 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Deep Learning Models for Tabular Data
Jun 22, 2021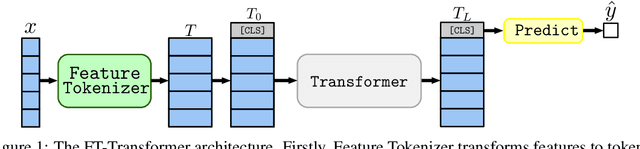
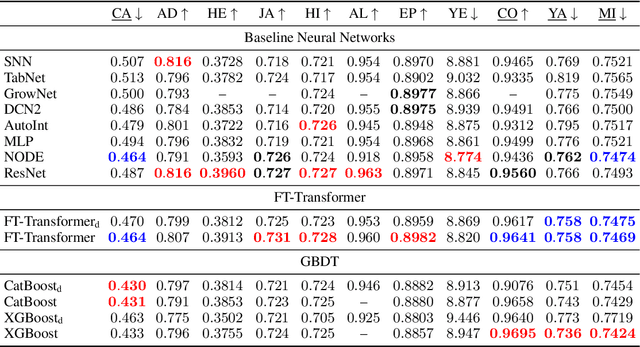
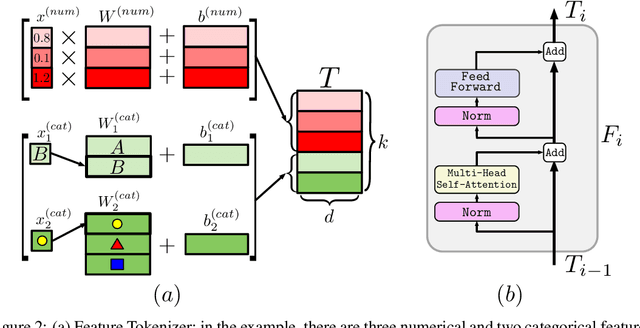
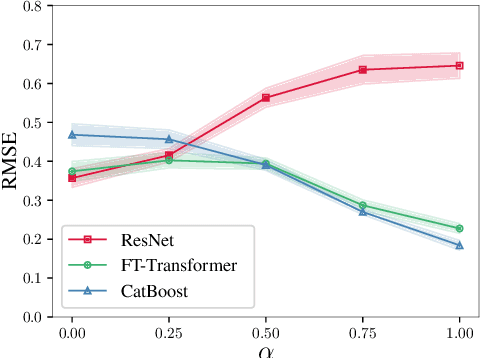
The necessity of deep learning for tabular data is still an unanswered question addressed by a large number of research efforts. The recent literature on tabular DL proposes several deep architectures reported to be superior to traditional "shallow" models like Gradient Boosted Decision Trees. However, since existing works often use different benchmarks and tuning protocols, it is unclear if the proposed models universally outperform GBDT. Moreover, the models are often not compared to each other, therefore, it is challenging to identify the best deep model for practitioners. In this work, we start from a thorough review of the main families of DL models recently developed for tabular data. We carefully tune and evaluate them on a wide range of datasets and reveal two significant findings. First, we show that the choice between GBDT and DL models highly depends on data and there is still no universally superior solution. Second, we demonstrate that a simple ResNet-like architecture is a surprisingly effective baseline, which outperforms most of the sophisticated models from the DL literature. Finally, we design a simple adaptation of the Transformer architecture for tabular data that becomes a new strong DL baseline and reduces the gap between GBDT and DL models on datasets where GBDT dominates.
Disentangled Representations from Non-Disentangled Models
Feb 11, 2021

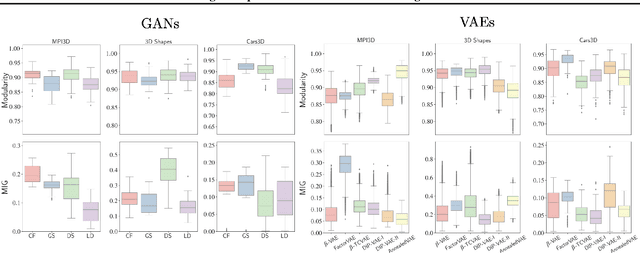

Constructing disentangled representations is known to be a difficult task, especially in the unsupervised scenario. The dominating paradigm of unsupervised disentanglement is currently to train a generative model that separates different factors of variation in its latent space. This separation is typically enforced by training with specific regularization terms in the model's objective function. These terms, however, introduce additional hyperparameters responsible for the trade-off between disentanglement and generation quality. While tuning these hyperparameters is crucial for proper disentanglement, it is often unclear how to tune them without external supervision. This paper investigates an alternative route to disentangled representations. Namely, we propose to extract such representations from the state-of-the-art generative models trained without disentangling terms in their objectives. This paradigm of post hoc disentanglement employs little or no hyperparameters when learning representations while achieving results on par with existing state-of-the-art, as shown by comparison in terms of established disentanglement metrics, fairness, and the abstract reasoning task. All our code and models are publicly available.
Functional Space Analysis of Local GAN Convergence
Feb 08, 2021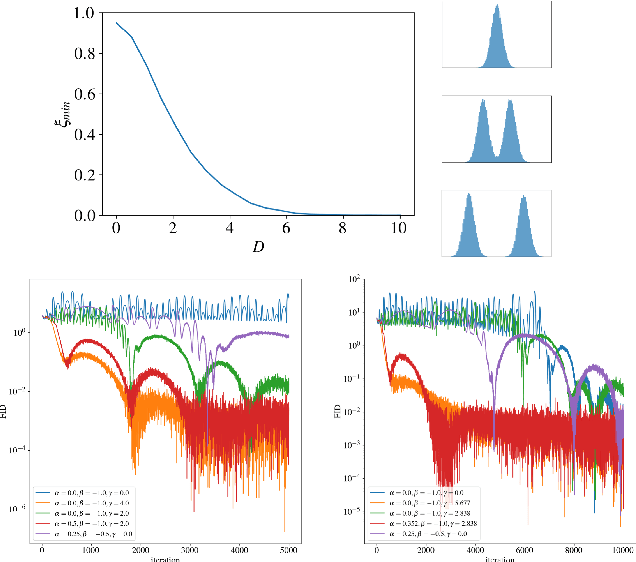


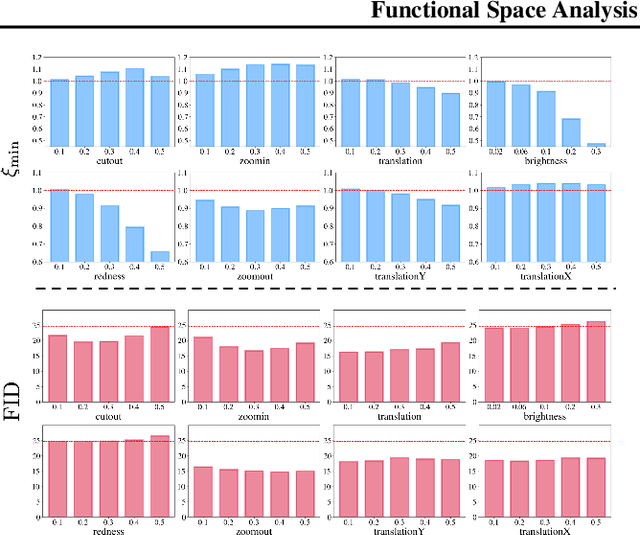
Recent work demonstrated the benefits of studying continuous-time dynamics governing the GAN training. However, this dynamics is analyzed in the model parameter space, which results in finite-dimensional dynamical systems. We propose a novel perspective where we study the local dynamics of adversarial training in the general functional space and show how it can be represented as a system of partial differential equations. Thus, the convergence properties can be inferred from the eigenvalues of the resulting differential operator. We show that these eigenvalues can be efficiently estimated from the target dataset before training. Our perspective reveals several insights on the practical tricks commonly used to stabilize GANs, such as gradient penalty, data augmentation, and advanced integration schemes. As an immediate practical benefit, we demonstrate how one can a priori select an optimal data augmentation strategy for a particular generation task.
Performance of Hyperbolic Geometry Models on Top-N Recommendation Tasks
Aug 15, 2020
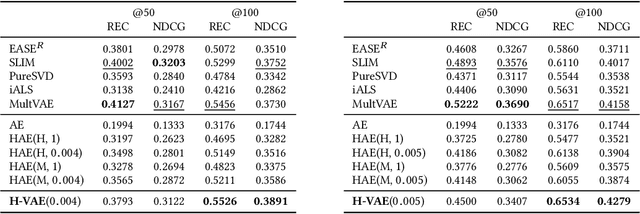
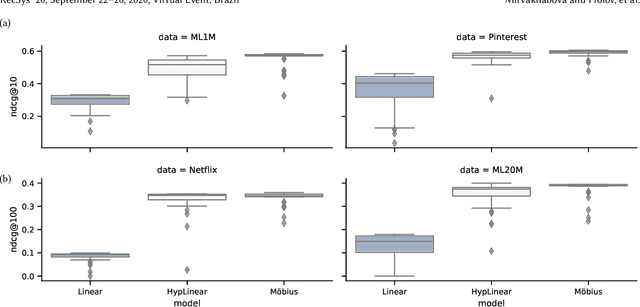
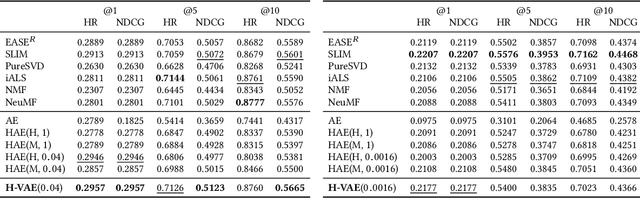
We introduce a simple autoencoder based on hyperbolic geometry for solving standard collaborative filtering problem. In contrast to many modern deep learning techniques, we build our solution using only a single hidden layer. Remarkably, even with such a minimalistic approach, we not only outperform the Euclidean counterpart but also achieve a competitive performance with respect to the current state-of-the-art. We additionally explore the effects of space curvature on the quality of hyperbolic models and propose an efficient data-driven method for estimating its optimal value.
Sample Efficient Ensemble Learning with Catalyst.RL
Apr 07, 2020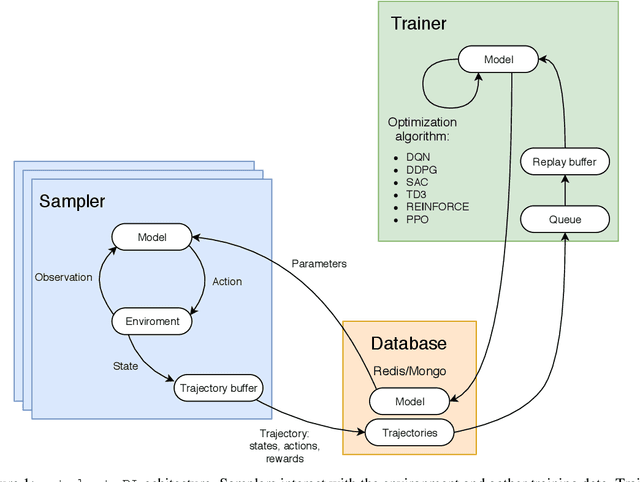

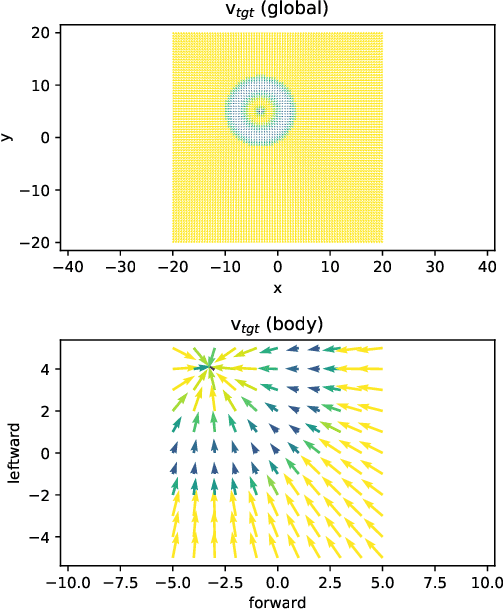
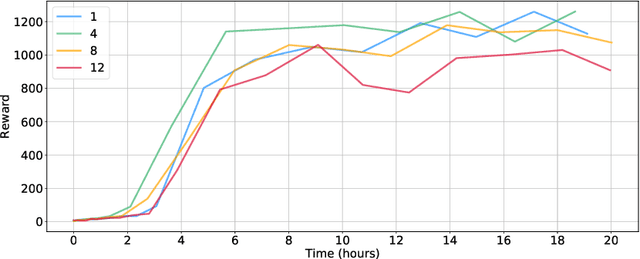
We present Catalyst.RL, an open-source PyTorch framework for reproducible and sample efficient reinforcement learning (RL) research. Main features of Catalyst.RL include large-scale asynchronous distributed training, efficient implementations of various RL algorithms and auxiliary tricks, such as n-step returns, value distributions, hyperbolic reinforcement learning, etc. To demonstrate the effectiveness of Catalyst.RL, we applied it to a physics-based reinforcement learning challenge "NeurIPS 2019: Learn to Move -- Walk Around" with the objective to build a locomotion controller for a human musculoskeletal model. The environment is computationally expensive, has a high-dimensional continuous action space and is stochastic. Our team took the 2nd place, capitalizing on the ability of Catalyst.RL to train high-quality and sample-efficient RL agents in only a few hours of training time. The implementation along with experiments is open-sourced so results can be reproduced and novel ideas tried out.
Universality Theorems for Generative Models
May 27, 2019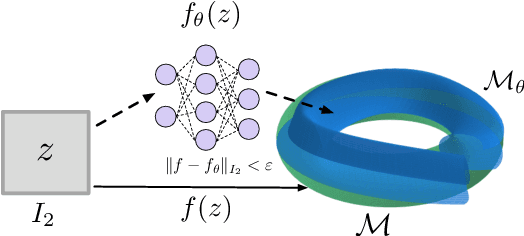
Despite the fact that generative models are extremely successful in practice, the theory underlying this phenomenon is only starting to catch up with practice. In this work we address the question of the universality of generative models: is it true that neural networks can approximate any data manifold arbitrarily well? We provide a positive answer to this question and show that under mild assumptions on the activation function one can always find a feedforward neural network that maps the latent space onto a set located within the specified Hausdorff distance from the desired data manifold. We also prove similar theorems for the case of multiclass generative models and cycle generative models, trained to map samples from one manifold to another and vice versa.
Hyperbolic Image Embeddings
Apr 03, 2019
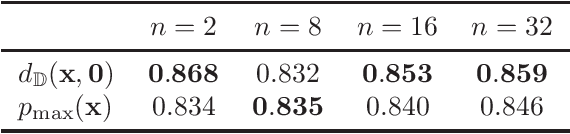
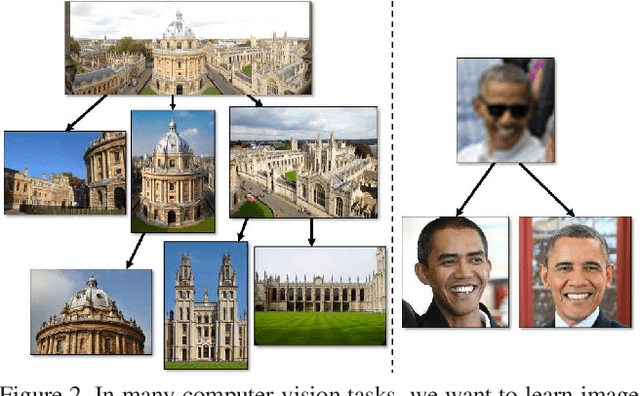
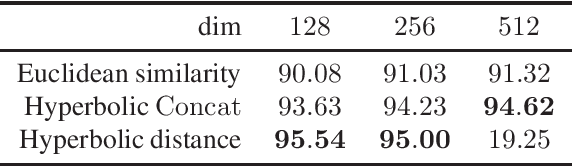
Computer vision tasks such as image classification, image retrieval and few-shot learning are currently dominated by Euclidean and spherical embeddings, so that the final decisions about class belongings or the degree of similarity are made using linear hyperplanes, Euclidean distances, or spherical geodesic distances (cosine similarity). In this work, we demonstrate that in many practical scenarios hyperbolic embeddings provide a better alternative.
Generalized Tensor Models for Recurrent Neural Networks
Jan 30, 2019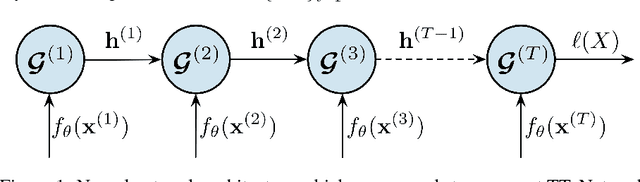

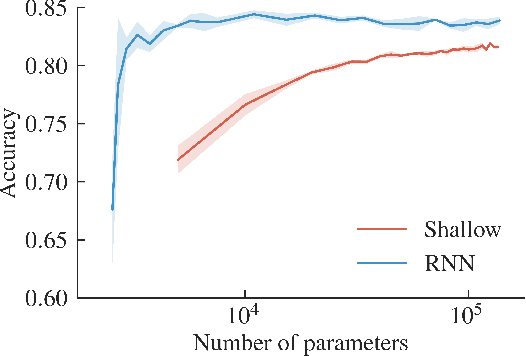
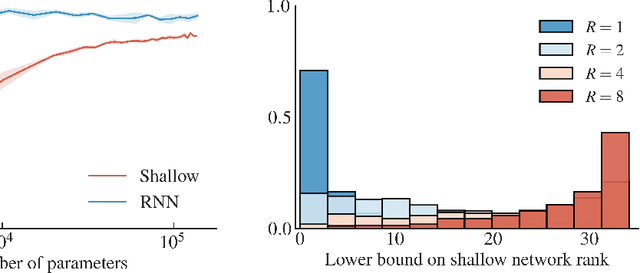
Recurrent Neural Networks (RNNs) are very successful at solving challenging problems with sequential data. However, this observed efficiency is not yet entirely explained by theory. It is known that a certain class of multiplicative RNNs enjoys the property of depth efficiency --- a shallow network of exponentially large width is necessary to realize the same score function as computed by such an RNN. Such networks, however, are not very often applied to real life tasks. In this work, we attempt to reduce the gap between theory and practice by extending the theoretical analysis to RNNs which employ various nonlinearities, such as Rectified Linear Unit (ReLU), and show that they also benefit from properties of universality and depth efficiency. Our theoretical results are verified by a series of extensive computational experiments.
Tensorized Embedding Layers for Efficient Model Compression
Jan 30, 2019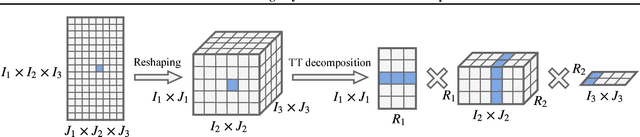

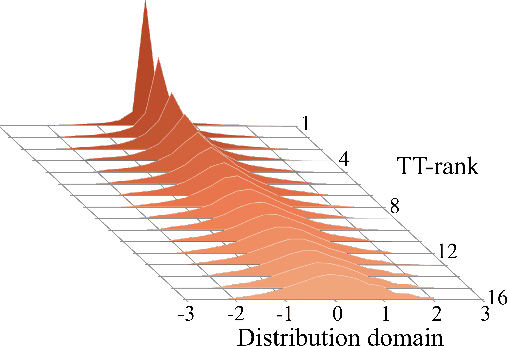
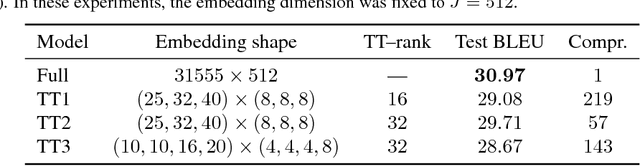
The embedding layers transforming input words into real vectors are the key components of deep neural networks used in natural language processing. However, when the vocabulary is large (e.g., 800k unique words in the One-Billion-Word dataset), the corresponding weight matrices can be enormous, which precludes their deployment in a limited resource setting. We introduce a novel way of parametrizing embedding layers based on the Tensor Train (TT) decomposition, which allows compressing the model significantly at the cost of a negligible drop or even a slight gain in performance. Importantly, our method does not take the pre-trained model and compress its weights but rather supplants the standard embedding layers with their TT-based counterparts. The resulting model is then trained end-to-end, however, it can capitalize on larger batches due to the reduced memory requirements. We evaluate our method on a wide range of benchmarks in sentiment analysis, neural machine translation, and language modeling, and analyze the trade-off between performance and compression ratios for a wide range of architectures, from MLPs to LSTMs and Transformers.
Geometry Score: A Method For Comparing Generative Adversarial Networks
Jun 09, 2018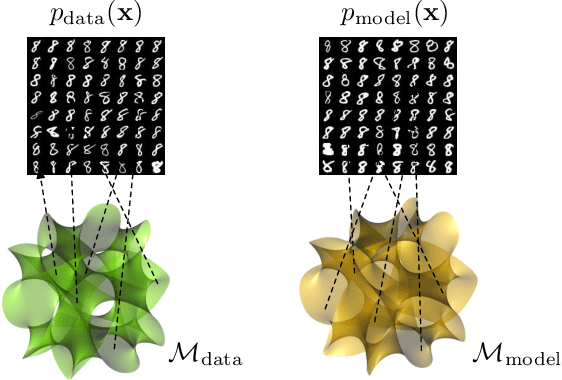

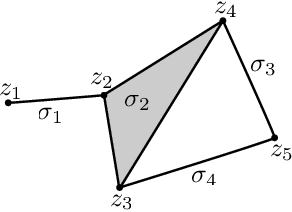
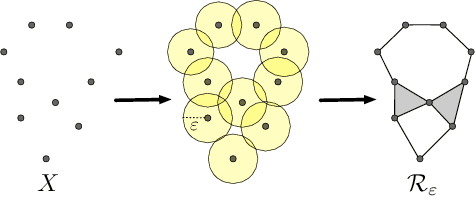
One of the biggest challenges in the research of generative adversarial networks (GANs) is assessing the quality of generated samples and detecting various levels of mode collapse. In this work, we construct a novel measure of performance of a GAN by comparing geometrical properties of the underlying data manifold and the generated one, which provides both qualitative and quantitative means for evaluation. Our algorithm can be applied to datasets of an arbitrary nature and is not limited to visual data. We test the obtained metric on various real-life models and datasets and demonstrate that our method provides new insights into properties of GANs.