 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROBE-GK: Predictive Robust Estimation using Generalized Kernels
Aug 02, 2017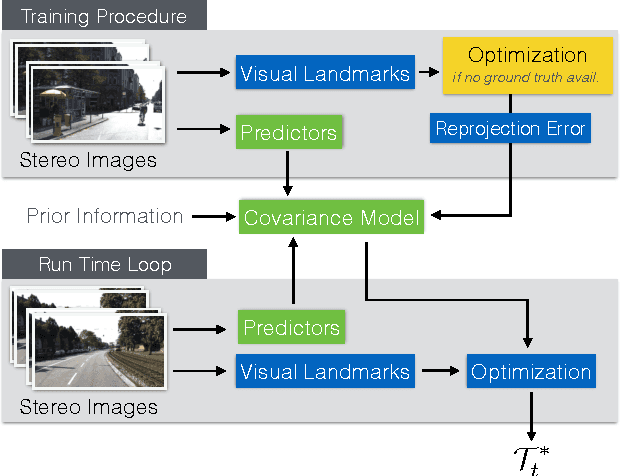
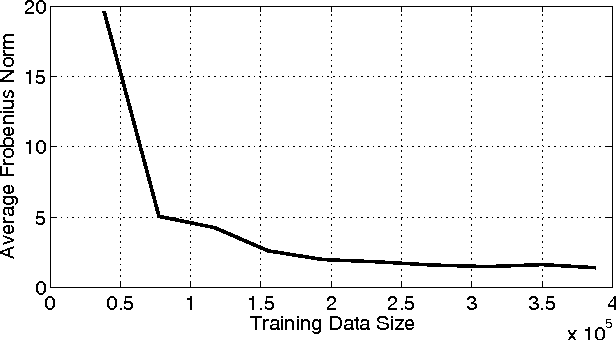
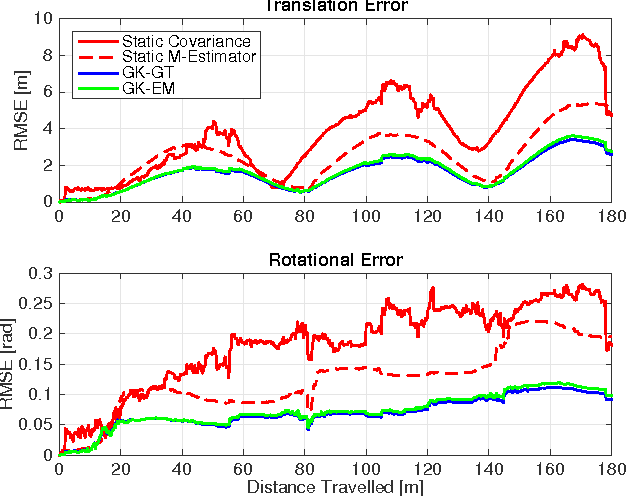

Many algorithms in computer vision and robotics make strong assumptions about uncertainty, and rely on the validity of these assumptions to produce accurate and consistent state estimates. In practice, dynamic environments may degrade sensor performance in predictable ways that cannot be captured with static uncertainty parameters. In this paper, we employ fast nonparametric Bayesian inference techniques to more accurately model sensor uncertainty. By setting a prior on observation uncertainty, we derive a predictive robust estimator, and show how our model can be learned from sample images, both with and without knowledge of the motion used to generate the data. We validate our approach through Monte Carlo simulations, and report significant improvements in localization accuracy relative to a fixed noise model in several settings, including on synthetic data, the KITTI dataset, and our own experimental platform.
PROBE: Predictive Robust Estimation for Visual-Inertial Navigation
Aug 02, 2017
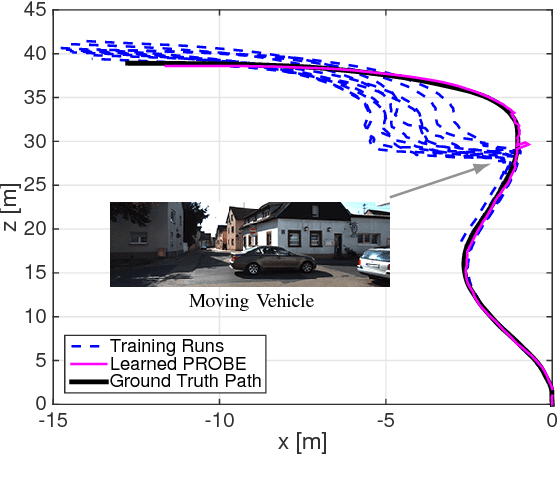
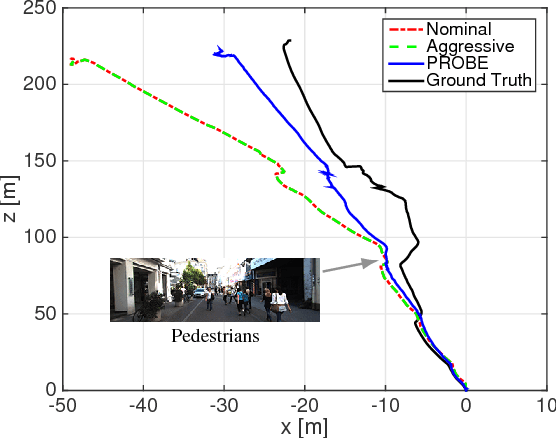
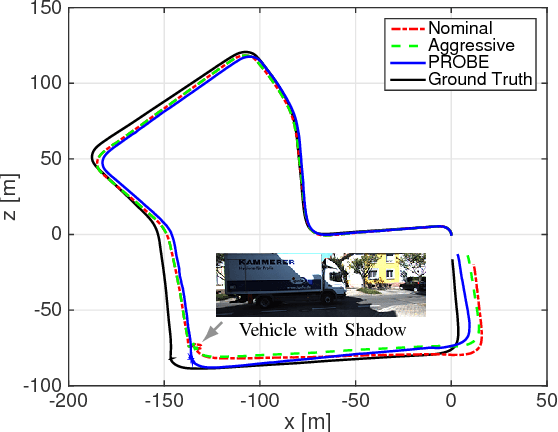
Navigation in unknown, chaotic environments continues to present a significant challenge for the robotics community. Lighting changes, self-similar textures, motion blur, and moving objects are all considerable stumbling blocks for state-of-the-art vision-based navigation algorithms. In this paper we present a novel technique for improving localization accuracy within a visual-inertial navigation system (VINS). We make use of training data to learn a model for the quality of visual features with respect to localization error in a given environment. This model maps each visual observation from a predefined prediction space of visual-inertial predictors onto a scalar weight, which is then used to scale the observation covariance matrix. In this way, our model can adjust the influence of each observation according to its quality. We discuss our choice of predictors and report substantial reductions in localization error on 4 km of data from the KITTI dataset, as well as on experimental datasets consisting of 700 m of indoor and outdoor driving on a small ground rover equipped with a Skybotix VI-Sensor.
Reducing Drift in Visual Odometry by Inferring Sun Direction Using a Bayesian Convolutional Neural Network
Jul 28, 2017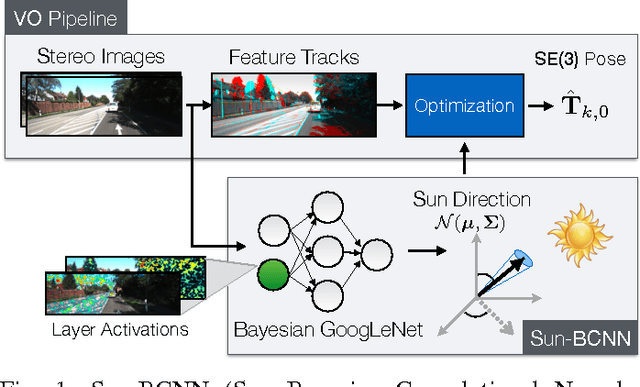

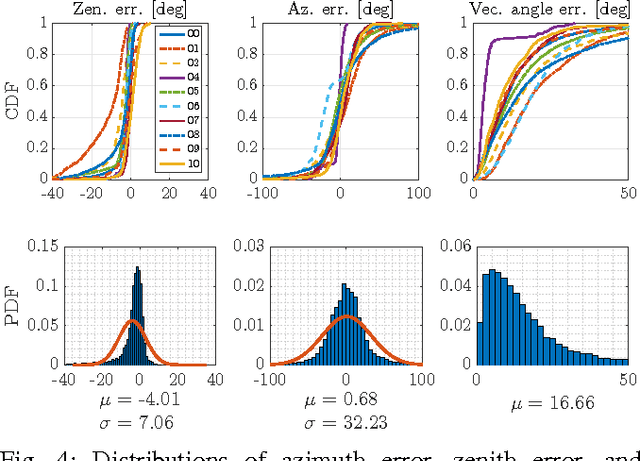
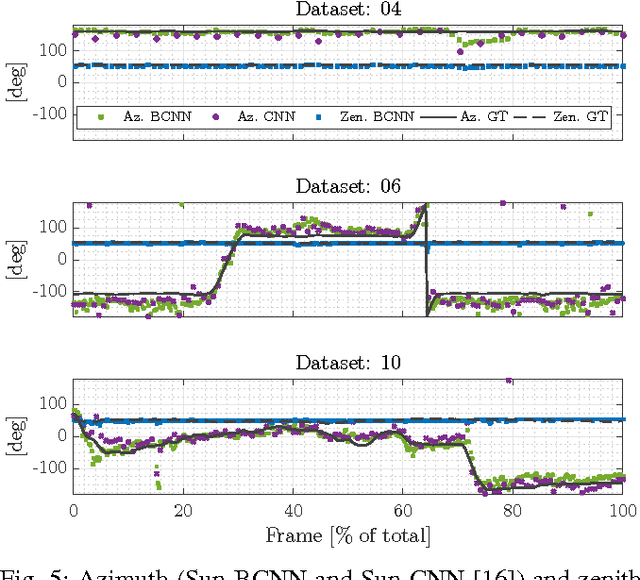
We present a method to incorporate global orientation information from the sun into a visual odometry pipeline using only the existing image stream, where the sun is typically not visible. We leverage recent advances in Bayesian Convolutional Neural Networks to train and implement a sun detection model that infers a three-dimensional sun direction vector from a single RGB image. Crucially, our method also computes a principled uncertainty associated with each prediction, using a Monte Carlo dropout scheme. We incorporate this uncertainty into a sliding window stereo visual odometry pipeline where accurate uncertainty estimates are critical for optimal data fusion. Our Bayesian sun detection model achieves a median error of approximately 12 degrees on the KITTI odometry benchmark training set, and yields improvements of up to 42% in translational ARMSE and 32% in rotational ARMSE compared to standard VO. An open source implementation of our Bayesian CNN sun estimator (Sun-BCNN) using Caffe is available at https://github. com/utiasSTARS/sun-bcnn-vo
Improving the Accuracy of Stereo Visual Odometry Using Visual Illumination Estimation
Jul 27, 2017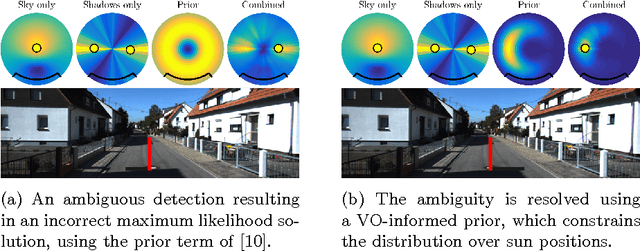
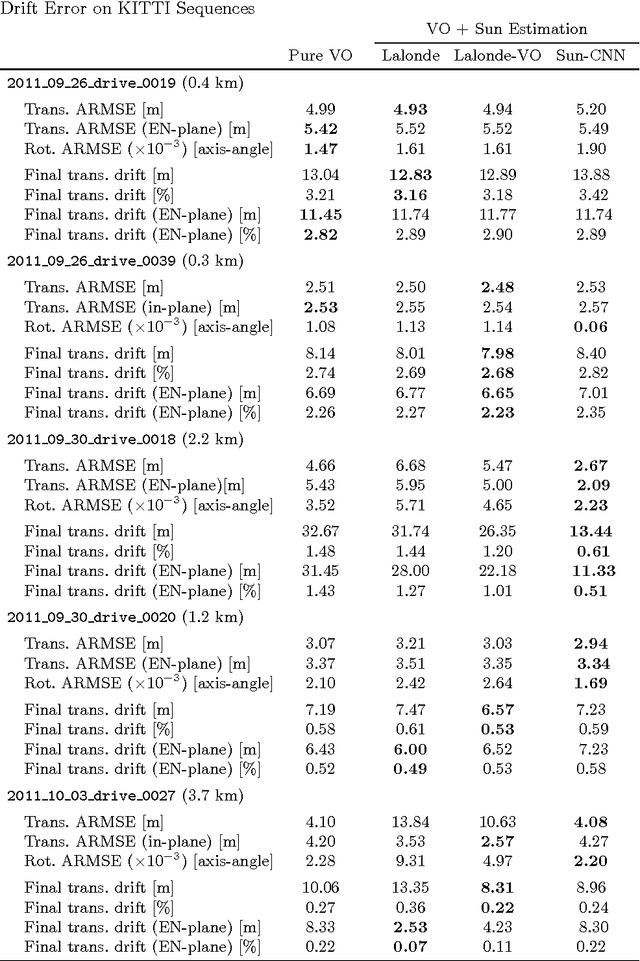
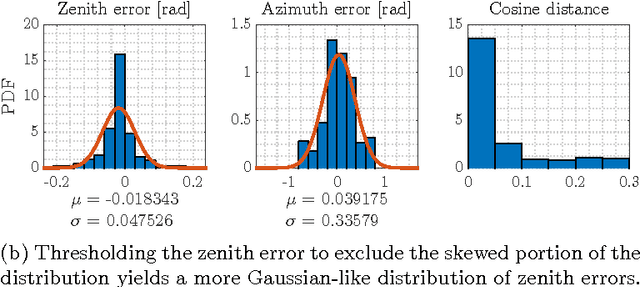

In the absence of reliable and accurate GPS, visual odometry (VO) has emerged as an effective means of estimating the egomotion of robotic vehicles. Like any dead-reckoning technique, VO suffers from unbounded accumulation of drift error over time, but this accumulation can be limited by incorporating absolute orientation information from, for example, a sun sensor. In this paper, we leverage recent work on visual outdoor illumination estimation to show that estimation error in a stereo VO pipeline can be reduced by inferring the sun position from the same image stream used to compute VO, thereby gaining the benefits of sun sensing without requiring a dedicated sun sensor or the sun to be visible to the camera. We compare sun estimation methods based on hand-crafted visual cues and Convolutional Neural Networks (CNNs) and demonstrate our approach on a combined 7.8 km of urban driving from the popular KITTI dataset, achieving up to a 43% reduction in translational average root mean squared error (ARMSE) and a 59% reduction in final translational drift error compared to pure VO alone.