 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularizing Educational LLM-Agency for Fostering Responsible Learning Assistance
May 28, 2026The widespread adoption of AI chatbots in education will drastically change learning, making responsible deployment a critical concern. While large language models (LLMs) might have access to sources discussing insights from educational sciences, they are not particularly inclined to adhere to pedagogical concepts, risking negative effects on the learning process, such as a loss of transfer capabilities, critical thinking, or creativity. In this paper, we introduce an agentic AI chatbot architecture assisting students with exercise solving, specifically designed to contribute to more responsible AI use in education. We base our conceptual development on the identification of several desiderata for responsible LLM-based educational systems, argue for the structural shortcomings inherent in monolithic, out-of-the-box solutions, and instead suggest modularizing the agentic architecture. We propose specific modules for different stages of exercise solving, enabling incorporation of targeted pedagogical advice, guiding students through the learning process in a more controllable, transparent, and overseeable manner.
Per-Domain Generalizing Policies: On Learning Efficient and Robust Q-Value Functions (Extended Version with Technical Appendix)
Mar 18, 2026Learning per-domain generalizing policies is a key challenge in learning for planning. Standard approaches learn state-value functions represented as graph neural networks using supervised learning on optimal plans generated by a teacher planner. In this work, we advocate for learning Q-value functions instead. Such policies are drastically cheaper to evaluate for a given state, as they need to process only the current state rather than every successor. Surprisingly, vanilla supervised learning of Q-values performs poorly as it does not learn to distinguish between the actions taken and those not taken by the teacher. We address this by using regularization terms that enforce this distinction, resulting in Q-value policies that consistently outperform state-value policies across a range of 10 domains and are competitive with the planner LAMA-first.
Per-Domain Generalizing Policies: On Validation Instances and Scaling Behavior
May 01, 2025Recent work has shown that successful per-domain generalizing action policies can be learned. Scaling behavior, from small training instances to large test instances, is the key objective; and the use of validation instances larger than training instances is one key to achieve it. Prior work has used fixed validation sets. Here, we introduce a method generating the validation set dynamically, on the fly, increasing instance size so long as informative and feasible.We also introduce refined methodology for evaluating scaling behavior, generating test instances systematically to guarantee a given confidence in coverage performance for each instance size. In experiments, dynamic validation improves scaling behavior of GNN policies in all 9 domains used.
Tracking the Race Between Deep Reinforcement Learning and Imitation Learning -- Extended Version
Aug 03, 2020


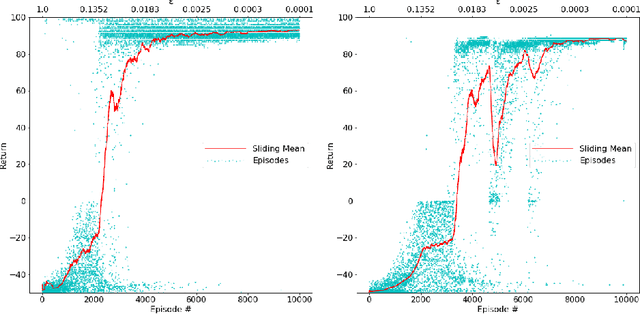
Learning-based approaches for solving large sequential decision making problems have become popular in recent years. The resulting agents perform differently and their characteristics depend on those of the underlying learning approach. Here, we consider a benchmark planning problem from the reinforcement learning domain, the Racetrack, to investigate the properties of agents derived from different deep (reinforcement) learning approaches. We compare the performance of deep supervised learning, in particular imitation learning, to reinforcement learning for the Racetrack model. We find that imitation learning yields agents that follow more risky paths. In contrast, the decisions of deep reinforcement learning are more foresighted, i.e., avoid states in which fatal decisions are more likely. Our evaluations show that for this sequential decision making problem, deep reinforcement learning performs best in many aspects even though for imitation learning optimal decisions are considered.