 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterising the Inductive Biases of Neural Networks on Boolean Data
May 29, 2025



Deep neural networks are renowned for their ability to generalise well across diverse tasks, even when heavily overparameterized. Existing works offer only partial explanations (for example, the NTK-based task-model alignment explanation neglects feature learning). Here, we provide an end-to-end, analytically tractable case study that links a network's inductive prior, its training dynamics including feature learning, and its eventual generalisation. Specifically, we exploit the one-to-one correspondence between depth-2 discrete fully connected networks and disjunctive normal form (DNF) formulas by training on Boolean functions. Under a Monte Carlo learning algorithm, our model exhibits predictable training dynamics and the emergence of interpretable features. This framework allows us to trace, in detail, how inductive bias and feature formation drive generalisation.
Visualising Feature Learning in Deep Neural Networks by Diagonalizing the Forward Feature Map
Oct 05, 2024



Deep neural networks (DNNs) exhibit a remarkable ability to automatically learn data representations, finding appropriate features without human input. Here we present a method for analysing feature learning by decomposing DNNs into 1) a forward feature-map $\Phi$ that maps the input dataspace to the post-activations of the penultimate layer, and 2) a final linear layer that classifies the data. We diagonalize $\Phi$ with respect to the gradient descent operator and track feature learning by measuring how the eigenfunctions and eigenvalues of $\Phi$ change during training. Across many popular architectures and classification datasets, we find that DNNs converge, after just a few epochs, to a minimal feature (MF) regime dominated by a number of eigenfunctions equal to the number of classes. This behaviour resembles the neural collapse phenomenon studied at longer training times. For other DNN-data combinations, such as a fully connected network on CIFAR10, we find an extended feature (EF) regime where significantly more features are used. Optimal generalisation performance upon hyperparameter tuning typically coincides with the MF regime, but we also find examples of poor performance within the MF regime. Finally, we recast the phenomenon of neural collapse into a kernel picture which can be extended to broader tasks such as regression.
Exploiting the equivalence between quantum neural networks and perceptrons
Jul 05, 2024



Quantum machine learning models based on parametrized quantum circuits, also called quantum neural networks (QNNs), are considered to be among the most promising candidates for applications on near-term quantum devices. Here we explore the expressivity and inductive bias of QNNs by exploiting an exact mapping from QNNs with inputs $x$ to classical perceptrons acting on $x \otimes x$ (generalised to complex inputs). The simplicity of the perceptron architecture allows us to provide clear examples of the shortcomings of current QNN models, and the many barriers they face to becoming useful general-purpose learning algorithms. For example, a QNN with amplitude encoding cannot express the Boolean parity function for $n\geq 3$, which is but one of an exponential number of data structures that such a QNN is unable to express. Mapping a QNN to a classical perceptron simplifies training, allowing us to systematically study the inductive biases of other, more expressive embeddings on Boolean data. Several popular embeddings primarily produce an inductive bias towards functions with low class balance, reducing their generalisation performance compared to deep neural network architectures which exhibit much richer inductive biases. We explore two alternate strategies that move beyond standard QNNs. In the first, we use a QNN to help generate a classical DNN-inspired kernel. In the second we draw an analogy to the hierarchical structure of deep neural networks and construct a layered non-linear QNN that is provably fully expressive on Boolean data, while also exhibiting a richer inductive bias than simple QNNs. Finally, we discuss characteristics of the QNN literature that may obscure how hard it is to achieve quantum advantage over deep learning algorithms on classical data.
Do deep neural networks have an inbuilt Occam's razor?
Apr 13, 2023The remarkable performance of overparameterized deep neural networks (DNNs) must arise from an interplay between network architecture, training algorithms, and structure in the data. To disentangle these three components, we apply a Bayesian picture, based on the functions expressed by a DNN, to supervised learning. The prior over functions is determined by the network, and is varied by exploiting a transition between ordered and chaotic regimes. For Boolean function classification, we approximate the likelihood using the error spectrum of functions on data. When combined with the prior, this accurately predicts the posterior, measured for DNNs trained with stochastic gradient descent. This analysis reveals that structured data, combined with an intrinsic Occam's razor-like inductive bias towards (Kolmogorov) simple functions that is strong enough to counteract the exponential growth of the number of functions with complexity, is a key to the success of DNNs.
Automatic Gradient Descent: Deep Learning without Hyperparameters
Apr 11, 2023The architecture of a deep neural network is defined explicitly in terms of the number of layers, the width of each layer and the general network topology. Existing optimisation frameworks neglect this information in favour of implicit architectural information (e.g. second-order methods) or architecture-agnostic distance functions (e.g. mirror descent). Meanwhile, the most popular optimiser in practice, Adam, is based on heuristics. This paper builds a new framework for deriving optimisation algorithms that explicitly leverage neural architecture. The theory extends mirror descent to non-convex composite objective functions: the idea is to transform a Bregman divergence to account for the non-linear structure of neural architecture. Working through the details for deep fully-connected networks yields automatic gradient descent: a first-order optimiser without any hyperparameters. Automatic gradient descent trains both fully-connected and convolutional networks out-of-the-box and at ImageNet scale. A PyTorch implementation is available at https://github.com/jxbz/agd and also in Appendix B. Overall, the paper supplies a rigorous theoretical foundation for a next-generation of architecture-dependent optimisers that work automatically and without hyperparameters.
The Equilibrium Hypothesis: Rethinking implicit regularization in Deep Neural Networks
Oct 22, 2021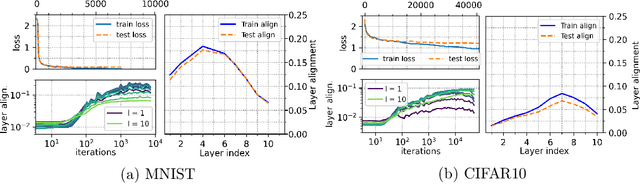
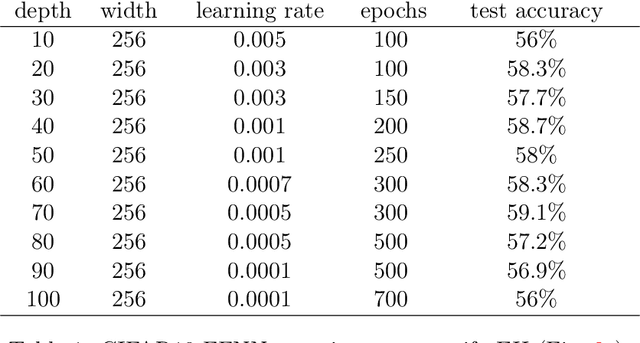
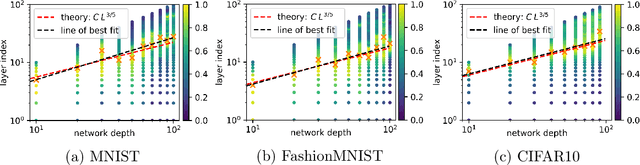
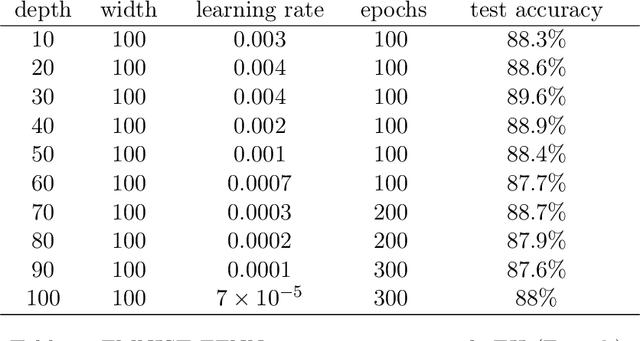
Modern Deep Neural Networks (DNNs) exhibit impressive generalization properties on a variety of tasks without explicit regularization, suggesting the existence of hidden regularization effects. Recent work by Baratin et al. (2021) sheds light on an intriguing implicit regularization effect, showing that some layers are much more aligned with data labels than other layers. This suggests that as the network grows in depth and width, an implicit layer selection phenomenon occurs during training. In this work, we provide the first explanation for this alignment hierarchy. We introduce and empirically validate the Equilibrium Hypothesis which states that the layers that achieve some balance between forward and backward information loss are the ones with the highest alignment to data labels. Our experiments demonstrate an excellent match with the theoretical predictions.
Is SGD a Bayesian sampler? Well, almost
Jun 26, 2020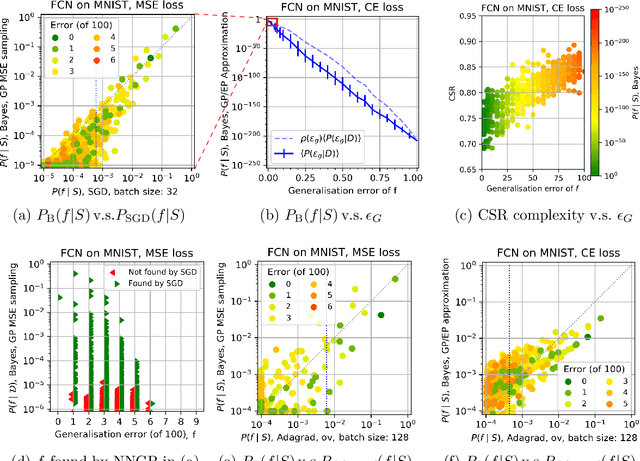
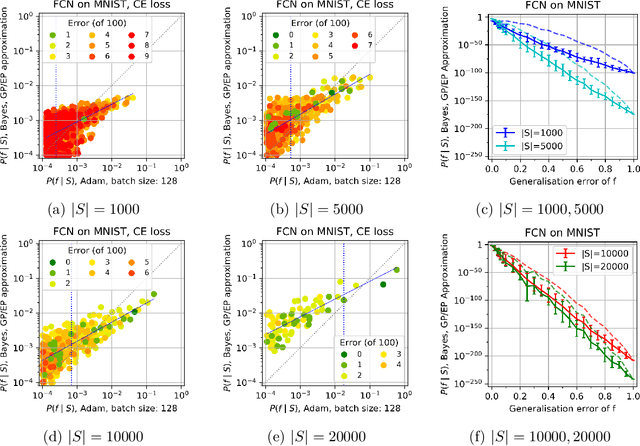
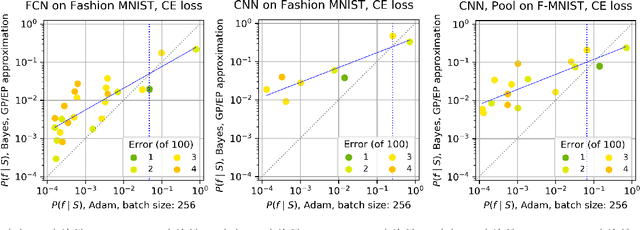
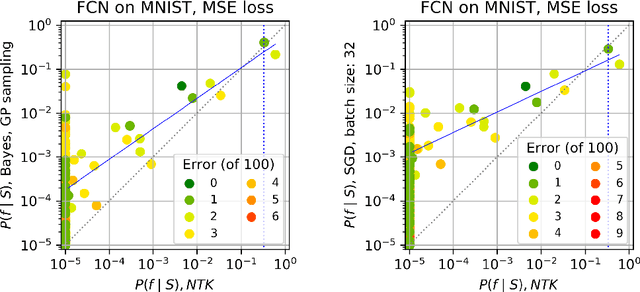
Overparameterised deep neural networks (DNNs) are highly expressive and so can, in principle, generate almost any function that fits a training dataset with zero error. The vast majority of these functions will perform poorly on unseen data, and yet in practice DNNs often generalise remarkably well. This success suggests that a trained DNN must have a strong inductive bias towards functions with low generalisation error. Here we empirically investigate this inductive bias by calculating, for a range of architectures and datasets, the probability $P_{SGD}(f\mid S)$ that an overparameterised DNN, trained with stochastic gradient descent (SGD) or one of its variants, converges on a function $f$ consistent with a training set $S$. We also use Gaussian processes to estimate the Bayesian posterior probability $P_B(f\mid S)$ that the DNN expresses $f$ upon random sampling of its parameters, conditioned on $S$. Our main findings are that $P_{SGD}(f\mid S)$ correlates remarkably well with $P_B(f\mid S)$ and that $P_B(f\mid S)$ is strongly biased towards low-error and low complexity functions. These results imply that strong inductive bias in the parameter-function map (which determines $P_B(f\mid S)$), rather than a special property of SGD, is the primary explanation for why DNNs generalise so well in the overparameterised regime. While our results suggest that the Bayesian posterior $P_B(f\mid S)$ is the first order determinant of $P_{SGD}(f\mid S)$, there remain second order differences that are sensitive to hyperparameter tuning. A function probability picture, based on $P_{SGD}(f\mid S)$ and/or $P_B(f\mid S)$, can shed new light on the way that variations in architecture or hyperparameter settings such as batch size, learning rate, and optimiser choice, affect DNN performance.
Neural networks are a priori biased towards Boolean functions with low entropy
Sep 29, 2019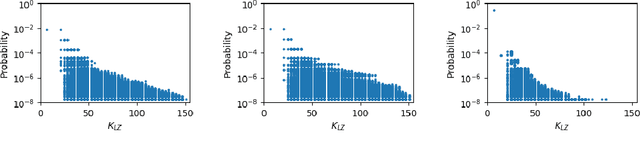
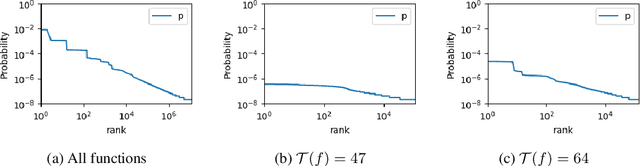
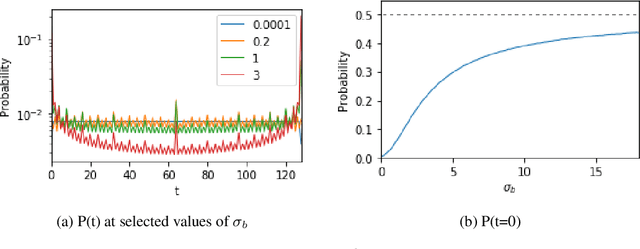
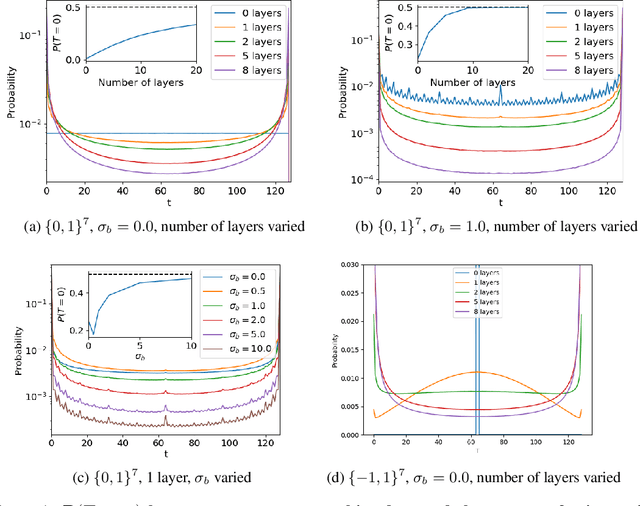
Understanding the inductive bias of neural networks is critical to explaining their ability to generalise. Here, for one of the simplest neural networks -- a single-layer perceptron with $n$ input neurons, one output neuron, and no threshold bias term -- we prove that upon random initialisation of weights, the a priori probability $P(t)$ that it represents a Boolean function that classifies $t$ points in $\{0,1\}^n$ as $1$ has a remarkably simple form: $ P(t) = 2^{-n} \,\, {\rm for} \,\, 0\leq t < 2^n$. Since a perceptron can express far fewer Boolean functions with small or large values of $t$ (low "entropy") than with intermediate values of $t$ (high "entropy") there is, on average, a strong intrinsic a-priori bias towards individual functions with low entropy. Furthermore, within a class of functions with fixed $t$, we often observe a further intrinsic bias towards functions of lower complexity. Finally, we prove that, regardless of the distribution of inputs, the bias towards low entropy becomes monotonically stronger upon adding ReLU layers, and empirically show that increasing the variance of the bias term has a similar effect.