 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
Apr 02, 2021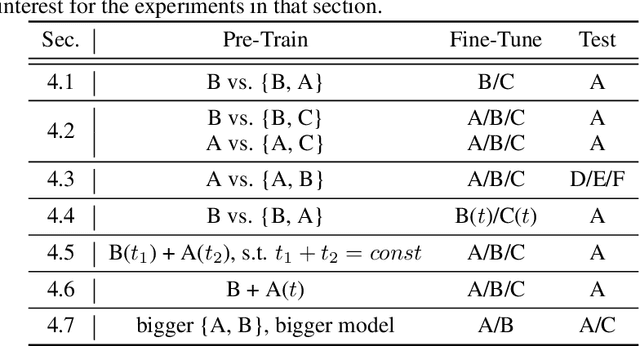
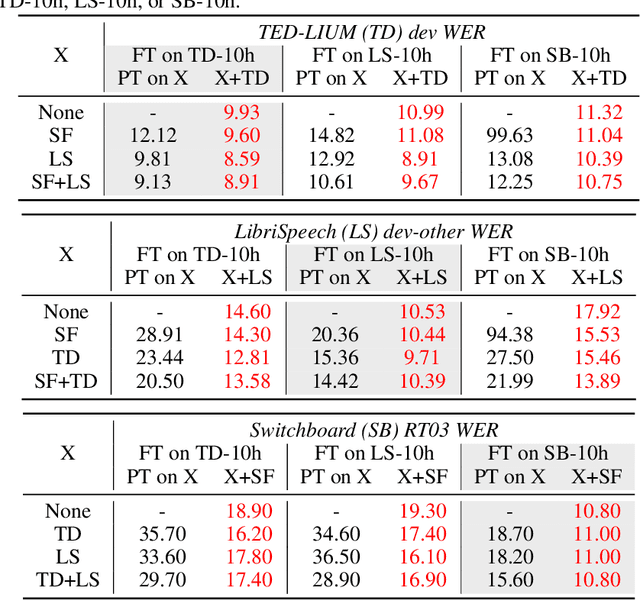
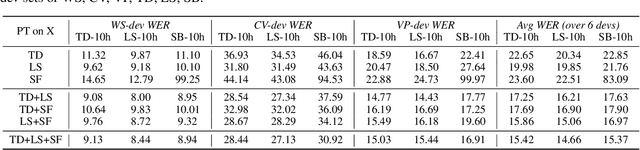
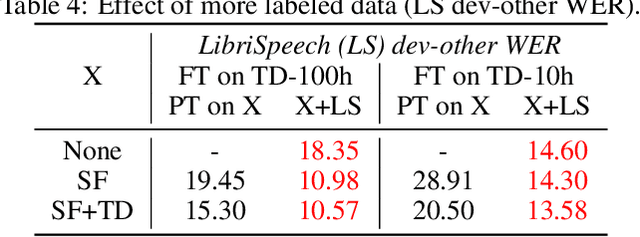
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at https://github.com/pytorch/fairseq.
MLS: A Large-Scale Multilingual Dataset for Speech Research
Dec 19, 2020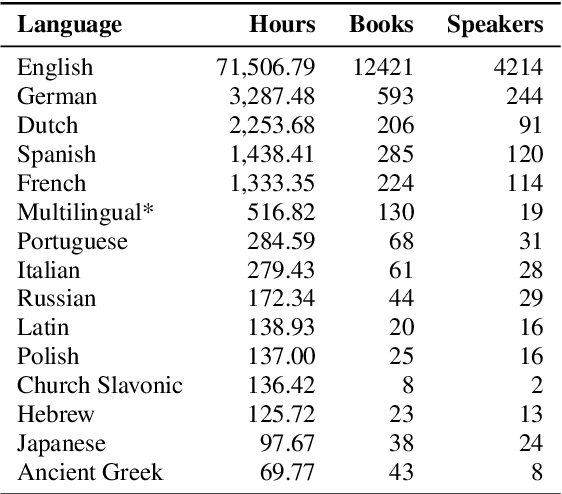
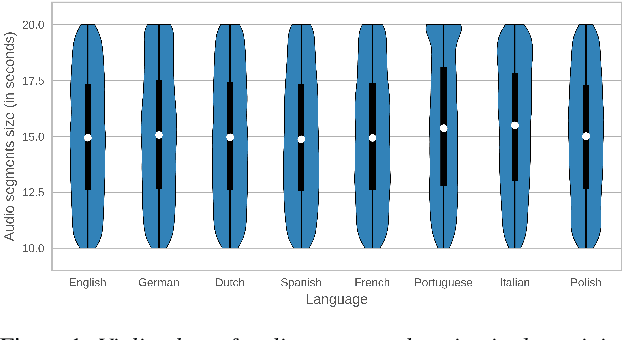
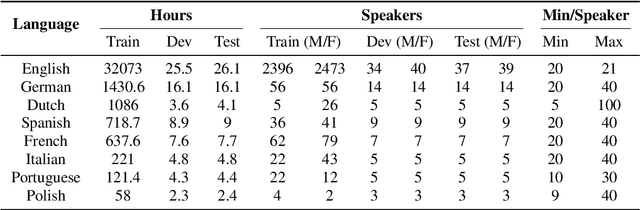
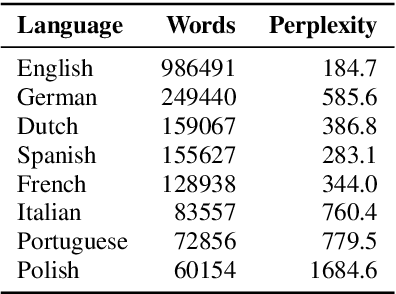
This paper introduces Multilingual LibriSpeech (MLS) dataset, a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a total of about 6K hours for other languages. Additionally, we provide Language Models (LM) and baseline Automatic Speech Recognition (ASR) models and for all the languages in our dataset. We believe such a large transcribed dataset will open new avenues in ASR and Text-To-Speech (TTS) research. The dataset will be made freely available for anyone at http://www.openslr.org.
Rethinking Evaluation in ASR: Are Our Models Robust Enough?
Oct 22, 2020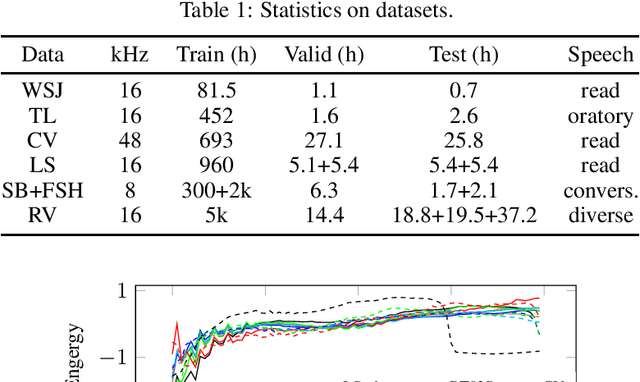
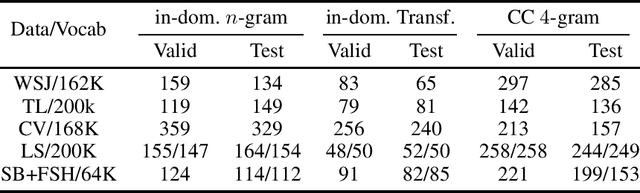
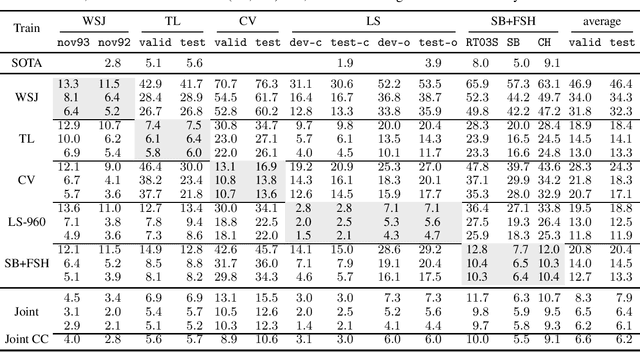
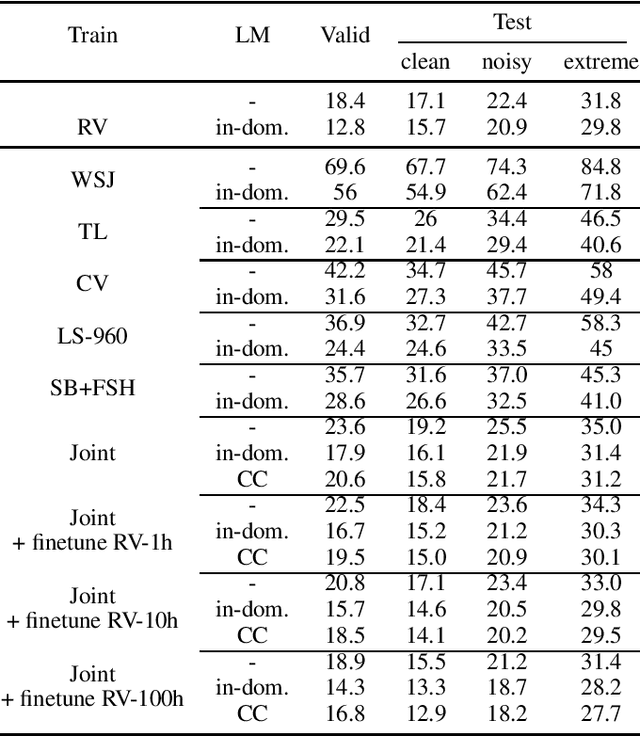
Is pushing numbers on a single benchmark valuable in automatic speech recognition? Research results in acoustic modeling are typically evaluated based on performance on a single dataset. While the research community has coalesced around various benchmarks, we set out to understand generalization performance in acoustic modeling across datasets -- in particular, if models trained on a single dataset transfer to other (possibly out-of-domain) datasets. Further, we demonstrate that when a large enough set of benchmarks is used, average word error rate (WER) performance over them provides a good proxy for performance on real-world data. Finally, we show that training a single acoustic model on the most widely-used datasets -- combined -- reaches competitive performance on both research and real-world benchmarks.
Differentiable Weighted Finite-State Transducers
Oct 02, 2020

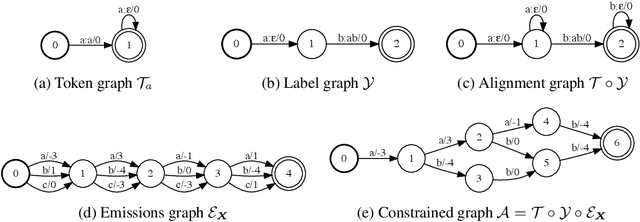
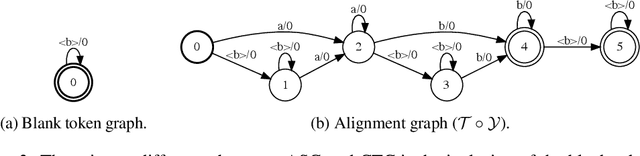
We introduce a framework for automatic differentiation with weighted finite-state transducers (WFSTs) allowing them to be used dynamically at training time. Through the separation of graphs from operations on graphs, this framework enables the exploration of new structured loss functions which in turn eases the encoding of prior knowledge into learning algorithms. We show how the framework can combine pruning and back-off in transition models with various sequence-level loss functions. We also show how to learn over the latent decomposition of phrases into word pieces. Finally, to demonstrate that WFSTs can be used in the interior of a deep neural network, we propose a convolutional WFST layer which maps lower-level representations to higher-level representations and can be used as a drop-in replacement for a traditional convolution. We validate these algorithms with experiments in handwriting recognition and speech recognition.
Massively Multilingual ASR: 50 Languages, 1 Model, 1 Billion Parameters
Jul 08, 2020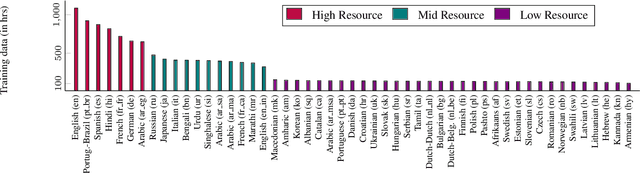
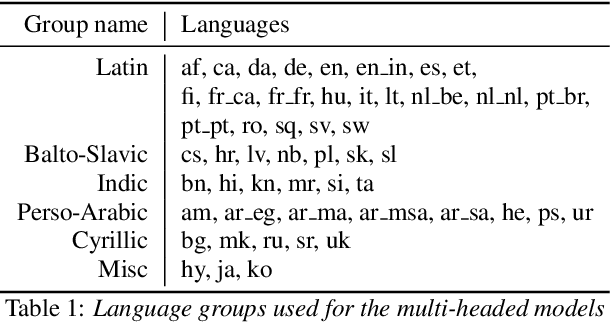
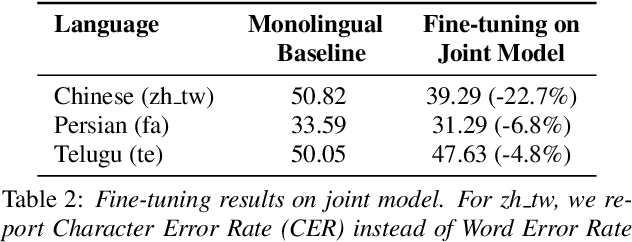
We study training a single acoustic model for multiple languages with the aim of improving automatic speech recognition (ASR) performance on low-resource languages, and over-all simplifying deployment of ASR systems that support diverse languages. We perform an extensive benchmark on 51 languages, with varying amount of training data by language(from 100 hours to 1100 hours). We compare three variants of multilingual training from a single joint model without knowing the input language, to using this information, to multiple heads (one per language cluster). We show that multilingual training of ASR models on several languages can improve recognition performance, in particular, on low resource languages. We see 20.9%, 23% and 28.8% average WER relative reduction compared to monolingual baselines on joint model, joint model with language input and multi head model respectively. To our knowledge, this is the first work studying multilingual ASR at massive scale, with more than 50 languages and more than 16,000 hours of audio across them.
Scaling Up Online Speech Recognition Using ConvNets
Jan 27, 2020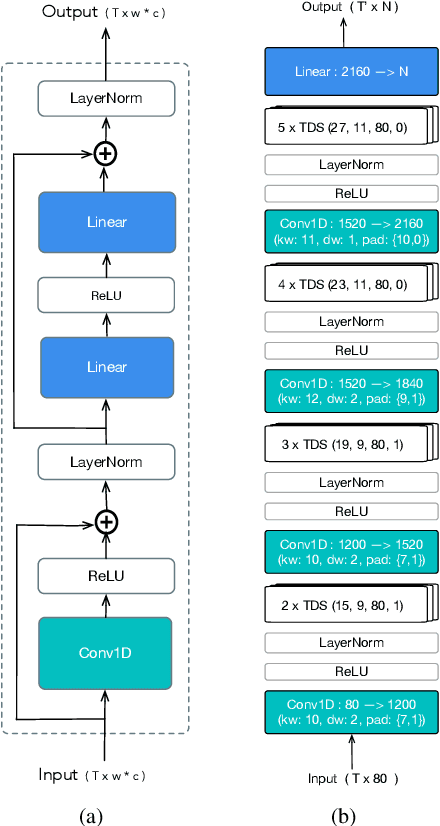
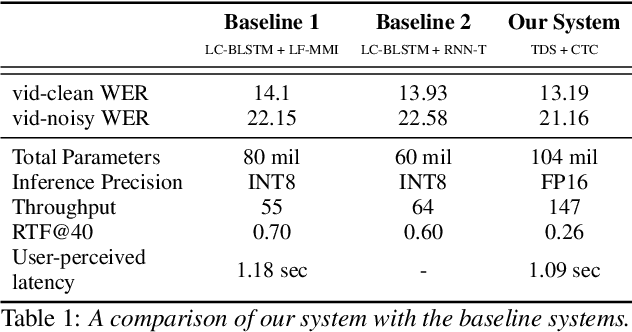

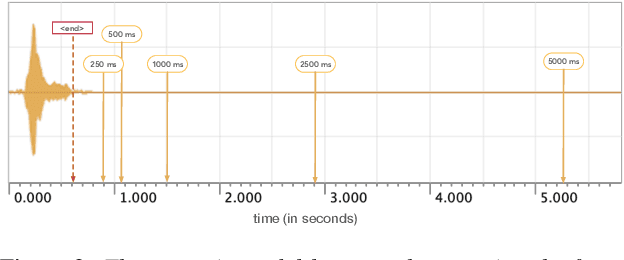
We design an online end-to-end speech recognition system based on Time-Depth Separable (TDS) convolutions and Connectionist Temporal Classification (CTC). We improve the core TDS architecture in order to limit the future context and hence reduce latency while maintaining accuracy. The system has almost three times the throughput of a well tuned hybrid ASR baseline while also having lower latency and a better word error rate. Also important to the efficiency of the recognizer is our highly optimized beam search decoder. To show the impact of our design choices, we analyze throughput, latency, accuracy, and discuss how these metrics can be tuned based on the user requirements.
End-to-end ASR: from Supervised to Semi-Supervised Learning with Modern Architectures
Nov 19, 2019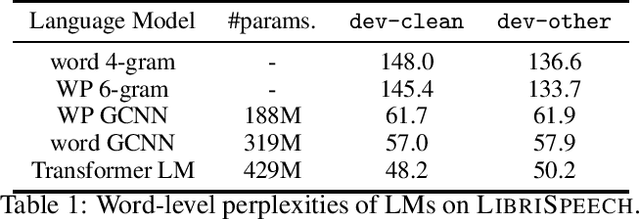
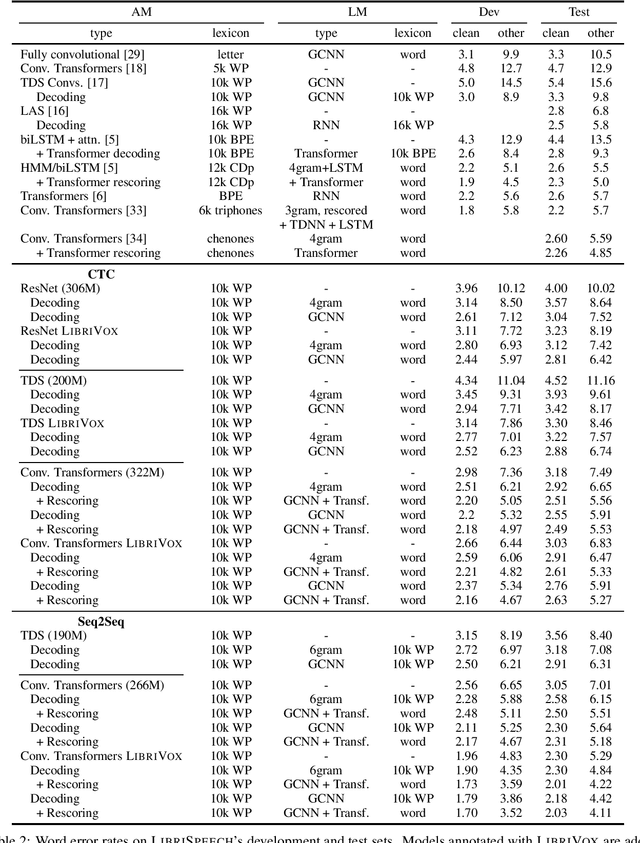
We study ResNet-, Time-Depth Separable ConvNets-, and Transformer-based acoustic models, trained with CTC or Seq2Seq criterions. We perform experiments on the LibriSpeech dataset, with and without LM decoding, optionally with beam rescoring. We reach 5.18% WER with external language models for decoding and rescoring. Additionally, we leverage the unlabeled data from LibriVox by doing semi-supervised training and show that it is possible to reach 5.29% WER on test-other without decoding, and 4.11% WER with decoding and rescoring, with only the standard 960 hours from LibriSpeech as labeled data.
wav2letter++: The Fastest Open-source Speech Recognition System
Dec 18, 2018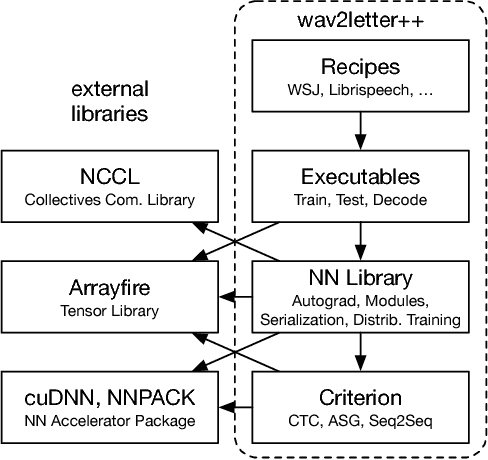
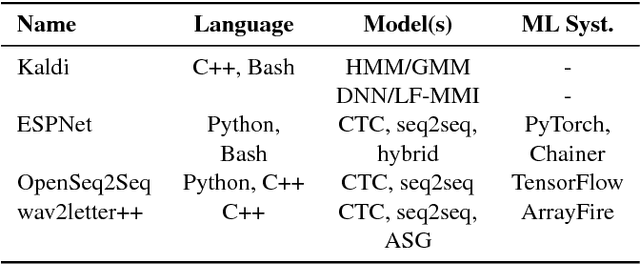

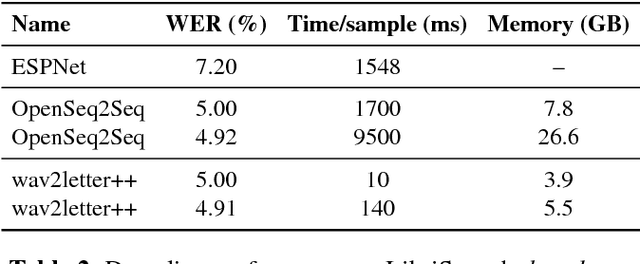
This paper introduces wav2letter++, the fastest open-source deep learning speech recognition framework. wav2letter++ is written entirely in C++, and uses the ArrayFire tensor library for maximum efficiency. Here we explain the architecture and design of the wav2letter++ system and compare it to other major open-source speech recognition systems. In some cases wav2letter++ is more than 2x faster than other optimized frameworks for training end-to-end neural networks for speech recognition. We also show that wav2letter++'s training times scale linearly to 64 GPUs, the highest we tested, for models with 100 million parameters. High-performance frameworks enable fast iteration, which is often a crucial factor in successful research and model tuning on new datasets and tasks.