 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment of Language Agents
Mar 26, 2021For artificial intelligence to be beneficial to humans the behaviour of AI agents needs to be aligned with what humans want. In this paper we discuss some behavioural issues for language agents, arising from accidental misspecification by the system designer. We highlight some ways that misspecification can occur and discuss some behavioural issues that could arise from misspecification, including deceptive or manipulative language, and review some approaches for avoiding these issues.
Causal Analysis of Agent Behavior for AI Safety
Mar 05, 2021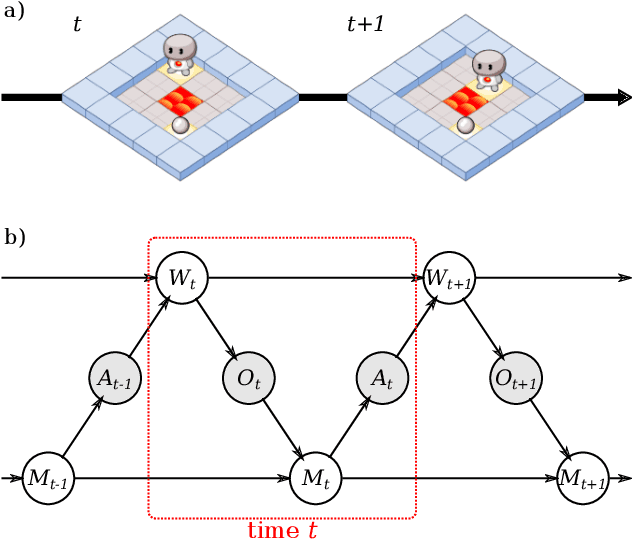
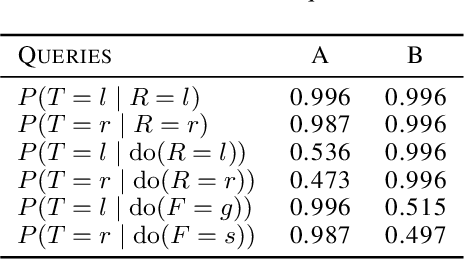
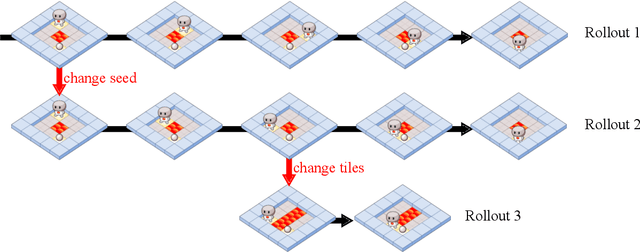
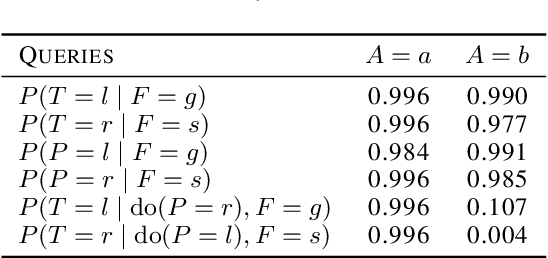
As machine learning systems become more powerful they also become increasingly unpredictable and opaque. Yet, finding human-understandable explanations of how they work is essential for their safe deployment. This technical report illustrates a methodology for investigating the causal mechanisms that drive the behaviour of artificial agents. Six use cases are covered, each addressing a typical question an analyst might ask about an agent. In particular, we show that each question cannot be addressed by pure observation alone, but instead requires conducting experiments with systematically chosen manipulations so as to generate the correct causal evidence.
Algorithms for Causal Reasoning in Probability Trees
Nov 12, 2020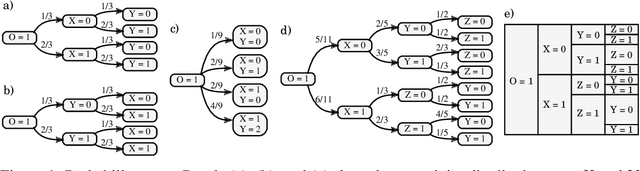
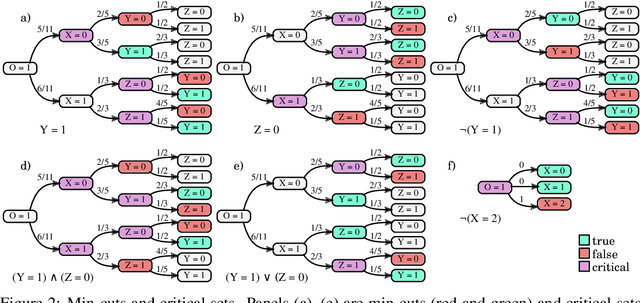


Probability trees are one of the simplest models of causal generative processes. They possess clean semantics and -- unlike causal Bayesian networks -- they can represent context-specific causal dependencies, which are necessary for e.g. causal induction. Yet, they have received little attention from the AI and ML community. Here we present concrete algorithms for causal reasoning in discrete probability trees that cover the entire causal hierarchy (association, intervention, and counterfactuals), and operate on arbitrary propositional and causal events. Our work expands the domain of causal reasoning to a very general class of discrete stochastic processes.
Meta-trained agents implement Bayes-optimal agents
Oct 21, 2020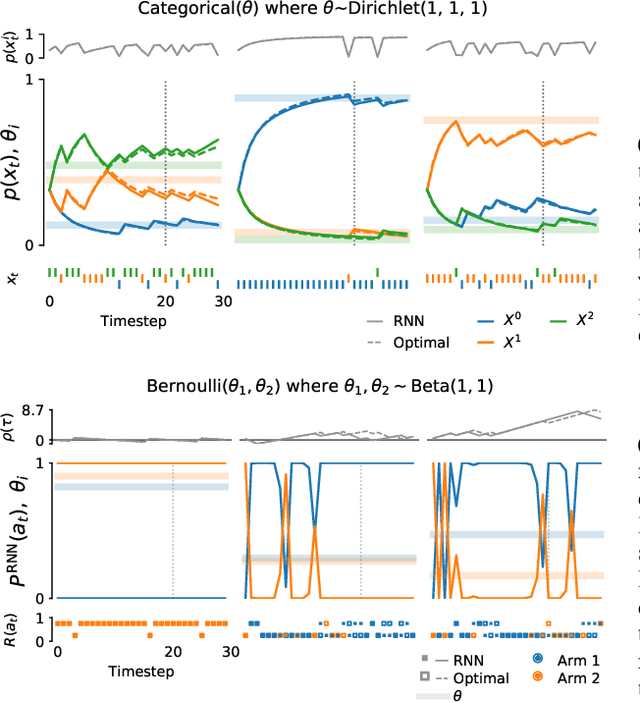

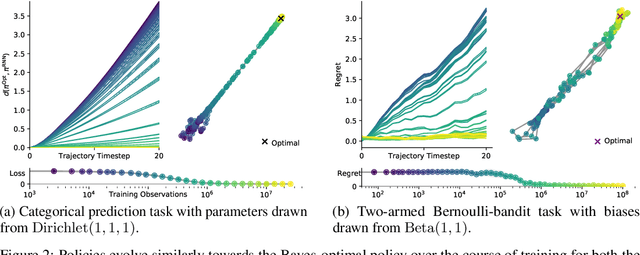
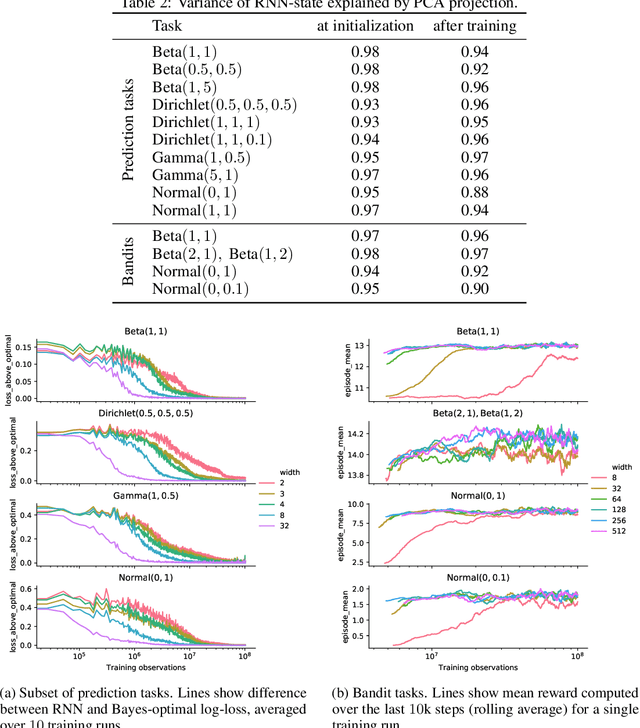
Memory-based meta-learning is a powerful technique to build agents that adapt fast to any task within a target distribution. A previous theoretical study has argued that this remarkable performance is because the meta-training protocol incentivises agents to behave Bayes-optimally. We empirically investigate this claim on a number of prediction and bandit tasks. Inspired by ideas from theoretical computer science, we show that meta-learned and Bayes-optimal agents not only behave alike, but they even share a similar computational structure, in the sense that one agent system can approximately simulate the other. Furthermore, we show that Bayes-optimal agents are fixed points of the meta-learning dynamics. Our results suggest that memory-based meta-learning might serve as a general technique for numerically approximating Bayes-optimal agents - that is, even for task distributions for which we currently don't possess tractable models.
Neural networks are a priori biased towards Boolean functions with low entropy
Sep 29, 2019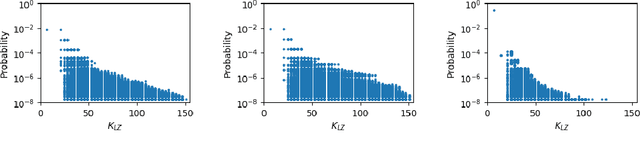
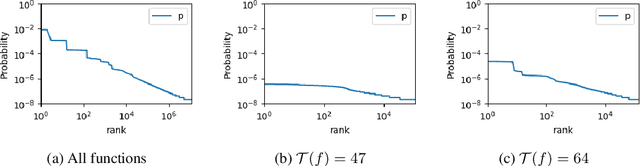
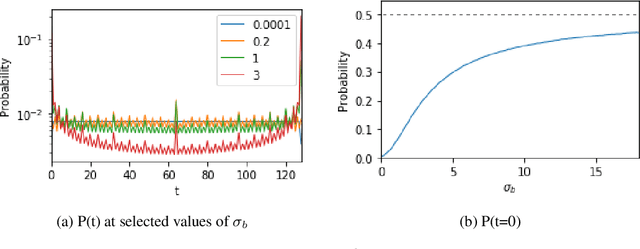
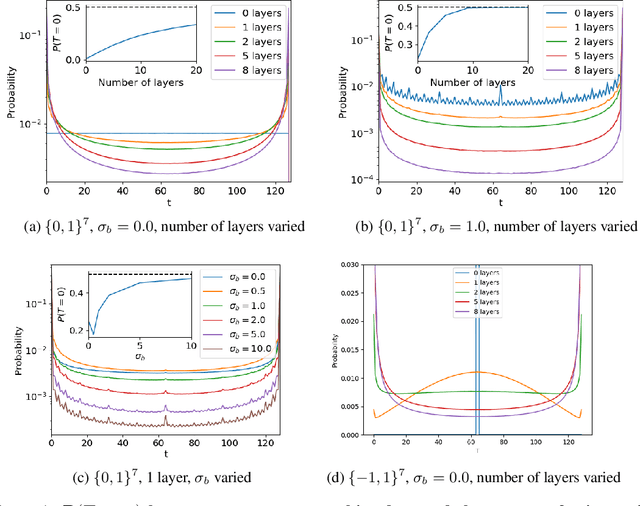
Understanding the inductive bias of neural networks is critical to explaining their ability to generalise. Here, for one of the simplest neural networks -- a single-layer perceptron with $n$ input neurons, one output neuron, and no threshold bias term -- we prove that upon random initialisation of weights, the a priori probability $P(t)$ that it represents a Boolean function that classifies $t$ points in $\{0,1\}^n$ as $1$ has a remarkably simple form: $ P(t) = 2^{-n} \,\, {\rm for} \,\, 0\leq t < 2^n$. Since a perceptron can express far fewer Boolean functions with small or large values of $t$ (low "entropy") than with intermediate values of $t$ (high "entropy") there is, on average, a strong intrinsic a-priori bias towards individual functions with low entropy. Furthermore, within a class of functions with fixed $t$, we often observe a further intrinsic bias towards functions of lower complexity. Finally, we prove that, regardless of the distribution of inputs, the bias towards low entropy becomes monotonically stronger upon adding ReLU layers, and empirically show that increasing the variance of the bias term has a similar effect.
Risks from Learned Optimization in Advanced Machine Learning Systems
Jun 11, 2019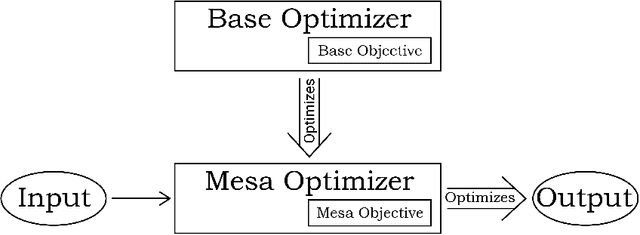
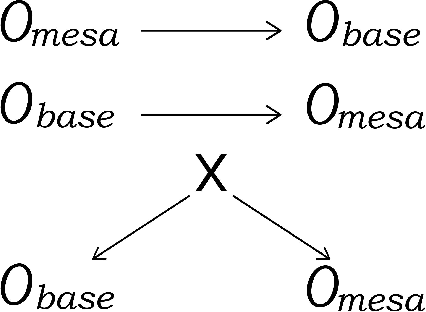
We analyze the type of learned optimization that occurs when a learned model (such as a neural network) is itself an optimizer - a situation we refer to as mesa-optimization, a neologism we introduce in this paper. We believe that the possibility of mesa-optimization raises two important questions for the safety and transparency of advanced machine learning systems. First, under what circumstances will learned models be optimizers, including when they should not be? Second, when a learned model is an optimizer, what will its objective be - how will it differ from the loss function it was trained under - and how can it be aligned? In this paper, we provide an in-depth analysis of these two primary questions and provide an overview of topics for future research.