 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactsR: A Safer Method for Producing High Quality Healthcare Documentation
May 15, 2025
There are now a multitude of AI-scribing solutions for healthcare promising the utilization of large language models for ambient documentation. However, these AI scribes still rely on one-shot, or few-shot prompts for generating notes after the consultation has ended, employing little to no reasoning. This risks long notes with an increase in hallucinations, misrepresentation of the intent of the clinician, and reliance on the proofreading of the clinician to catch errors. A dangerous combination for patient safety if vigilance is compromised by workload and fatigue. In this paper, we introduce a method for extracting salient clinical information in real-time alongside the healthcare consultation, denoted Facts, and use that information recursively to generate the final note. The FactsR method results in more accurate and concise notes by placing the clinician-in-the-loop of note generation, while opening up new use cases within real-time decision support.
The Impact of Differential Privacy on Group Disparity Mitigation
Mar 05, 2022
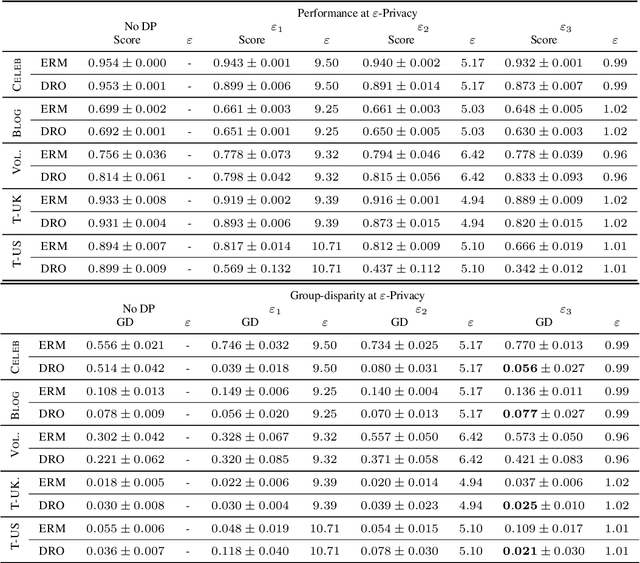
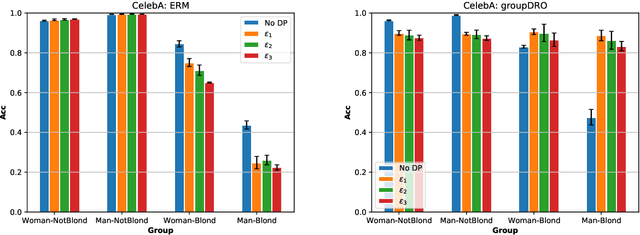
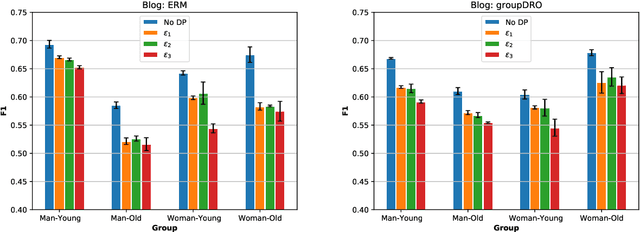
The performance cost of differential privacy has, for some applications, been shown to be higher for minority groups; fairness, conversely, has been shown to disproportionally compromise the privacy of members of such groups. Most work in this area has been restricted to computer vision and risk assessment. In this paper, we evaluate the impact of differential privacy on fairness across four tasks, focusing on how attempts to mitigate privacy violations and between-group performance differences interact: Does privacy inhibit attempts to ensure fairness? To this end, we train $(\varepsilon,\delta)$-differentially private models with empirical risk minimization and group distributionally robust training objectives. Consistent with previous findings, we find that differential privacy increases between-group performance differences in the baseline setting; but more interestingly, differential privacy reduces between-group performance differences in the robust setting. We explain this by reinterpreting differential privacy as regularization.
What Do You Mean `Why?': Resolving Sluices in Conversations
Nov 21, 2019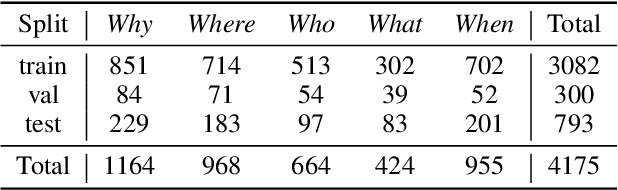
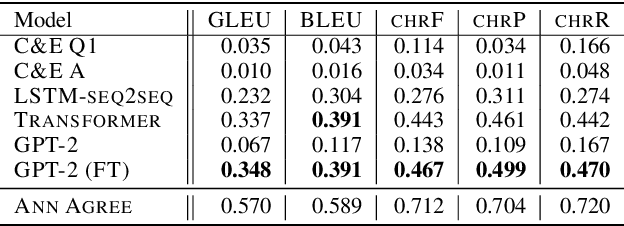
In conversation, we often ask one-word questions such as `Why?' or `Who?'. Such questions are typically easy for humans to answer, but can be hard for computers, because their resolution requires retrieving both the right semantic frames and the right arguments from context. This paper introduces the novel ellipsis resolution task of resolving such one-word questions, referred to as sluices in linguistics. We present a crowd-sourced dataset containing annotations of sluices from over 4,000 dialogues collected from conversational QA datasets, as well as a series of strong baseline architectures.
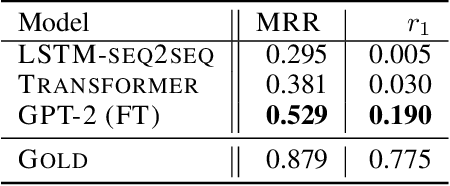
Domain Transfer in Dialogue Systems without Turn-Level Supervision
Sep 16, 2019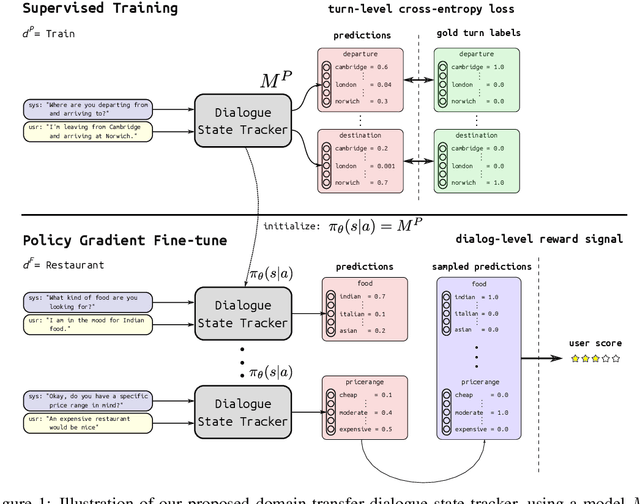

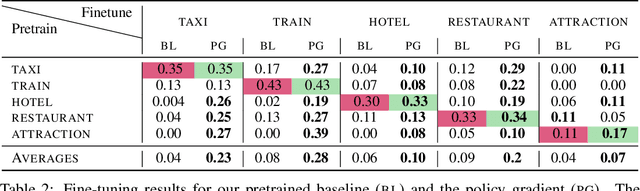
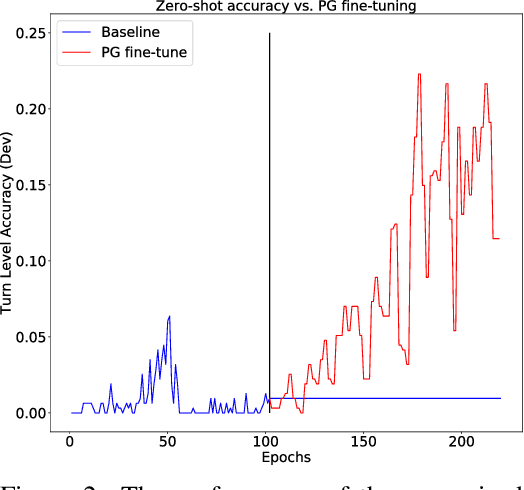
Task oriented dialogue systems rely heavily on specialized dialogue state tracking (DST) modules for dynamically predicting user intent throughout the conversation. State-of-the-art DST models are typically trained in a supervised manner from manual annotations at the turn level. However, these annotations are costly to obtain, which makes it difficult to create accurate dialogue systems for new domains. To address these limitations, we propose a method, based on reinforcement learning, for transferring DST models to new domains without turn-level supervision. Across several domains, our experiments show that this method quickly adapts off-the-shelf models to new domains and performs on par with models trained with turn-level supervision. We also show our method can improve models trained using turn-level supervision by subsequent fine-tuning optimization toward dialog-level rewards.