 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain alignment of reasoning and action representations from vision-language and action models during naturalistic gameplay
May 19, 2026Understanding how humans and artificial intelligence systems predict and plan by interacting with their environment is a fundamental challenge at the intersection of neuroscience and machine learning. Most brain-encoding studies focus on aligning artificial models with brain activity during language comprehension or passive visual processing, while interactive brain-alignment studies have to date been largely limited to reinforcement-learning (RL) agents and theory-based models. To address this gap, we study brain alignment of representative models from two foundation-model families, namely vision-language models (VLMs) and large-action models (LAMs), using fMRI recordings from participants playing naturalistic Atari-style video games. Specifically, we examine how action-focused and reasoning-focused prompts shape model's internal representations and align with fMRI brain activity. First, we find that both VLMs and LAMs exhibit significantly exhibit voxel-wise encoding performance than RL baselines, with the advantage holding even under matched feature dimensionality. Second, prompt-driven gains scale with the cortical processing hierarchy: the largest improvements appear in frontal-parietal and motor-planning regions, while early visual cortex gains roughly half as much. Third, variance partitioning reveals a qualitatively different representational organization: VLM is prompt-symmetric (12.5% unique action vs. 13.6% unique reasoning), whereas LAM is prompt-asymmetric (27% unique action vs. -5% unique reasoning), with the asymmetry strongest in frontal-motor cortex. Together, these results demonstrate that action-specialized fine-tuning reorganizes multimodal representations toward action-relevant neural computations even when whole-brain prediction accuracy is statistically equivalent between VLM and LAM.
How does longer temporal context enhance multimodal narrative video processing in the brain?
Feb 07, 2026Understanding how humans and artificial intelligence systems process complex narrative videos is a fundamental challenge at the intersection of neuroscience and machine learning. This study investigates how the temporal context length of video clips (3--12 s clips) and the narrative-task prompting shape brain-model alignment during naturalistic movie watching. Using fMRI recordings from participants viewing full-length movies, we examine how brain regions sensitive to narrative context dynamically represent information over varying timescales and how these neural patterns align with model-derived features. We find that increasing clip duration substantially improves brain alignment for multimodal large language models (MLLMs), whereas unimodal video models show little to no gain. Further, shorter temporal windows align with perceptual and early language regions, while longer windows preferentially align higher-order integrative regions, mirrored by a layer-to-cortex hierarchy in MLLMs. Finally, narrative-task prompts (multi-scene summary, narrative summary, character motivation, and event boundary detection) elicit task-specific, region-dependent brain alignment patterns and context-dependent shifts in clip-level tuning in higher-order regions. Together, our results position long-form narrative movies as a principled testbed for probing biologically relevant temporal integration and interpretable representations in long-context MLLMs.
Linguistic properties and model scale in brain encoding: from small to compressed language models
Feb 07, 2026Recent work has shown that scaling large language models (LLMs) improves their alignment with human brain activity, yet it remains unclear what drives these gains and which representational properties are responsible. Although larger models often yield better task performance and brain alignment, they are increasingly difficult to analyze mechanistically. This raises a fundamental question: what is the minimal model capacity required to capture brain-relevant representations? To address this question, we systematically investigate how constraining model scale and numerical precision affects brain alignment. We compare full-precision LLMs, small language models (SLMs), and compressed variants (quantized and pruned) by predicting fMRI responses during naturalistic language comprehension. Across model families up to 14B parameters, we find that 3B SLMs achieve brain predictivity indistinguishable from larger LLMs, whereas 1B models degrade substantially, particularly in semantic language regions. Brain alignment is remarkably robust to compression: most quantization and pruning methods preserve neural predictivity, with GPTQ as a consistent exception. Linguistic probing reveals a dissociation between task performance and brain predictivity: compression degrades discourse, syntax, and morphology, yet brain predictivity remains largely unchanged. Overall, brain alignment saturates at modest model scales and is resilient to compression, challenging common assumptions about neural scaling and motivating compact models for brain-aligned language modeling.
Instruction-Tuned Video-Audio Models Elucidate Functional Specialization in the Brain
Jun 09, 2025Recent voxel-wise multimodal brain encoding studies have shown that multimodal large language models (MLLMs) exhibit a higher degree of brain alignment compared to unimodal models in both unimodal and multimodal stimulus settings. More recently, instruction-tuned multimodal models have shown to generate task-specific representations that align strongly with brain activity. However, prior work evaluating the brain alignment of MLLMs has primarily focused on unimodal settings or relied on non-instruction-tuned multimodal models for multimodal stimuli. To address this gap, we investigated brain alignment, that is, measuring the degree of predictivity of neural activity recorded while participants were watching naturalistic movies (video along with audio) with representations derived from MLLMs. We utilized instruction-specific embeddings from six video and two audio instruction-tuned MLLMs. Experiments with 13 video task-specific instructions show that instruction-tuned video MLLMs significantly outperform non-instruction-tuned multimodal (by 15%) and unimodal models (by 20%). Our evaluation of MLLMs for both video and audio tasks using language-guided instructions shows clear disentanglement in task-specific representations from MLLMs, leading to precise differentiation of multimodal functional processing in the brain. We also find that MLLM layers align hierarchically with the brain, with early sensory areas showing strong alignment with early layers, while higher-level visual and language regions align more with middle to late layers. These findings provide clear evidence for the role of task-specific instructions in improving the alignment between brain activity and MLLMs, and open new avenues for mapping joint information processing in both the systems. We make the code publicly available [https://github.com/subbareddy248/mllm_videos].
Multi-modal brain encoding models for multi-modal stimuli
May 26, 2025Despite participants engaging in unimodal stimuli, such as watching images or silent videos, recent work has demonstrated that multi-modal Transformer models can predict visual brain activity impressively well, even with incongruent modality representations. This raises the question of how accurately these multi-modal models can predict brain activity when participants are engaged in multi-modal stimuli. As these models grow increasingly popular, their use in studying neural activity provides insights into how our brains respond to such multi-modal naturalistic stimuli, i.e., where it separates and integrates information across modalities through a hierarchy of early sensory regions to higher cognition. We investigate this question by using multiple unimodal and two types of multi-modal models-cross-modal and jointly pretrained-to determine which type of model is more relevant to fMRI brain activity when participants are engaged in watching movies. We observe that both types of multi-modal models show improved alignment in several language and visual regions. This study also helps in identifying which brain regions process unimodal versus multi-modal information. We further investigate the contribution of each modality to multi-modal alignment by carefully removing unimodal features one by one from multi-modal representations, and find that there is additional information beyond the unimodal embeddings that is processed in the visual and language regions. Based on this investigation, we find that while for cross-modal models, their brain alignment is partially attributed to the video modality; for jointly pretrained models, it is partially attributed to both the video and audio modalities. This serves as a strong motivation for the neuroscience community to investigate the interpretability of these models for deepening our understanding of multi-modal information processing in brain.
* 26 pages, 15 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=0dELcFHig2
Correlating instruction-tuning (in multimodal models) with vision-language processing (in the brain)
May 26, 2025Transformer-based language models, though not explicitly trained to mimic brain recordings, have demonstrated surprising alignment with brain activity. Progress in these models-through increased size, instruction-tuning, and multimodality-has led to better representational alignment with neural data. Recently, a new class of instruction-tuned multimodal LLMs (MLLMs) have emerged, showing remarkable zero-shot capabilities in open-ended multimodal vision tasks. However, it is unknown whether MLLMs, when prompted with natural instructions, lead to better brain alignment and effectively capture instruction-specific representations. To address this, we first investigate brain alignment, i.e., measuring the degree of predictivity of neural visual activity using text output response embeddings from MLLMs as participants engage in watching natural scenes. Experiments with 10 different instructions show that MLLMs exhibit significantly better brain alignment than vision-only models and perform comparably to non-instruction-tuned multimodal models like CLIP. We also find that while these MLLMs are effective at generating high-quality responses suitable to the task-specific instructions, not all instructions are relevant for brain alignment. Further, by varying instructions, we make the MLLMs encode instruction-specific visual concepts related to the input image. This analysis shows that MLLMs effectively capture count-related and recognition-related concepts, demonstrating strong alignment with brain activity. Notably, the majority of the explained variance of the brain encoding models is shared between MLLM embeddings of image captioning and other instructions. These results suggest that enhancing MLLMs' ability to capture task-specific information could lead to better differentiation between various types of instructions, and thereby improving their precision in predicting brain responses.
* 30 pages, 22 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=xkgfLXZ4e0
mulEEG: A Multi-View Representation Learning on EEG Signals
Apr 07, 2022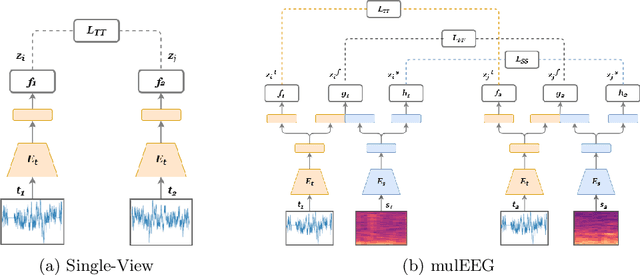
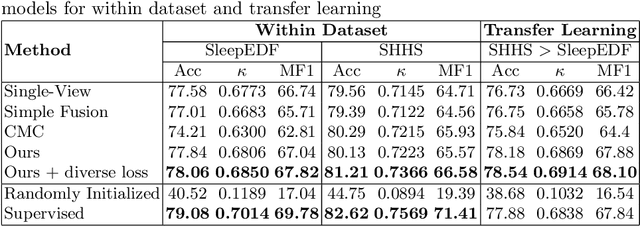
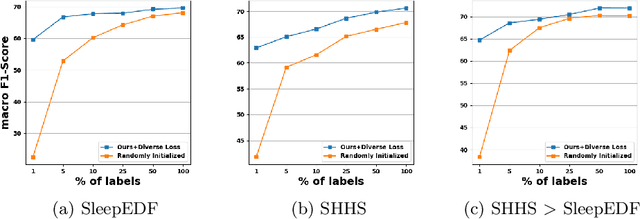
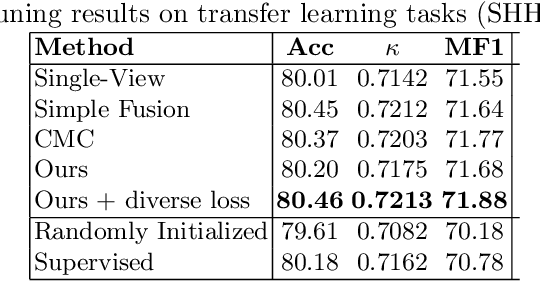
Modeling effective representations using multiple views that positively influence each other is challenging, and the existing methods perform poorly on Electroencephalogram (EEG) signals for sleep-staging tasks. In this paper, we propose a novel multi-view self-supervised method (mulEEG) for unsupervised EEG representation learning. Our method attempts to effectively utilize the complementary information available in multiple views to learn better representations. We introduce diverse loss that further encourages complementary information across multiple views. Our method with no access to labels beats the supervised training while outperforming multi-view baseline methods on transfer learning experiments carried out on sleep-staging tasks. We posit that our method was able to learn better representations by using complementary multi-views.