 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-agent Epistemic Planning: Teaching Planners About Nested Belief
Oct 06, 2021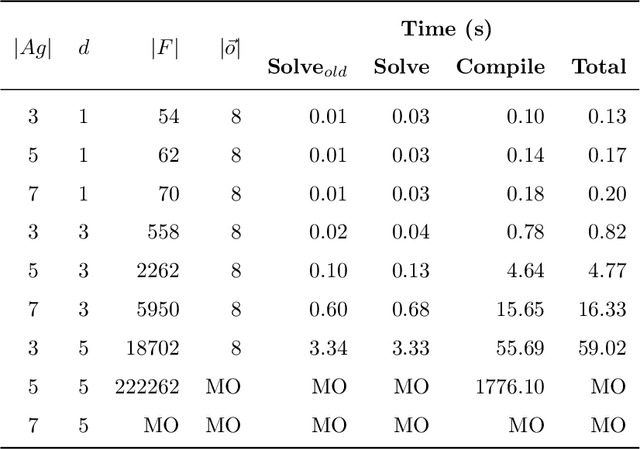
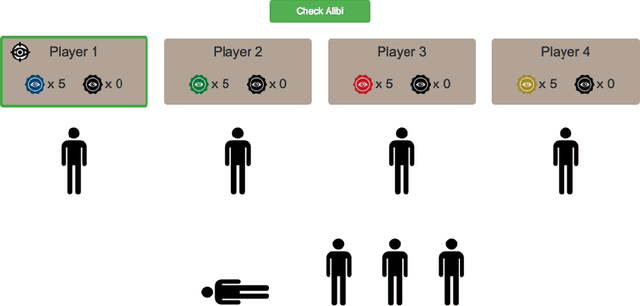
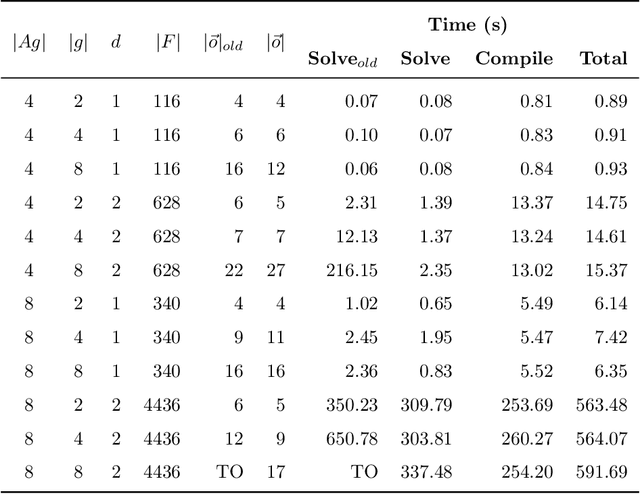
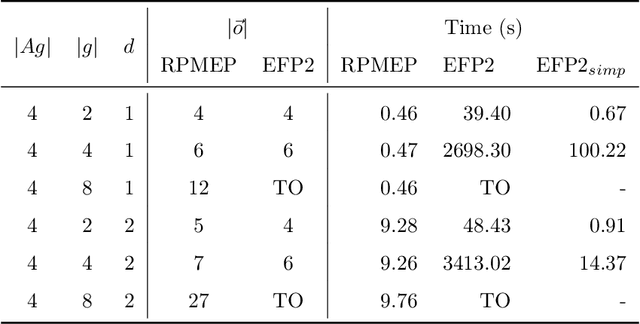
Many AI applications involve the interaction of multiple autonomous agents, requiring those agents to reason about their own beliefs, as well as those of other agents. However, planning involving nested beliefs is known to be computationally challenging. In this work, we address the task of synthesizing plans that necessitate reasoning about the beliefs of other agents. We plan from the perspective of a single agent with the potential for goals and actions that involve nested beliefs, non-homogeneous agents, co-present observations, and the ability for one agent to reason as if it were another. We formally characterize our notion of planning with nested belief, and subsequently demonstrate how to automatically convert such problems into problems that appeal to classical planning technology for solving efficiently. Our approach represents an important step towards applying the well-established field of automated planning to the challenging task of planning involving nested beliefs of multiple agents.
Learning Implicitly with Noisy Data in Linear Arithmetic
Oct 23, 2020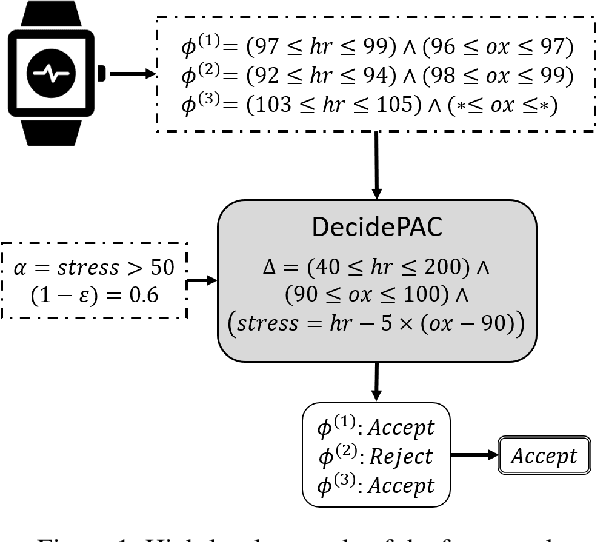
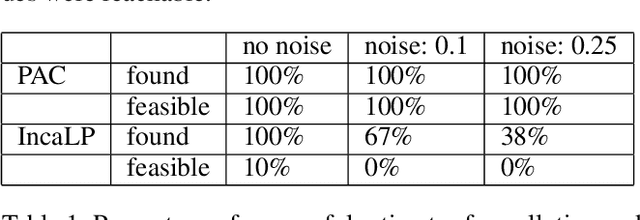
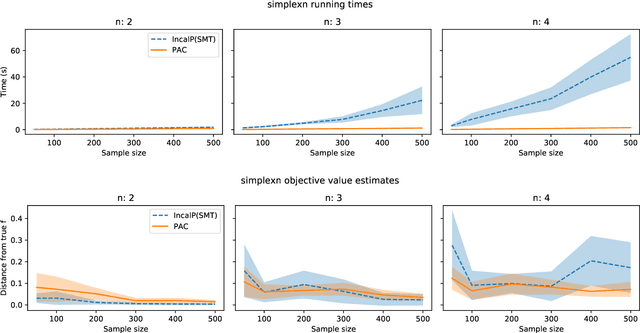
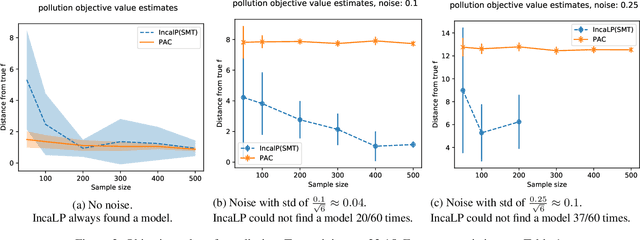
Robustly learning in expressive languages with real-world data continues to be a challenging task. Numerous conventional methods appeal to heuristics without any assurances of robustness. While PAC-Semantics offers strong guarantees, learning explicit representations is not tractable even in a propositional setting. However, recent work on so-called "implicit" learning has shown tremendous promise in terms of obtaining polynomial-time results for fragments of first-order logic. In this work, we extend implicit learning in PAC-Semantics to handle noisy data in the form of intervals and threshold uncertainty in the language of linear arithmetic. We prove that our extended framework keeps the existing polynomial-time complexity guarantees. Furthermore, we provide the first empirical investigation of this hitherto purely theoretical framework. Using benchmark problems, we show that our implicit approach to learning optimal linear programming objective constraints significantly outperforms an explicit approach in practice.
Principles and Practice of Explainable Machine Learning
Sep 18, 2020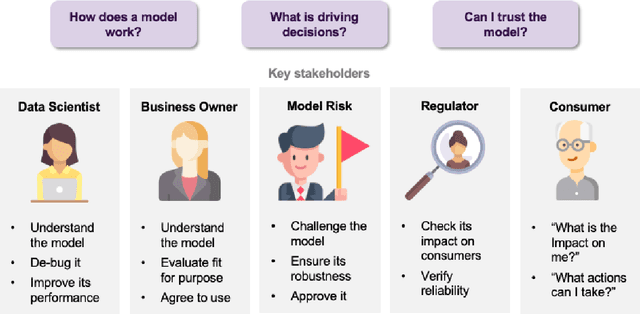
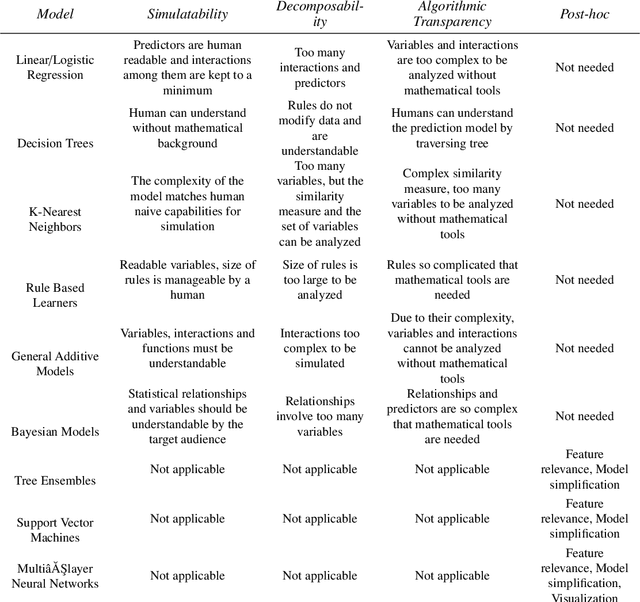
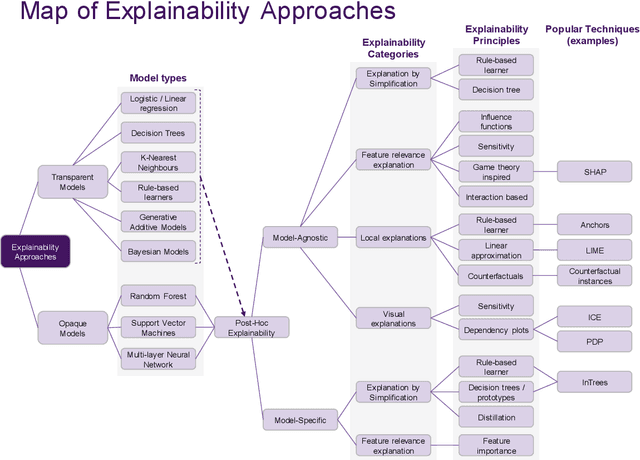
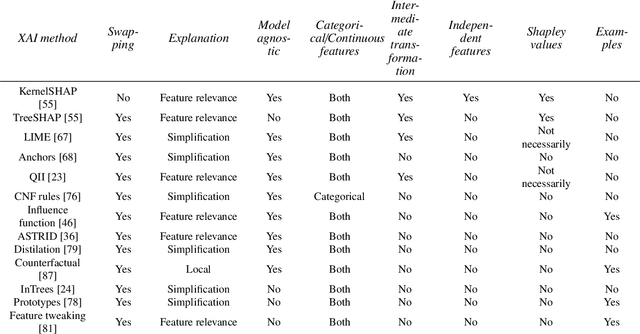
Artificial intelligence (AI) provides many opportunities to improve private and public life. Discovering patterns and structures in large troves of data in an automated manner is a core component of data science, and currently drives applications in diverse areas such as computational biology, law and finance. However, such a highly positive impact is coupled with significant challenges: how do we understand the decisions suggested by these systems in order that we can trust them? In this report, we focus specifically on data-driven methods -- machine learning (ML) and pattern recognition models in particular -- so as to survey and distill the results and observations from the literature. The purpose of this report can be especially appreciated by noting that ML models are increasingly deployed in a wide range of businesses. However, with the increasing prevalence and complexity of methods, business stakeholders in the very least have a growing number of concerns about the drawbacks of models, data-specific biases, and so on. Analogously, data science practitioners are often not aware about approaches emerging from the academic literature, or may struggle to appreciate the differences between different methods, so end up using industry standards such as SHAP. Here, we have undertaken a survey to help industry practitioners (but also data scientists more broadly) understand the field of explainable machine learning better and apply the right tools. Our latter sections build a narrative around a putative data scientist, and discuss how she might go about explaining her models by asking the right questions.
Logic, Probability and Action: A Situation Calculus Perspective
Jun 17, 2020The unification of logic and probability is a long-standing concern in AI, and more generally, in the philosophy of science. In essence, logic provides an easy way to specify properties that must hold in every possible world, and probability allows us to further quantify the weight and ratio of the worlds that must satisfy a property. To that end, numerous developments have been undertaken, culminating in proposals such as probabilistic relational models. While this progress has been notable, a general-purpose first-order knowledge representation language to reason about probabilities and dynamics, including in continuous settings, is still to emerge. In this paper, we survey recent results pertaining to the integration of logic, probability and actions in the situation calculus, which is arguably one of the oldest and most well-known formalisms. We then explore reduction theorems and programming interfaces for the language. These results are motivated in the context of cognitive robotics (as envisioned by Reiter and his colleagues) for the sake of concreteness. Overall, the advantage of proving results for such a general language is that it becomes possible to adapt them to any special-purpose fragment, including but not limited to popular probabilistic relational models.
Symbolic Logic meets Machine Learning: A Brief Survey in Infinite Domains
Jun 15, 2020The tension between deduction and induction is perhaps the most fundamental issue in areas such as philosophy, cognition and artificial intelligence (AI). The deduction camp concerns itself with questions about the expressiveness of formal languages for capturing knowledge about the world, together with proof systems for reasoning from such knowledge bases. The learning camp attempts to generalize from examples about partial descriptions about the world. In AI, historically, these camps have loosely divided the development of the field, but advances in cross-over areas such as statistical relational learning, neuro-symbolic systems, and high-level control have illustrated that the dichotomy is not very constructive, and perhaps even ill-formed. In this article, we survey work that provides further evidence for the connections between logic and learning. Our narrative is structured in terms of three strands: logic versus learning, machine learning for logic, and logic for machine learning, but naturally, there is considerable overlap. We place an emphasis on the following "sore" point: there is a common misconception that logic is for discrete properties, whereas probability theory and machine learning, more generally, is for continuous properties. We report on results that challenge this view on the limitations of logic, and expose the role that logic can play for learning in infinite domains.
Generating Random Logic Programs Using Constraint Programming
Jun 02, 2020


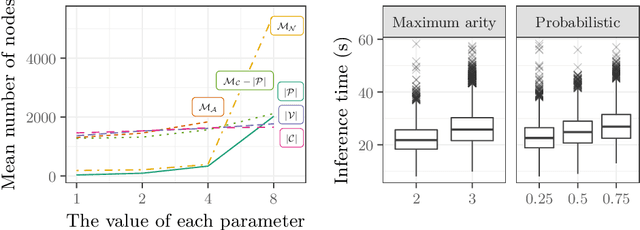
Testing algorithms across a wide range of problem instances is crucial to ensure the validity of any claim about one algorithm's superiority over another. However, when it comes to inference algorithms for probabilistic logic programs, experimental evaluations are limited to only a few programs. Existing methods to generate random logic programs are limited to propositional programs and often impose stringent syntactic restrictions. We present a novel approach to generating random logic programs and random probabilistic logic programs using constraint programming, introducing a new constraint to control the independence structure of the underlying probability distribution. We also provide a combinatorial argument for the correctness of the model, show how the model scales with parameter values, and use the model to compare probabilistic inference algorithms across a range of synthetic problems. Our model allows inference algorithm developers to evaluate and compare the algorithms across a wide range of instances, providing a detailed picture of their (comparative) strengths and weaknesses.
On Constraint Definability in Tractable Probabilistic Models
Jan 29, 2020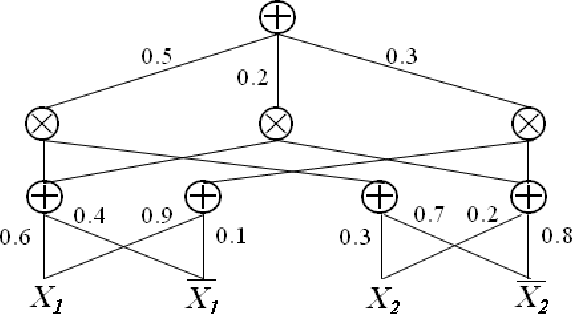
Incorporating constraints is a major concern in probabilistic machine learning. A wide variety of problems require predictions to be integrated with reasoning about constraints, from modelling routes on maps to approving loan predictions. In the former, we may require the prediction model to respect the presence of physical paths between the nodes on the map, and in the latter, we may require that the prediction model respect fairness constraints that ensure that outcomes are not subject to bias. Broadly speaking, constraints may be probabilistic, logical or causal, but the overarching challenge is to determine if and how a model can be learnt that handles all the declared constraints. To the best of our knowledge, this is largely an open problem. In this paper, we consider a mathematical inquiry on how the learning of tractable probabilistic models, such as sum-product networks, is possible while incorporating constraints.
Interventions and Counterfactuals in Tractable Probabilistic Models: Limitations of Contemporary Transformations
Jan 29, 2020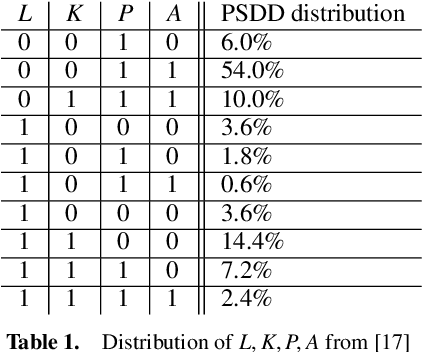
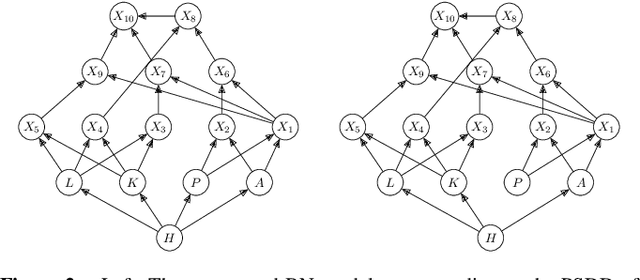
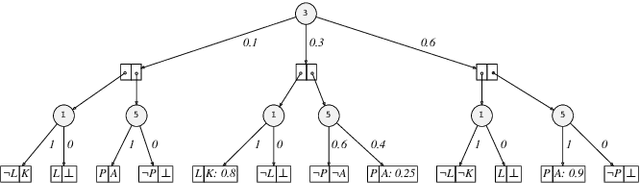
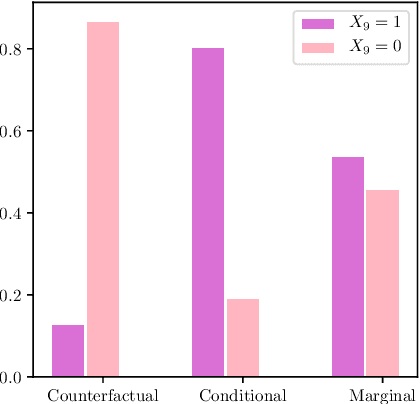
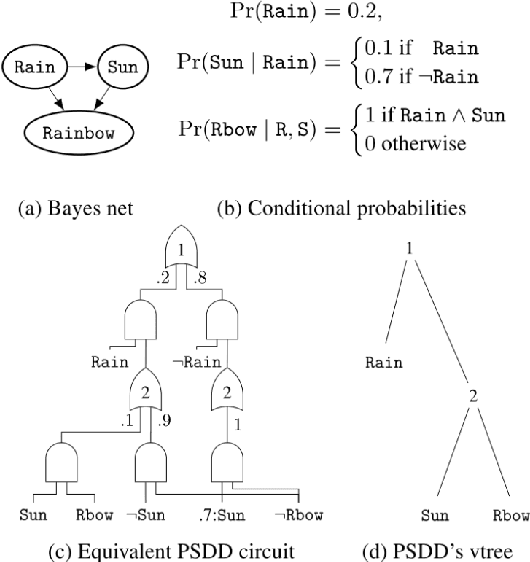
In recent years, there has been an increasing interest in studying causality-related properties in machine learning models generally, and in generative models in particular. While that is well motivated, it inherits the fundamental computational hardness of probabilistic inference, making exact reasoning intractable. Probabilistic tractable models have also recently emerged, which guarantee that conditional marginals can be computed in time linear in the size of the model, where the model is usually learned from data. Although initially limited to low tree-width models, recent tractable models such as sum product networks (SPNs) and probabilistic sentential decision diagrams (PSDDs) exploit efficient function representations and also capture high tree-width models. In this paper, we ask the following technical question: can we use the distributions represented or learned by these models to perform causal queries, such as reasoning about interventions and counterfactuals? By appealing to some existing ideas on transforming such models to Bayesian networks, we answer mostly in the negative. We show that when transforming SPNs to a causal graph interventional reasoning reduces to computing marginal distributions; in other words, only trivial causal reasoning is possible. For PSDDs the situation is only slightly better. We first provide an algorithm for constructing a causal graph from a PSDD, which introduces augmented variables. Intervening on the original variables, once again, reduces to marginal distributions, but when intervening on the augmented variables, a deterministic but nonetheless causal-semantics can be provided for PSDDs.
SMT + ILP
Jan 15, 2020Inductive logic programming (ILP) has been a deeply influential paradigm in AI, enjoying decades of research on its theory and implementations. As a natural descendent of the fields of logic programming and machine learning, it admits the incorporation of background knowledge, which can be very useful in domains where prior knowledge from experts is available and can lead to a more data-efficient learning regime. Be that as it may, the limitation to Horn clauses composed over Boolean variables is a very serious one. Many phenomena occurring in the real-world are best characterized using continuous entities, and more generally, mixtures of discrete and continuous entities. In this position paper, we motivate a reconsideration of inductive declarative programming by leveraging satisfiability modulo theory technology.
Logical Interpretations of Autoencoders
Nov 26, 2019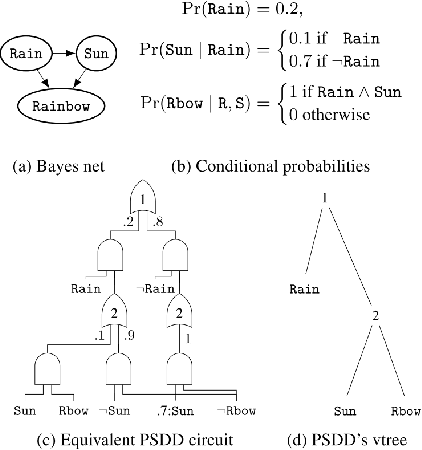
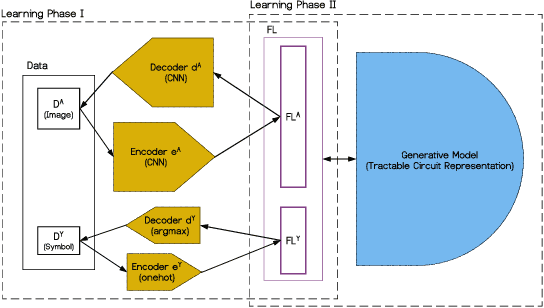
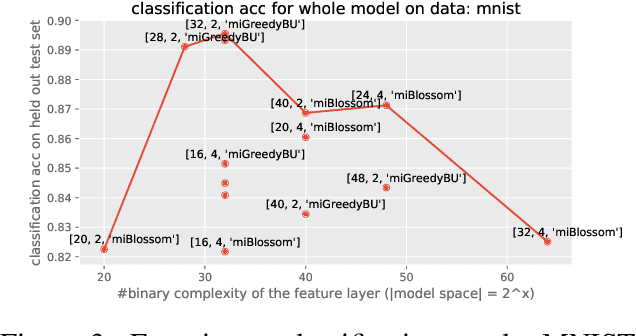

The unification of low-level perception and high-level reasoning is a long-standing problem in artificial intelligence, which has the potential to not only bring the areas of logic and learning closer together but also demonstrate how abstract concepts might emerge from sensory data. Precisely because deep learning methods dominate perception-based learning, including vision, speech, and linguistic grammar, there is fast-growing literature on how to integrate symbolic reasoning and deep learning. Broadly, efforts seem to fall into three camps: those focused on defining a logic whose formulas capture deep learning, ones that integrate symbolic constraints in deep learning, and others that allow neural computations and symbolic reasoning to co-exist separately, to enjoy the strengths of both worlds. In this paper, we identify another dimension to this inquiry: what do the hidden layers really capture, and how can we reason about that logically? In particular, we consider autoencoders that are widely used for dimensionality reduction and inject a symbolic generative framework onto the feature layer. This allows us, among other things, to generate example images for a class to get a sense of what was learned. Moreover, the modular structure of the proposed model makes it possible to learn relations over multiple images at a time, as well as handle noisy labels. Our empirical evaluations show the promise of this inquiry.