 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Bridge Component Recognition using Video Data
Sep 28, 2018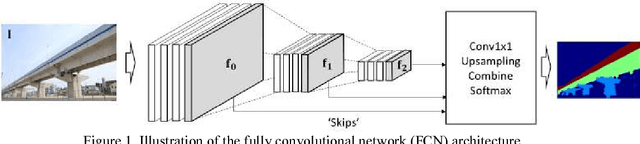
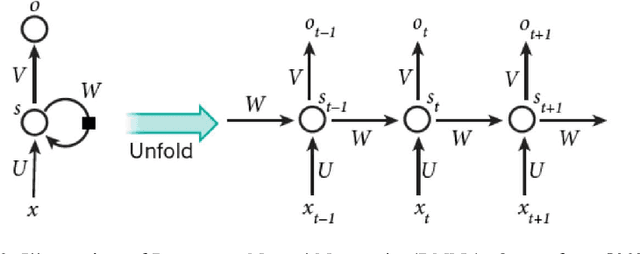
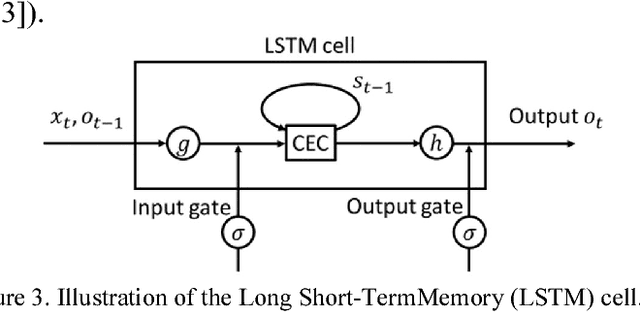
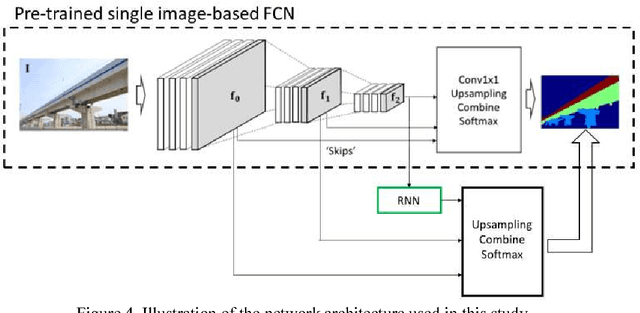
This paper investigates the automated recognition of structural bridge components using video data. Although understanding video data for structural inspections is straightforward for human inspectors, the implementation of the same task using machine learning methods has not been fully realized. In particular, single-frame image processing techniques, such as convolutional neural networks (CNNs), are not expected to identify structural components accurately when the image is a close-up view, lacking contextual information regarding where on the structure the image originates. Inspired by the significant progress in video processing techniques, this study investigates automated bridge component recognition using video data, where the information from the past frames is used to augment the understanding of the current frame. A new simulated video dataset is created to train the machine learning algorithms. Then, convolutional Neural Networks (CNNs) with recurrent architectures are designed and applied to implement the automated bridge component recognition task. Results are presented for simulated video data, as well as video collected in the field.
Towards Automated Post-Earthquake Inspections with Deep Learning-based Condition-Aware Models
Sep 24, 2018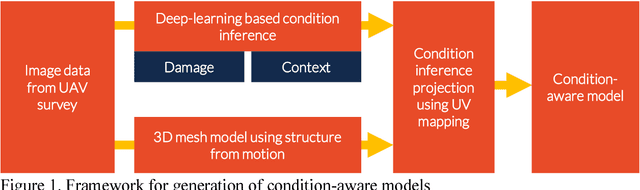
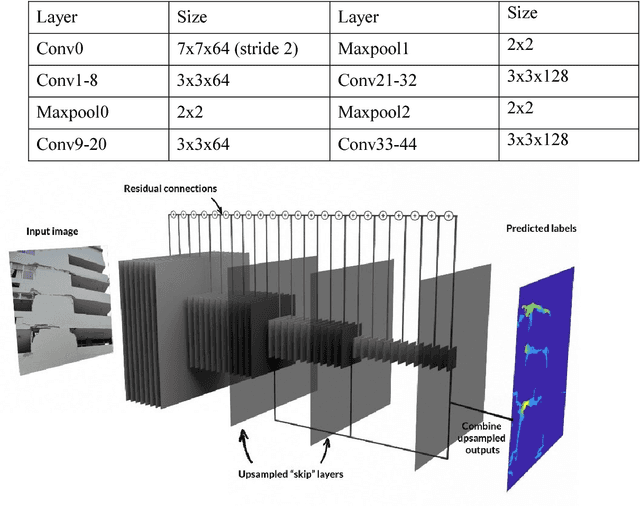
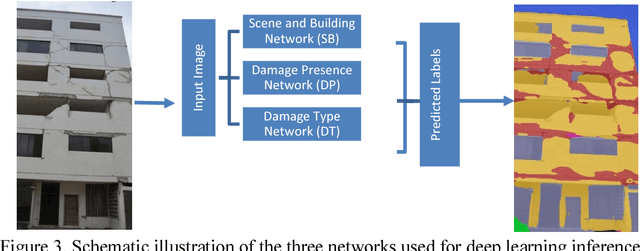

In the aftermath of an earthquake, rapid structural inspections are required to get citizens back in to their homes and offices in a safe and timely manner. These inspections gfare typically conducted by municipal authorities through structural engineer volunteers. As manual inspec-tions can be time consuming, laborious and dangerous, research has been underway to develop methods to help speed up and increase the automation of the entire process. Researchers typi-cally envisage the use of unmanned aerial vehicles (UAV) for data acquisition and computer vision for data processing to extract actionable information. In this work we propose a new framework to generate vision-based condition-aware models that can serve as the basis for speeding up or automating higher level inspection decisions. The condition-aware models are generated by projecting the inference of trained deep-learning models on a set of images of a structure onto a 3D mesh model generated through multi-view stereo from the same image set. Deep fully convolutional residual networks are used for semantic segmentation of images of buildings to provide (i) damage information such as cracks and spalling (ii) contextual infor-mation such as the presence of a building and visually identifiable components like windows and doors. The proposed methodology was implemented on a damaged building that was sur-veyed by the authors after the Central Mexico Earthquake in September 2017 and qualitative-ly evaluated. Results demonstrate the promise of the proposed method towards the ultimate goal of rapid and automated post-earthquake inspections.
Automated Vision-based Bridge Component Extraction Using Multiscale Convolutional Neural Networks
May 15, 2018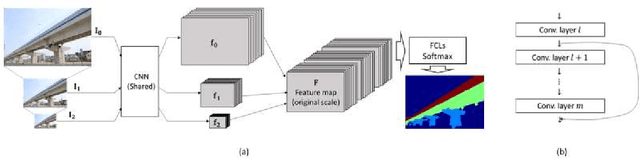
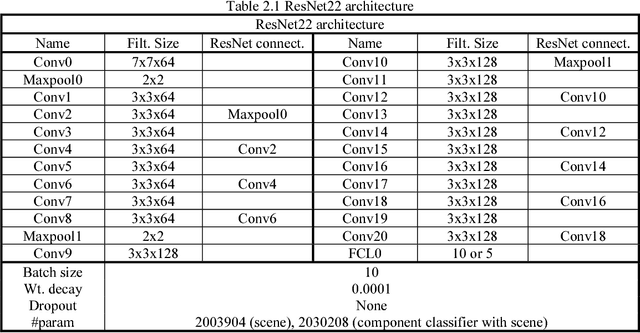
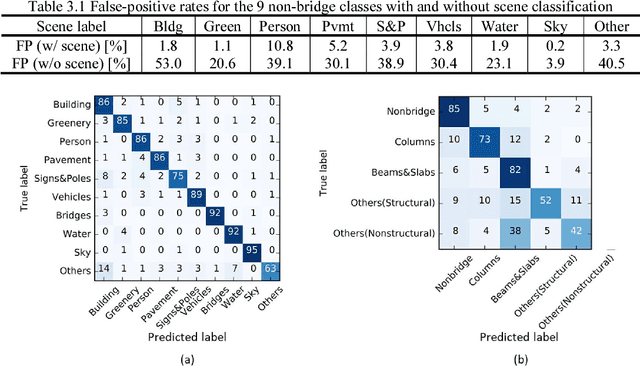
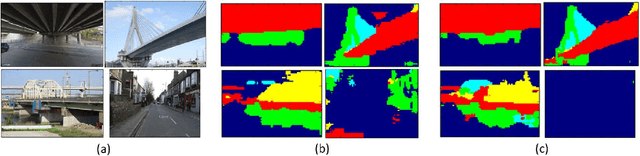
Image data has a great potential of helping post-earthquake visual inspections of civil engineering structures due to the ease of data acquisition and the advantages in capturing visual information. A variety of techniques have been applied to detect damages automatically from a close-up image of a structural component. However, the application of the automatic damage detection methods become increasingly difficult when the image includes multiple components from different structures. To reduce the inaccurate false positive alarms, critical structural components need to be recognized first, and the damage alarms need to be cleaned using the component recognition results. To achieve the goal, this study aims at recognizing and extracting bridge components from images of urban scenes. The bridge component recognition begins with pixel-wise classifications of an image into 10 scene classes. Then, the original image and the scene classification results are combined to classify the image pixels into five component classes. The multi-scale convolutional neural networks (multi-scale CNNs) are used to perform pixel-wise classification, and the classification results are post-processed by averaging within superpixels and smoothing by conditional random fields (CRFs). The performance of the bridge component extraction is tested in terms of accuracy and consistency.
Vision-based Automated Bridge Component Recognition Integrated With High-level Scene Understanding
May 15, 2018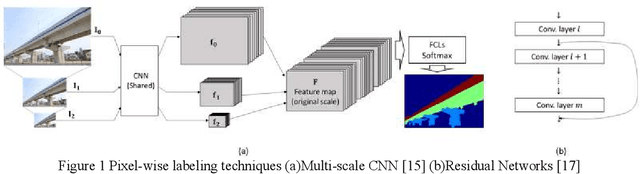
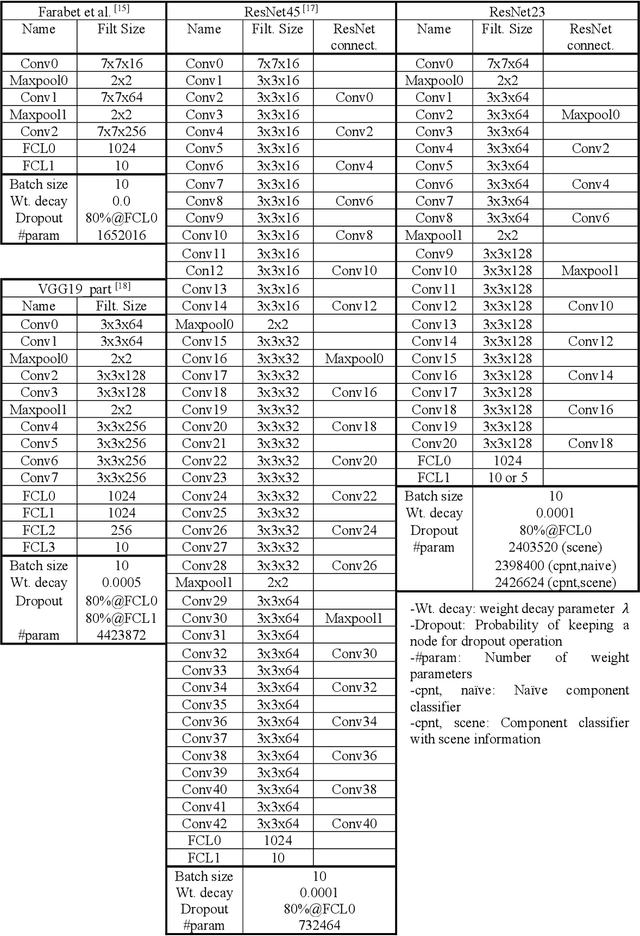
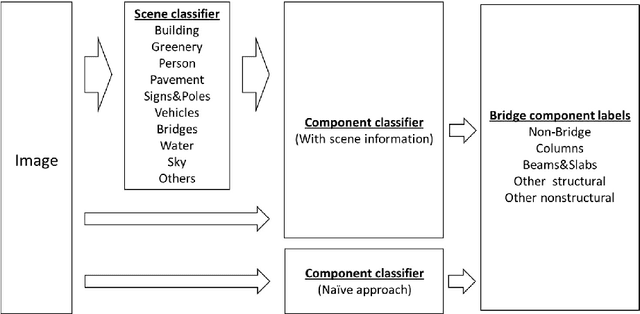
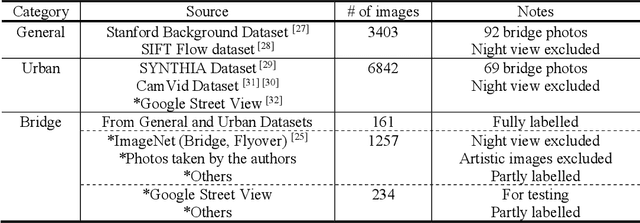
Image data has a great potential of helping conventional visual inspections of civil engineering structures due to the ease of data acquisition and the advantages in capturing visual information. A variety of techniques have been proposed to detect damages, such as cracks and spalling on a close-up image of a single component (columns and road surfaces etc.). However, these techniques commonly suffer from severe false-positives especially when the image includes multiple components of different structures. To reduce the false-positives and extract reliable information about the structures' conditions, detection and localization of critical structural components are important first steps preceding the damage assessment. This study aims at recognizing bridge structural and non-structural components from images of urban scenes. During the bridge component recognition, every image pixel is classified into one of the five classes (non-bridge, columns, beams and slabs, other structural, other nonstructural) by multi-scale convolutional neural networks (multi-scale CNNs). To reduce false-positives and get consistent labels, the component classifications are integrated with scene understanding by an additional classifier with 10 higher-level scene classes (building, greenery, person, pavement, signs and poles, vehicles, bridges, water, sky, and others). The bridge component recognition integrated with the scene understanding is compared with the naive approach without scene classification in terms of accuracy, false-positives and consistencies to demonstrate the effectiveness of the integrated approach.
Vision-based Structural Inspection using Multiscale Deep Convolutional Neural Networks
May 02, 2018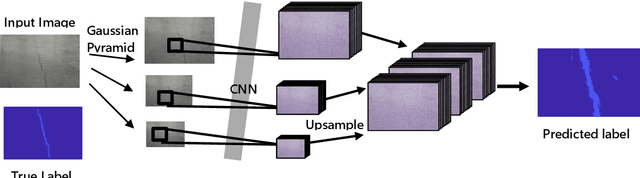
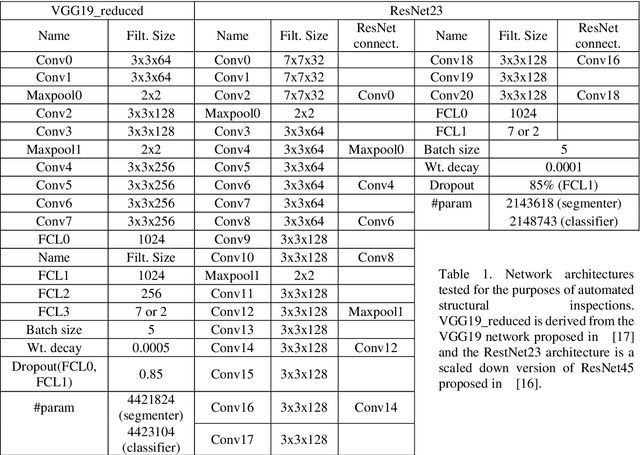
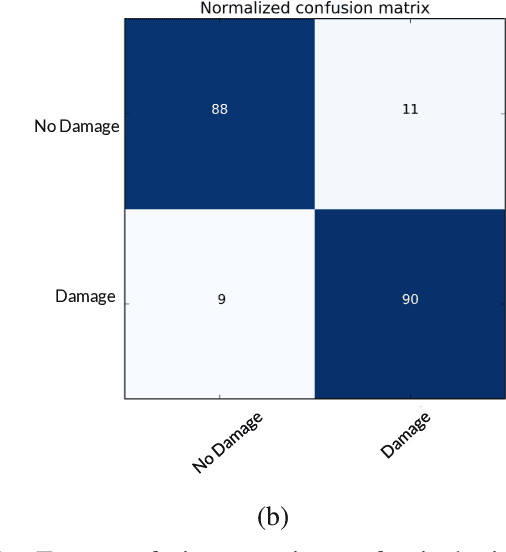

Current methods of practice for inspection of civil infrastructure typically involve visual assessments conducted manually by trained inspectors. For post-earthquake structural inspections, the number of structures to be inspected often far exceeds the capability of the available inspectors. The labor intensive and time consuming natures of manual inspection have engendered research into development of algorithms for automated damage identification using computer vision techniques. In this paper, a novel damage localization and classification technique based on a state of the art computer vision algorithm is presented to address several key limitations of current computer vision techniques. The proposed algorithm carries out a pixel-wise classification of each image at multiple scales using a deep convolutional neural network and can recognize 6 different types of damage. The resulting output is a segmented image where the portion of the image representing damage is outlined and classified as one of the trained damage categories. The proposed method is evaluated in terms of pixel accuracy and the application of the method to real world images is shown.