 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularizing Educational LLM-Agency for Fostering Responsible Learning Assistance
May 28, 2026The widespread adoption of AI chatbots in education will drastically change learning, making responsible deployment a critical concern. While large language models (LLMs) might have access to sources discussing insights from educational sciences, they are not particularly inclined to adhere to pedagogical concepts, risking negative effects on the learning process, such as a loss of transfer capabilities, critical thinking, or creativity. In this paper, we introduce an agentic AI chatbot architecture assisting students with exercise solving, specifically designed to contribute to more responsible AI use in education. We base our conceptual development on the identification of several desiderata for responsible LLM-based educational systems, argue for the structural shortcomings inherent in monolithic, out-of-the-box solutions, and instead suggest modularizing the agentic architecture. We propose specific modules for different stages of exercise solving, enabling incorporation of targeted pedagogical advice, guiding students through the learning process in a more controllable, transparent, and overseeable manner.
B-cos GNNs: Faithful Explanations through Dynamic Linearity
May 19, 2026We introduce B-cos GNNs, an inherently explainable class of graph neural networks whose predictions decompose exactly into per-node, per-feature contributions via a single input-dependent linear map. B-cos GNNs use linear (sum-based) aggregation and replace non-linear message and update functions with B-cos transforms. This induces meaningful, task-specific weight-input alignment that is directly accessible through the model's dynamic linearity. Instance-level explanations follow from a single forward and backward pass, requiring no auxiliary explainer, modified learning objective, or perturbation procedure. Instantiated as a GIN, our approach trades small losses in predictive accuracy for state-of-the-art explainability across diverse synthetic and real-world benchmarks, producing explanations orders of magnitude faster than post-hoc baselines.
Per-Domain Generalizing Policies: On Validation Instances and Scaling Behavior
May 01, 2025Recent work has shown that successful per-domain generalizing action policies can be learned. Scaling behavior, from small training instances to large test instances, is the key objective; and the use of validation instances larger than training instances is one key to achieve it. Prior work has used fixed validation sets. Here, we introduce a method generating the validation set dynamically, on the fly, increasing instance size so long as informative and feasible.We also introduce refined methodology for evaluating scaling behavior, generating test instances systematically to guarantee a given confidence in coverage performance for each instance size. In experiments, dynamic validation improves scaling behavior of GNN policies in all 9 domains used.
Exploring Molecule Generation Using Latent Space Graph Diffusion
Jan 07, 2025



Generating molecular graphs is a challenging task due to their discrete nature and the competitive objectives involved. Diffusion models have emerged as SOTA approaches in data generation across various modalities. For molecular graphs, graph neural networks (GNNs) as a diffusion backbone have achieved impressive results. Latent space diffusion, where diffusion occurs in a low-dimensional space via an autoencoder, has demonstrated computational efficiency. However, the literature on latent space diffusion for molecular graphs is scarce, and no commonly accepted best practices exist. In this work, we explore different approaches and hyperparameters, contrasting generative flow models (denoising diffusion, flow matching, heat dissipation) and architectures (GNNs and E(3)-equivariant GNNs). Our experiments reveal a high sensitivity to the choice of approach and design decisions. Code is made available at github.com/Prashanth-Pombala/Molecule-Generation-using-Latent-Space-Graph-Diffusion.
Enhancing GNNs with Architecture-Agnostic Graph Transformations: A Systematic Analysis
Oct 11, 2024In recent years, a wide variety of graph neural network (GNN) architectures have emerged, each with its own strengths, weaknesses, and complexities. Various techniques, including rewiring, lifting, and node annotation with centrality values, have been employed as pre-processing steps to enhance GNN performance. However, there are no universally accepted best practices, and the impact of architecture and pre-processing on performance often remains opaque. This study systematically explores the impact of various graph transformations as pre-processing steps on the performance of common GNN architectures across standard datasets. The models are evaluated based on their ability to distinguish non-isomorphic graphs, referred to as expressivity. Our findings reveal that certain transformations, particularly those augmenting node features with centrality measures, consistently improve expressivity. However, these gains come with trade-offs, as methods like graph encoding, while enhancing expressivity, introduce numerical inaccuracies widely-used python packages. Additionally, we observe that these pre-processing techniques are limited when addressing complex tasks involving 3-WL and 4-WL indistinguishable graphs.
GINA: Neural Relational Inference From Independent Snapshots
May 29, 2021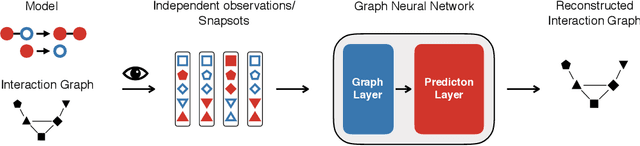
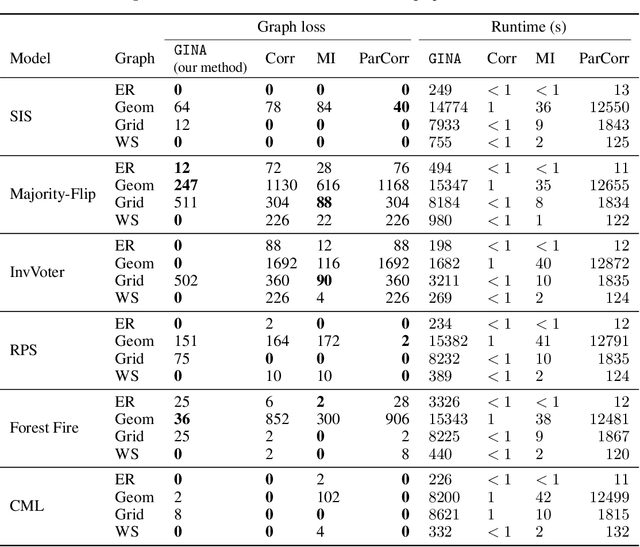
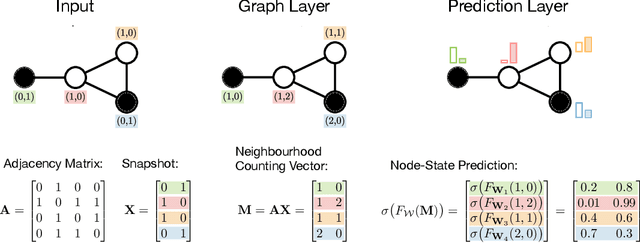
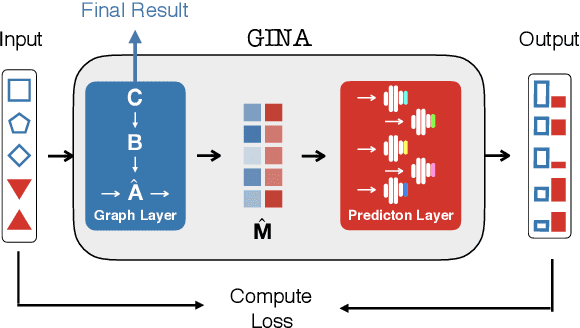
Dynamical systems in which local interactions among agents give rise to complex emerging phenomena are ubiquitous in nature and society. This work explores the problem of inferring the unknown interaction structure (represented as a graph) of such a system from measurements of its constituent agents or individual components (represented as nodes). We consider a setting where the underlying dynamical model is unknown and where different measurements (i.e., snapshots) may be independent (e.g., may stem from different experiments). We propose GINA (Graph Inference Network Architecture), a graph neural network (GNN) to simultaneously learn the latent interaction graph and, conditioned on the interaction graph, the prediction of a node's observable state based on adjacent vertices. GINA is based on the hypothesis that the ground truth interaction graph -- among all other potential graphs -- allows to predict the state of a node, given the states of its neighbors, with the highest accuracy. We test this hypothesis and demonstrate GINA's effectiveness on a wide range of interaction graphs and dynamical processes.
Abstraction-Guided Truncations for Stationary Distributions of Markov Population Models
May 03, 2021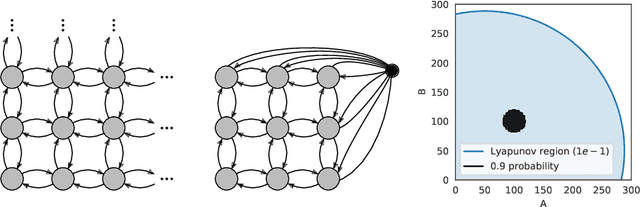
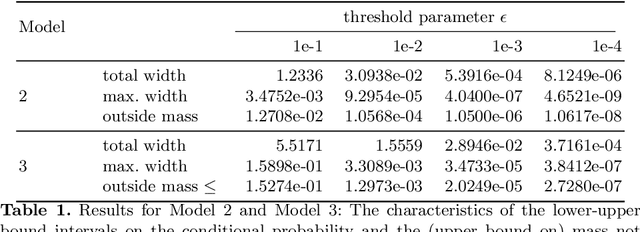
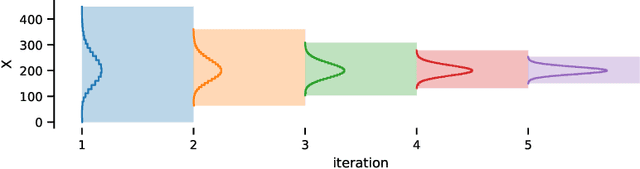
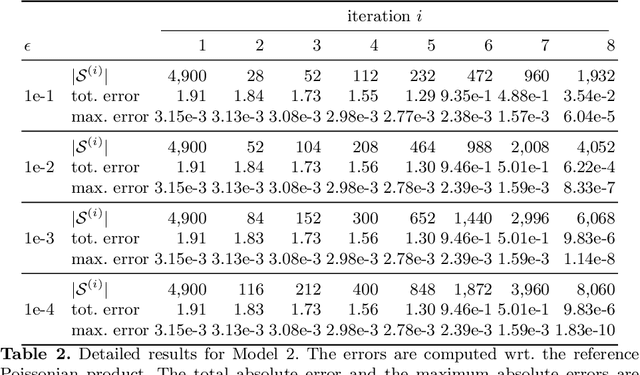
To understand the long-run behavior of Markov population models, the computation of the stationary distribution is often a crucial part. We propose a truncation-based approximation that employs a state-space lumping scheme, aggregating states in a grid structure. The resulting approximate stationary distribution is used to iteratively refine relevant and truncate irrelevant parts of the state-space. This way, the algorithm learns a well-justified finite-state projection tailored to the stationary behavior. We demonstrate the method's applicability to a wide range of non-linear problems with complex stationary behaviors.
Tracking the Race Between Deep Reinforcement Learning and Imitation Learning -- Extended Version
Aug 03, 2020


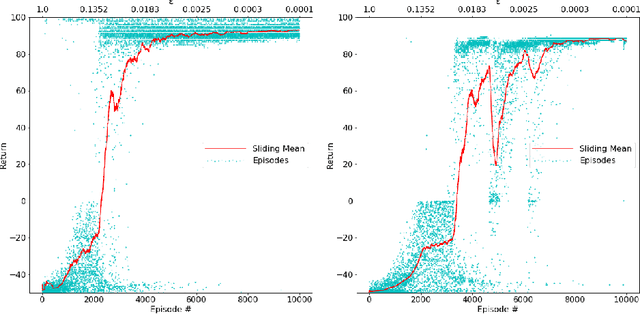
Learning-based approaches for solving large sequential decision making problems have become popular in recent years. The resulting agents perform differently and their characteristics depend on those of the underlying learning approach. Here, we consider a benchmark planning problem from the reinforcement learning domain, the Racetrack, to investigate the properties of agents derived from different deep (reinforcement) learning approaches. We compare the performance of deep supervised learning, in particular imitation learning, to reinforcement learning for the Racetrack model. We find that imitation learning yields agents that follow more risky paths. In contrast, the decisions of deep reinforcement learning are more foresighted, i.e., avoid states in which fatal decisions are more likely. Our evaluations show that for this sequential decision making problem, deep reinforcement learning performs best in many aspects even though for imitation learning optimal decisions are considered.