 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simulation-Based Test of Identifiability for Bayesian Causal Inference
Feb 23, 2021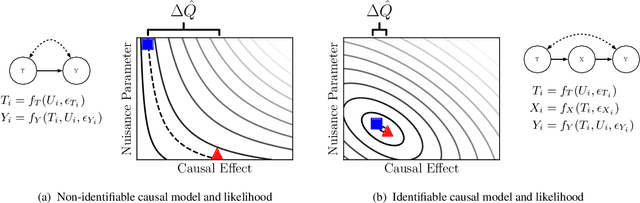

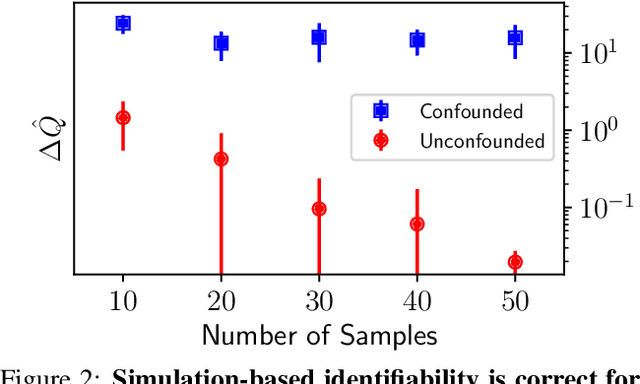
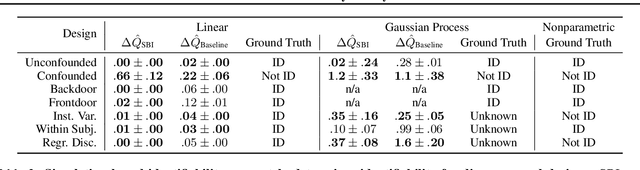
This paper introduces a procedure for testing the identifiability of Bayesian models for causal inference. Although the do-calculus is sound and complete given a causal graph, many practical assumptions cannot be expressed in terms of graph structure alone, such as the assumptions required by instrumental variable designs, regression discontinuity designs, and within-subjects designs. We present simulation-based identifiability (SBI), a fully automated identification test based on a particle optimization scheme with simulated observations. This approach expresses causal assumptions as priors over functions in a structural causal model, including flexible priors using Gaussian processes. We prove that SBI is asymptotically sound and complete, and produces practical finite-sample bounds. We also show empirically that SBI agrees with known results in graph-based identification as well as with widely-held intuitions for designs in which graph-based methods are inconclusive.
Causal Inference using Gaussian Processes with Structured Latent Confounders
Jul 14, 2020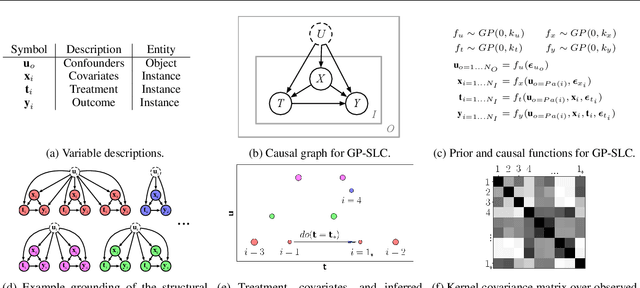
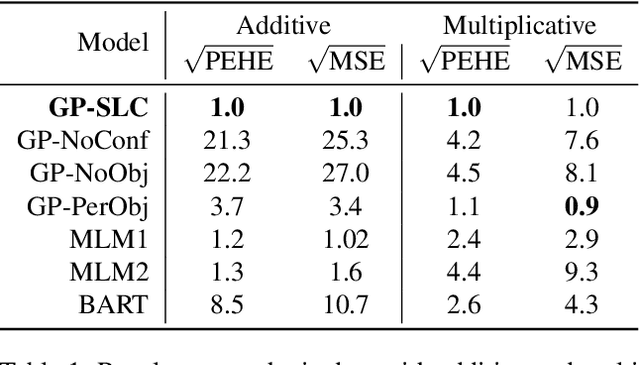
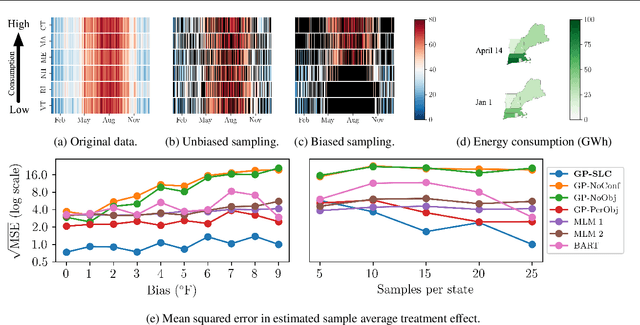
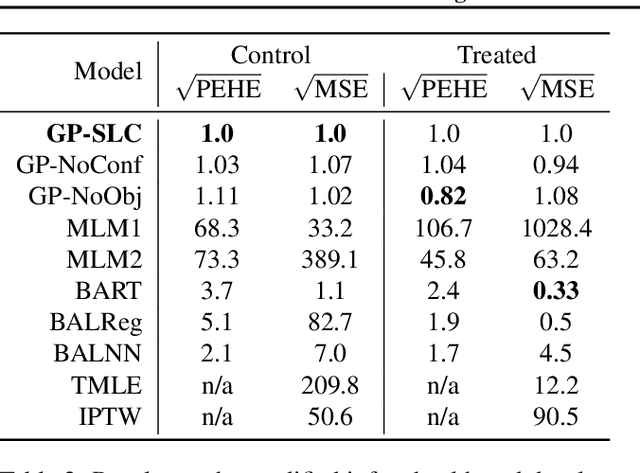
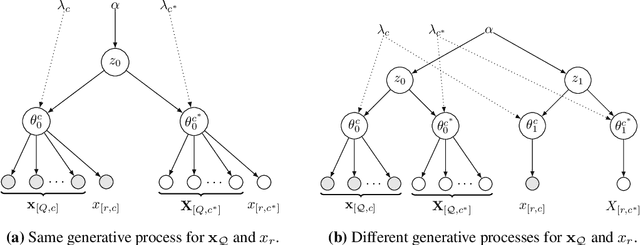
Latent confounders---unobserved variables that influence both treatment and outcome---can bias estimates of causal effects. In some cases, these confounders are shared across observations, e.g. all students taking a course are influenced by the course's difficulty in addition to any educational interventions they receive individually. This paper shows how to semiparametrically model latent confounders that have this structure and thereby improve estimates of causal effects. The key innovations are a hierarchical Bayesian model, Gaussian processes with structured latent confounders (GP-SLC), and a Monte Carlo inference algorithm for this model based on elliptical slice sampling. GP-SLC provides principled Bayesian uncertainty estimates of individual treatment effect with minimal assumptions about the functional forms relating confounders, covariates, treatment, and outcome. Finally, this paper shows GP-SLC is competitive with or more accurate than widely used causal inference techniques on three benchmark datasets, including the Infant Health and Development Program and a dataset showing the effect of changing temperatures on state-wide energy consumption across New England.
Deep Involutive Generative Models for Neural MCMC
Jul 02, 2020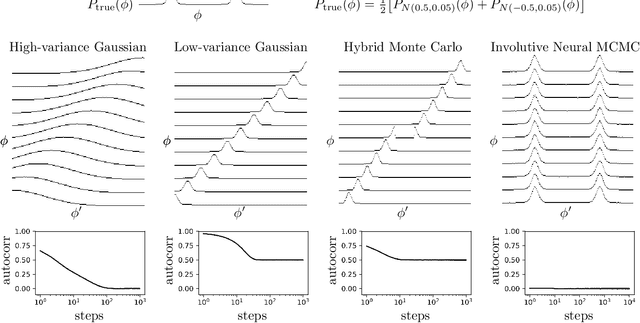
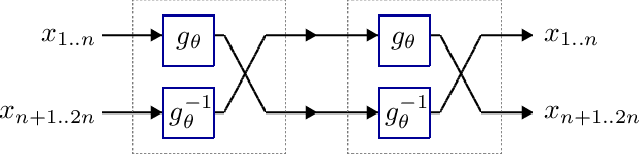
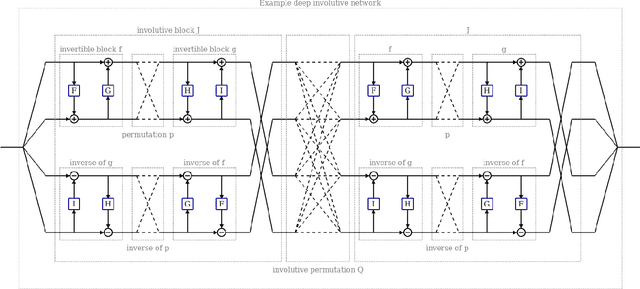

We introduce deep involutive generative models, a new architecture for deep generative modeling, and use them to define Involutive Neural MCMC, a new approach to fast neural MCMC. An involutive generative model represents a probability kernel $G(\phi \mapsto \phi')$ as an involutive (i.e., self-inverting) deterministic function $f(\phi, \pi)$ on an enlarged state space containing auxiliary variables $\pi$. We show how to make these models volume preserving, and how to use deep volume-preserving involutive generative models to make valid Metropolis-Hastings updates based on an auxiliary variable scheme with an easy-to-calculate acceptance ratio. We prove that deep involutive generative models and their volume-preserving special case are universal approximators for probability kernels. This result implies that with enough network capacity and training time, they can be used to learn arbitrarily complex MCMC updates. We define a loss function and optimization algorithm for training parameters given simulated data. We also provide initial experiments showing that Involutive Neural MCMC can efficiently explore multi-modal distributions that are intractable for Hybrid Monte Carlo, and can converge faster than A-NICE-MC, a recently introduced neural MCMC technique.
Bayesian causal inference via probabilistic program synthesis
Oct 30, 2019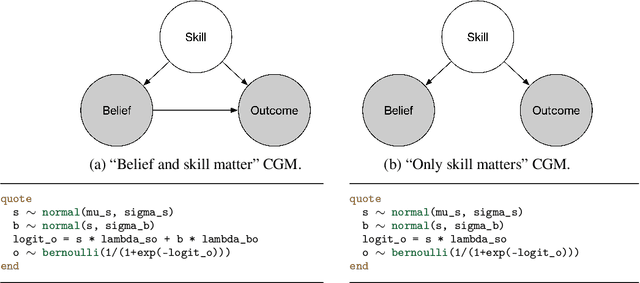

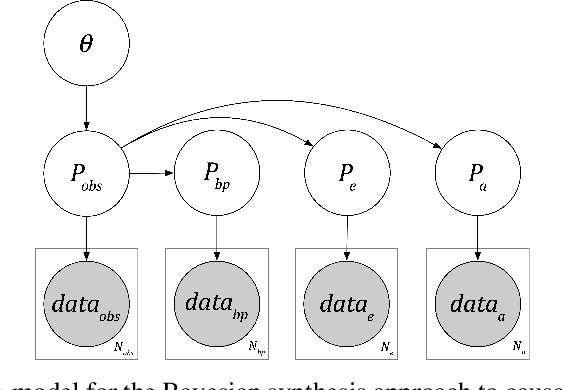

Causal inference can be formalized as Bayesian inference that combines a prior distribution over causal models and likelihoods that account for both observations and interventions. We show that it is possible to implement this approach using a sufficiently expressive probabilistic programming language. Priors are represented using probabilistic programs that generate source code in a domain specific language. Interventions are represented using probabilistic programs that edit this source code to modify the original generative process. This approach makes it straightforward to incorporate data from atomic interventions, as well as shift interventions, variance-scaling interventions, and other interventions that modify causal structure. This approach also enables the use of general-purpose inference machinery for probabilistic programs to infer probable causal structures and parameters from data. This abstract describes a prototype of this approach in the Gen probabilistic programming language.
Real-time Approximate Bayesian Computation for Scene Understanding
May 22, 2019



Consider scene understanding problems such as predicting where a person is probably reaching, or inferring the pose of 3D objects from depth images, or inferring the probable street crossings of pedestrians at a busy intersection. This paper shows how to solve these problems using Approximate Bayesian Computation. The underlying generative models are built from realistic simulation software, wrapped in a Bayesian error model for the gap between simulation outputs and real data. The simulators are drawn from off-the-shelf computer graphics, video game, and traffic simulation code. The paper introduces two techniques for speeding up inference that can be used separately or in combination. The first is to train neural surrogates of the simulators, using a simple form of domain randomization to make the surrogates more robust to the gap between the simulation and reality. The second is to adaptively discretize the latent variables using a Tree-pyramid approach adapted from computer graphics. This paper also shows performance and accuracy measurements on real-world problems, establishing that it is feasible to solve these problems in real-time.
Time Series Structure Discovery via Probabilistic Program Synthesis
May 22, 2017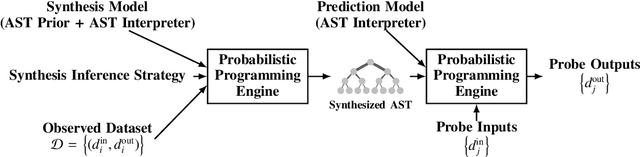


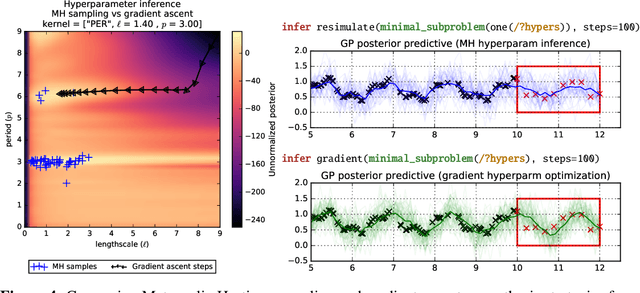
There is a widespread need for techniques that can discover structure from time series data. Recently introduced techniques such as Automatic Bayesian Covariance Discovery (ABCD) provide a way to find structure within a single time series by searching through a space of covariance kernels that is generated using a simple grammar. While ABCD can identify a broad class of temporal patterns, it is difficult to extend and can be brittle in practice. This paper shows how to extend ABCD by formulating it in terms of probabilistic program synthesis. The key technical ideas are to (i) represent models using abstract syntax trees for a domain-specific probabilistic language, and (ii) represent the time series model prior, likelihood, and search strategy using probabilistic programs in a sufficiently expressive language. The final probabilistic program is written in under 70 lines of probabilistic code in Venture. The paper demonstrates an application to time series clustering that involves a non-parametric extension to ABCD, experiments for interpolation and extrapolation on real-world econometric data, and improvements in accuracy over both non-parametric and standard regression baselines.
Probabilistic Search for Structured Data via Probabilistic Programming and Nonparametric Bayes
Apr 04, 2017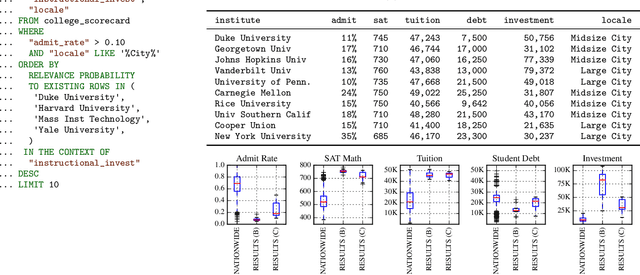

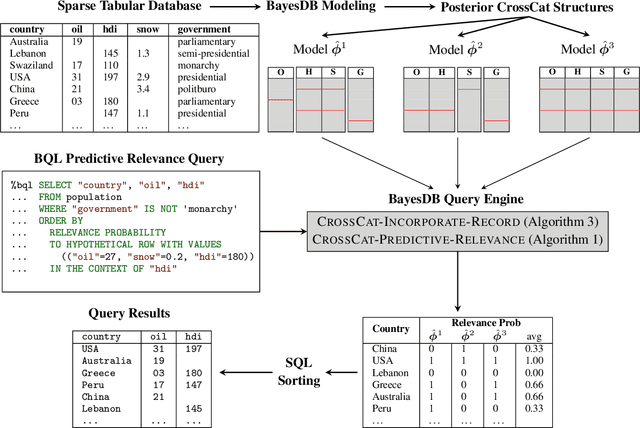
Databases are widespread, yet extracting relevant data can be difficult. Without substantial domain knowledge, multivariate search queries often return sparse or uninformative results. This paper introduces an approach for searching structured data based on probabilistic programming and nonparametric Bayes. Users specify queries in a probabilistic language that combines standard SQL database search operators with an information theoretic ranking function called predictive relevance. Predictive relevance can be calculated by a fast sparse matrix algorithm based on posterior samples from CrossCat, a nonparametric Bayesian model for high-dimensional, heterogeneously-typed data tables. The result is a flexible search technique that applies to a broad class of information retrieval problems, which we integrate into BayesDB, a probabilistic programming platform for probabilistic data analysis. This paper demonstrates applications to databases of US colleges, global macroeconomic indicators of public health, and classic cars. We found that human evaluators often prefer the results from probabilistic search to results from a standard baseline.
Detecting Dependencies in Sparse, Multivariate Databases Using Probabilistic Programming and Non-parametric Bayes
Mar 27, 2017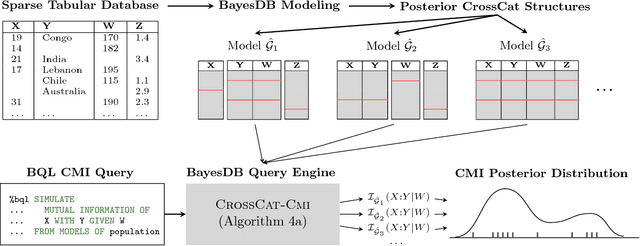
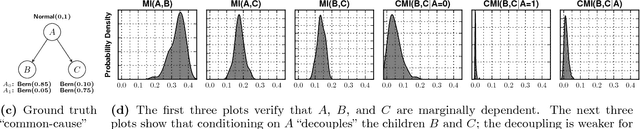

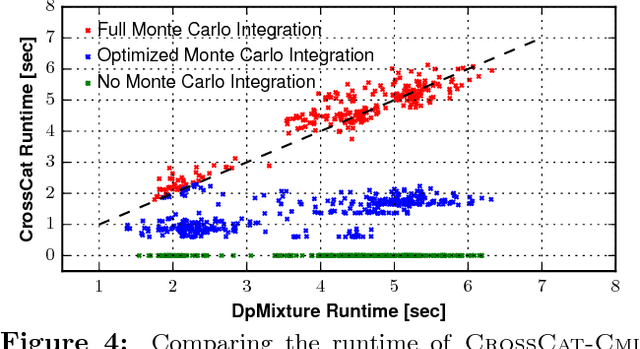
Datasets with hundreds of variables and many missing values are commonplace. In this setting, it is both statistically and computationally challenging to detect true predictive relationships between variables and also to suppress false positives. This paper proposes an approach that combines probabilistic programming, information theory, and non-parametric Bayes. It shows how to use Bayesian non-parametric modeling to (i) build an ensemble of joint probability models for all the variables; (ii) efficiently detect marginal independencies; and (iii) estimate the conditional mutual information between arbitrary subsets of variables, subject to a broad class of constraints. Users can access these capabilities using BayesDB, a probabilistic programming platform for probabilistic data analysis, by writing queries in a simple, SQL-like language. This paper demonstrates empirically that the method can (i) detect context-specific (in)dependencies on challenging synthetic problems and (ii) yield improved sensitivity and specificity over baselines from statistics and machine learning, on a real-world database of over 300 sparsely observed indicators of macroeconomic development and public health.
Probabilistic Data Analysis with Probabilistic Programming
Aug 18, 2016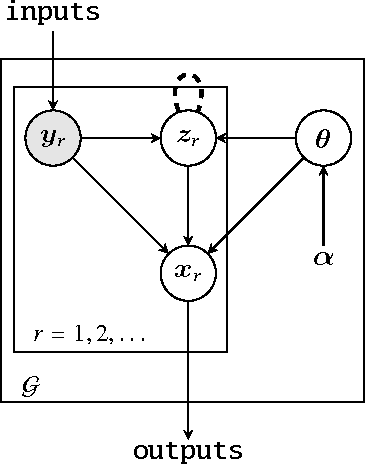


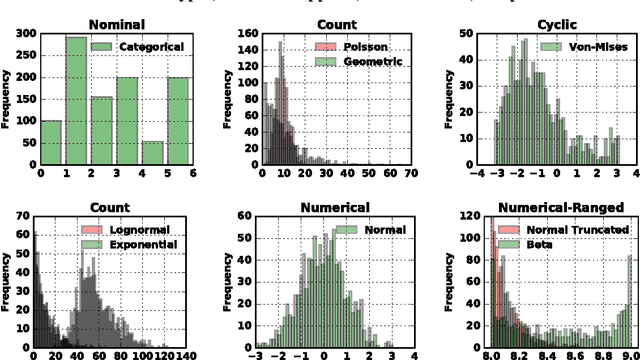
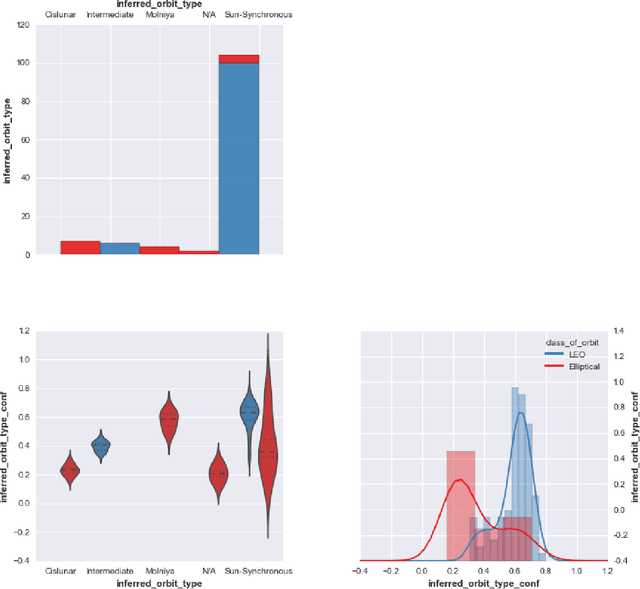
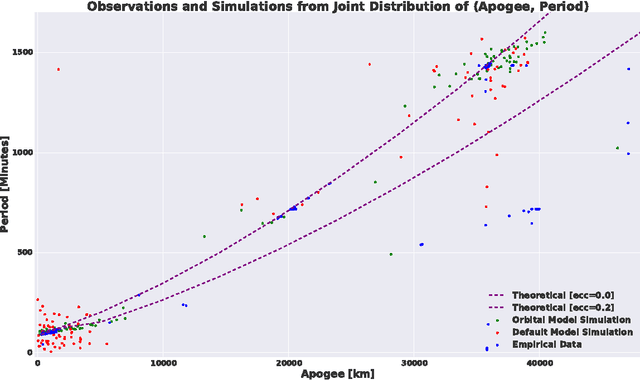
Probabilistic techniques are central to data analysis, but different approaches can be difficult to apply, combine, and compare. This paper introduces composable generative population models (CGPMs), a computational abstraction that extends directed graphical models and can be used to describe and compose a broad class of probabilistic data analysis techniques. Examples include hierarchical Bayesian models, multivariate kernel methods, discriminative machine learning, clustering algorithms, dimensionality reduction, and arbitrary probabilistic programs. We also demonstrate the integration of CGPMs into BayesDB, a probabilistic programming platform that can express data analysis tasks using a modeling language and a structured query language. The practical value is illustrated in two ways. First, CGPMs are used in an analysis that identifies satellite data records which probably violate Kepler's Third Law, by composing causal probabilistic programs with non-parametric Bayes in under 50 lines of probabilistic code. Second, for several representative data analysis tasks, we report on lines of code and accuracy measurements of various CGPMs, plus comparisons with standard baseline solutions from Python and MATLAB libraries.
BayesDB: A probabilistic programming system for querying the probable implications of data
Dec 15, 2015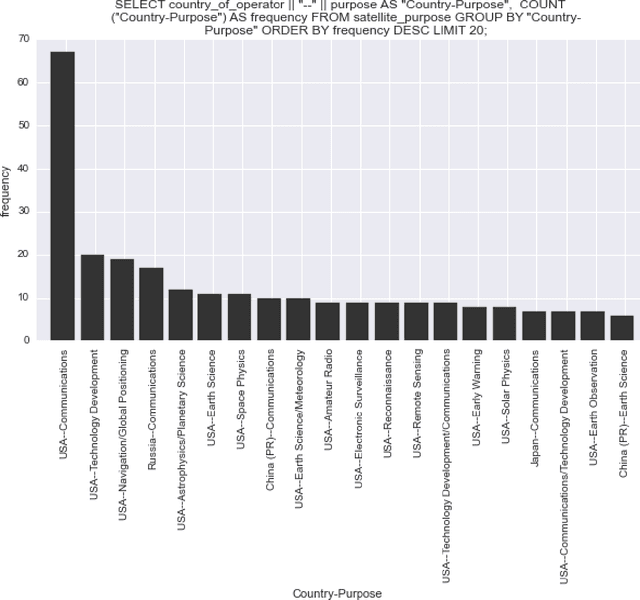
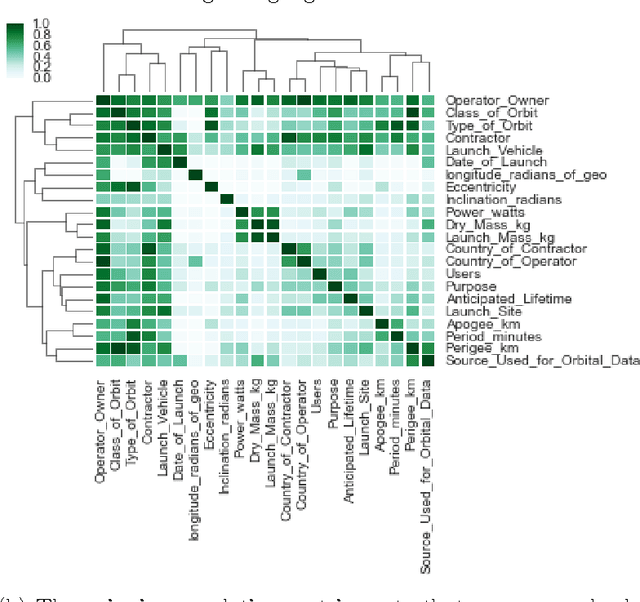
Is it possible to make statistical inference broadly accessible to non-statisticians without sacrificing mathematical rigor or inference quality? This paper describes BayesDB, a probabilistic programming platform that aims to enable users to query the probable implications of their data as directly as SQL databases enable them to query the data itself. This paper focuses on four aspects of BayesDB: (i) BQL, an SQL-like query language for Bayesian data analysis, that answers queries by averaging over an implicit space of probabilistic models; (ii) techniques for implementing BQL using a broad class of multivariate probabilistic models; (iii) a semi-parametric Bayesian model-builder that auomatically builds ensembles of factorial mixture models to serve as baselines; and (iv) MML, a "meta-modeling" language for imposing qualitative constraints on the model-builder and combining baseline models with custom algorithmic and statistical models that can be implemented in external software. BayesDB is illustrated using three applications: cleaning and exploring a public database of Earth satellites; assessing the evidence for temporal dependence between macroeconomic indicators; and analyzing a salary survey.