensorRT optimized model on an Nvidia Jetson platform in both throughput and energy consumption.
FINN-L: Library Extensions and Design Trade-off Analysis for Variable Precision LSTM Networks on FPGAs
Jul 11, 2018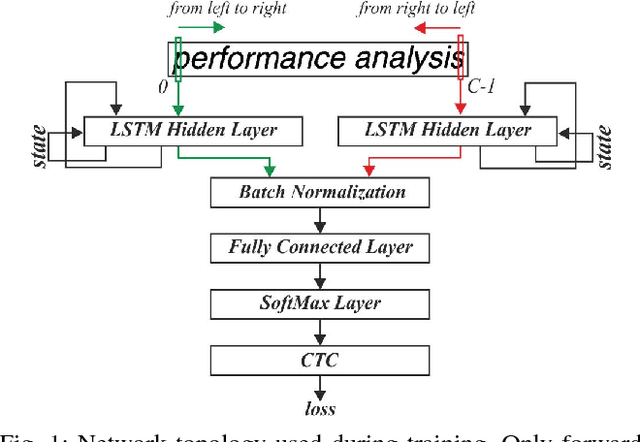
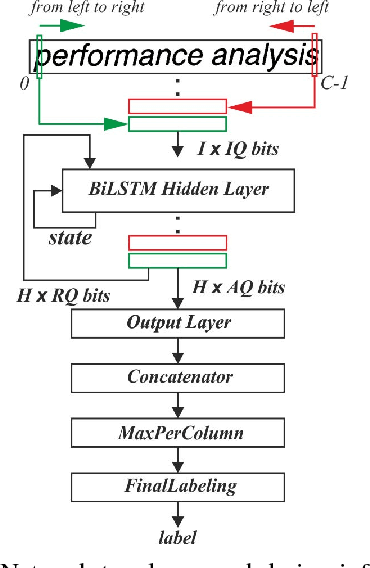
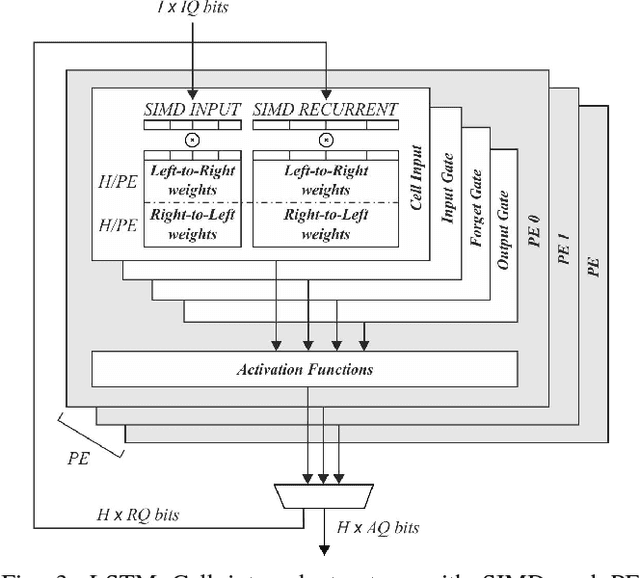
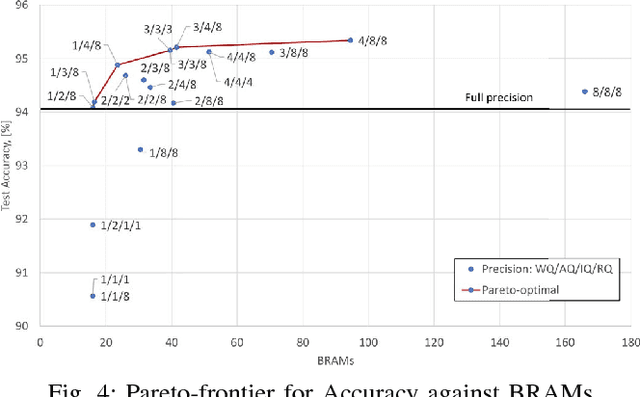
It is well known that many types of artificial neural networks, including recurrent networks, can achieve a high classification accuracy even with low-precision weights and activations. The reduction in precision generally yields much more efficient hardware implementations in regards to hardware cost, memory requirements, energy, and achievable throughput. In this paper, we present the first systematic exploration of this design space as a function of precision for Bidirectional Long Short-Term Memory (BiLSTM) neural network. Specifically, we include an in-depth investigation of precision vs. accuracy using a fully hardware-aware training flow, where during training quantization of all aspects of the network including weights, input, output and in-memory cell activations are taken into consideration. In addition, hardware resource cost, power consumption and throughput scalability are explored as a function of precision for FPGA-based implementations of BiLSTM, and multiple approaches of parallelizing the hardware. We provide the first open source HLS library extension of FINN for parameterizable hardware architectures of LSTM layers on FPGAs which offers full precision flexibility and allows for parameterizable performance scaling offering different levels of parallelism within the architecture. Based on this library, we present an FPGA-based accelerator for BiLSTM neural network designed for optical character recognition, along with numerous other experimental proof points for a Zynq UltraScale+ XCZU7EV MPSoC within the given design space.