 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Multi-Modal Method for Patient Wound Healing Assessment
Feb 10, 2026Hospitalization of patients is one of the major factors for high wound care costs. Most patients do not acquire a wound which needs immediate hospitalization. However, due to factors such as delay in treatment, patient's non-compliance or existing co-morbid conditions, an injury can deteriorate and ultimately lead to patient hospitalization. In this paper, we propose a deep multi-modal method to predict the patient's risk of hospitalization. Our goal is to predict the risk confidently by collectively using the wound variables and wound images of the patient. Existing works in this domain have mainly focused on healing trajectories based on distinct wound types. We developed a transfer learning-based wound assessment solution, which can predict both wound variables from wound images and their healing trajectories, which is our primary contribution. We argue that the development of a novel model can help in early detection of the complexities in the wound, which might affect the healing process and also reduce the time spent by a clinician to diagnose the wound.
* 4 pages, 2 figures
Linguistic properties and model scale in brain encoding: from small to compressed language models
Feb 07, 2026Recent work has shown that scaling large language models (LLMs) improves their alignment with human brain activity, yet it remains unclear what drives these gains and which representational properties are responsible. Although larger models often yield better task performance and brain alignment, they are increasingly difficult to analyze mechanistically. This raises a fundamental question: what is the minimal model capacity required to capture brain-relevant representations? To address this question, we systematically investigate how constraining model scale and numerical precision affects brain alignment. We compare full-precision LLMs, small language models (SLMs), and compressed variants (quantized and pruned) by predicting fMRI responses during naturalistic language comprehension. Across model families up to 14B parameters, we find that 3B SLMs achieve brain predictivity indistinguishable from larger LLMs, whereas 1B models degrade substantially, particularly in semantic language regions. Brain alignment is remarkably robust to compression: most quantization and pruning methods preserve neural predictivity, with GPTQ as a consistent exception. Linguistic probing reveals a dissociation between task performance and brain predictivity: compression degrades discourse, syntax, and morphology, yet brain predictivity remains largely unchanged. Overall, brain alignment saturates at modest model scales and is resilient to compression, challenging common assumptions about neural scaling and motivating compact models for brain-aligned language modeling.
Visio-Linguistic Brain Encoding
Apr 18, 2022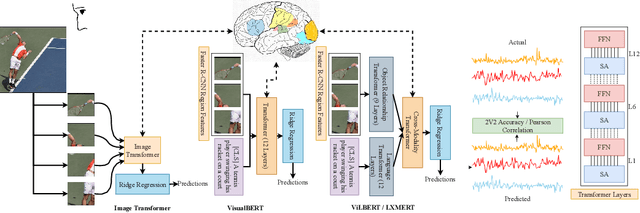
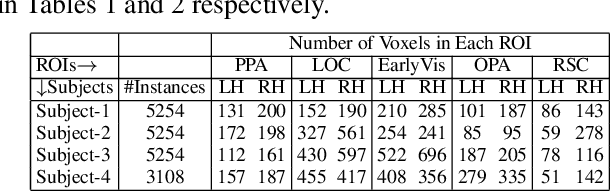
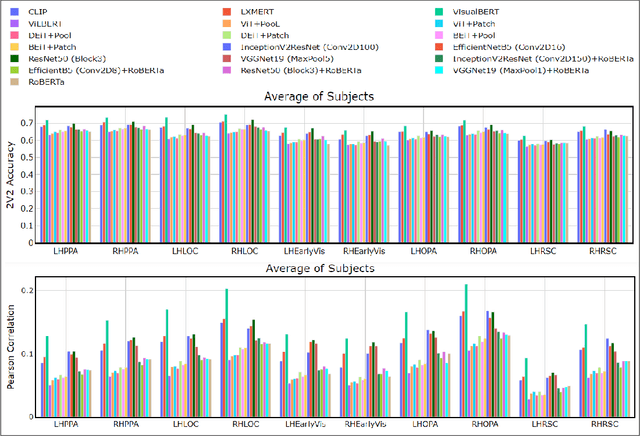
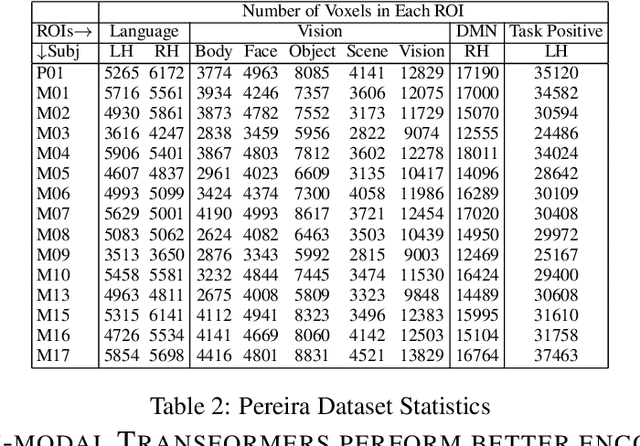
Enabling effective brain-computer interfaces requires understanding how the human brain encodes stimuli across modalities such as visual, language (or text), etc. Brain encoding aims at constructing fMRI brain activity given a stimulus. There exists a plethora of neural encoding models which study brain encoding for single mode stimuli: visual (pretrained CNNs) or text (pretrained language models). Few recent papers have also obtained separate visual and text representation models and performed late-fusion using simple heuristics. However, previous work has failed to explore: (a) the effectiveness of image Transformer models for encoding visual stimuli, and (b) co-attentive multi-modal modeling for visual and text reasoning. In this paper, we systematically explore the efficacy of image Transformers (ViT, DEiT, and BEiT) and multi-modal Transformers (VisualBERT, LXMERT, and CLIP) for brain encoding. Extensive experiments on two popular datasets, BOLD5000 and Pereira, provide the following insights. (1) To the best of our knowledge, we are the first to investigate the effectiveness of image and multi-modal Transformers for brain encoding. (2) We find that VisualBERT, a multi-modal Transformer, significantly outperforms previously proposed single-mode CNNs, image Transformers as well as other previously proposed multi-modal models, thereby establishing new state-of-the-art. The supremacy of visio-linguistic models raises the question of whether the responses elicited in the visual regions are affected implicitly by linguistic processing even when passively viewing images. Future fMRI tasks can verify this computational insight in an appropriate experimental setting.