 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Extending Puzzle for Mixture-of-Experts Reasoning Models with Application to GPT-OSS Acceleration
Feb 12, 2026Reasoning-focused LLMs improve answer quality by generating longer reasoning traces, but the additional tokens dramatically increase serving cost, motivating inference optimization. We extend and apply Puzzle, a post-training neural architecture search (NAS) framework, to gpt-oss-120B to produce gpt-oss-puzzle-88B, a deployment-optimized derivative. Our approach combines heterogeneous MoE expert pruning, selective replacement of full-context attention with window attention, FP8 KV-cache quantization with calibrated scales, and post-training reinforcement learning to recover accuracy, while maintaining low generation length. In terms of per-token speeds, on an 8XH100 node we achieve 1.63X and 1.22X throughput speedups in long-context and short-context settings, respectively. gpt-oss-puzzle-88B also delivers throughput speedups of 2.82X on a single NVIDIA H100 GPU. However, because token counts can change with reasoning effort and model variants, per-token throughput (tok/s) and latency (ms/token) do not necessarily lead to end-to-end speedups: a 2X throughput gain is erased if traces grow 2X. Conversely, throughput gains can be spent on more reasoning tokens to improve accuracy; we therefore advocate request-level efficiency metrics that normalize throughput by tokens generated and trace an accuracy--speed frontier across reasoning efforts. We show that gpt-oss-puzzle-88B improves over gpt-oss-120B along the entire frontier, delivering up to 1.29X higher request-level efficiency. Across various benchmarks, gpt-oss-puzzle-88B matches or slightly exceeds the parent on suite-average accuracy across reasoning efforts, with retention ranging from 100.8% (high) to 108.2% (low), showing that post-training architecture search can substantially reduce inference costs without sacrificing quality.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021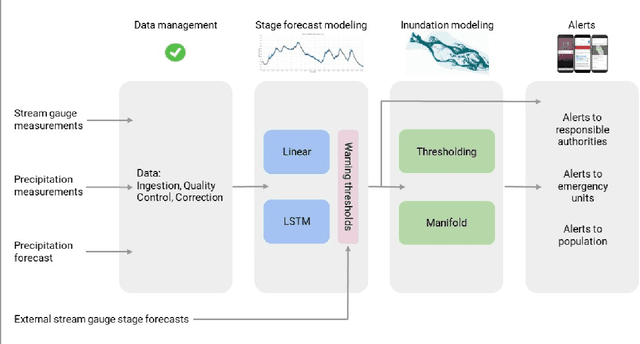
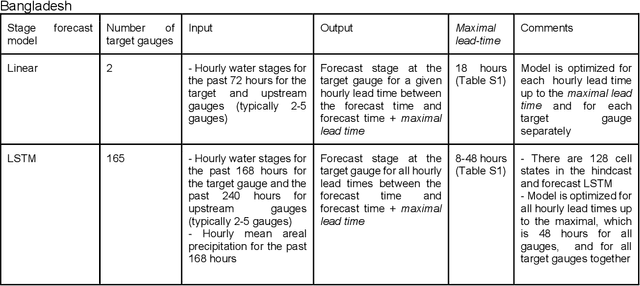
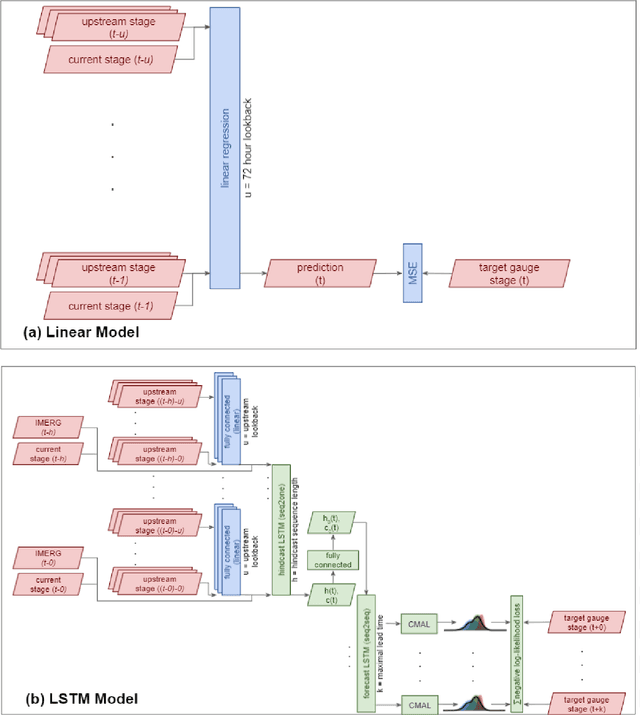
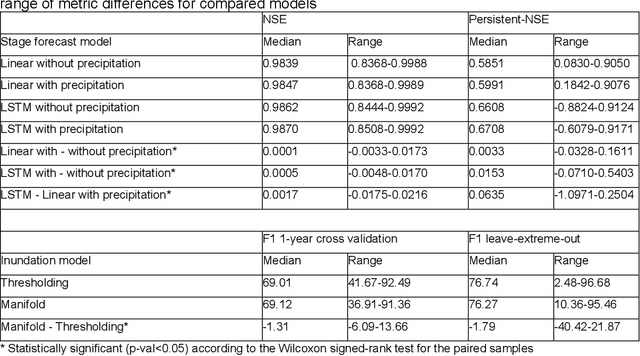
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
Inundation Modeling in Data Scarce Regions
Oct 30, 2019
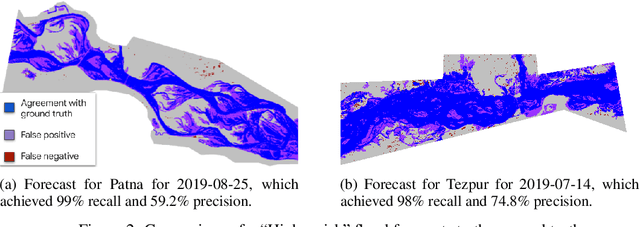
Flood forecasts are crucial for effective individual and governmental protective action. The vast majority of flood-related casualties occur in developing countries, where providing spatially accurate forecasts is a challenge due to scarcity of data and lack of funding. This paper describes an operational system providing flood extent forecast maps covering several flood-prone regions in India, with the goal of being sufficiently scalable and cost-efficient to facilitate the establishment of effective flood forecasting systems globally.