 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Instruction Tuning With Just a Pinch of Multilinguality
Jan 08, 2024As instruction-tuned large language models (LLMs) gain global adoption, their ability to follow instructions in multiple languages becomes increasingly crucial. One promising approach is cross-lingual transfer, where a model acquires specific functionality on some language by finetuning on another language. In this work, we investigate how multilinguality during instruction tuning of a multilingual LLM affects instruction-following across languages. We first show that many languages transfer some instruction-following capabilities to other languages from even monolingual tuning. Furthermore, we find that only 40 multilingual examples in an English tuning set substantially improve multilingual instruction-following, both in seen and unseen languages during tuning. In general, we observe that models tuned on multilingual mixtures exhibit comparable or superior performance in several languages compared to monolingually tuned models, despite training on 10x fewer examples in those languages. Finally, we find that increasing the number of languages in the instruction tuning set from 1 to only 2, 3, or 4 increases cross-lingual generalization. Our results suggest that building massively multilingual instruction-tuned models can be done with only a very small set of multilingual instruction-responses.
ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
May 23, 2023



We introduce ZeroSCROLLS, a zero-shot benchmark for natural language understanding over long texts, which contains only test sets, without training or development data. We adapt six tasks from the SCROLLS benchmark, and add four new datasets, including two novel information fusing tasks, such as aggregating the percentage of positive reviews. Using ZeroSCROLLS, we conduct a comprehensive evaluation of both open-source and closed large language models, finding that Claude outperforms ChatGPT, and that GPT-4 achieves the highest average score. However, there is still room for improvement on multiple open challenges in ZeroSCROLLS, such as aggregation tasks, where models struggle to pass the naive baseline. As the state of the art is a moving target, we invite researchers to evaluate their ideas on the live ZeroSCROLLS leaderboard
Causes and Cures for Interference in Multilingual Translation
Dec 14, 2022Multilingual machine translation models can benefit from synergy between different language pairs, but also suffer from interference. While there is a growing number of sophisticated methods that aim to eliminate interference, our understanding of interference as a phenomenon is still limited. This work identifies the main factors that contribute to interference in multilingual machine translation. Through systematic experimentation, we find that interference (or synergy) are primarily determined by model size, data size, and the proportion of each language pair within the total dataset. We observe that substantial interference occurs mainly when the model is very small with respect to the available training data, and that using standard transformer configurations with less than one billion parameters largely alleviates interference and promotes synergy. Moreover, we show that tuning the sampling temperature to control the proportion of each language pair in the data is key to balancing the amount of interference between low and high resource language pairs effectively, and can lead to superior performance overall.
Efficient Long-Text Understanding with Short-Text Models
Aug 01, 2022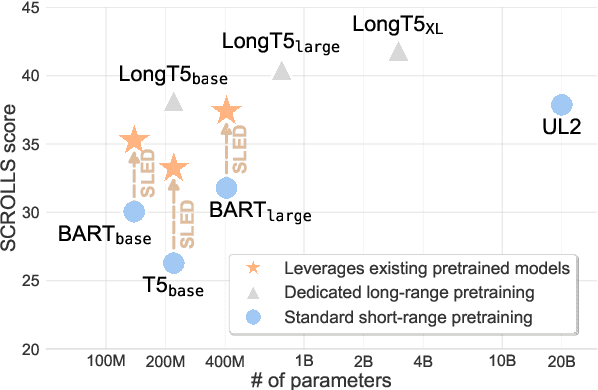
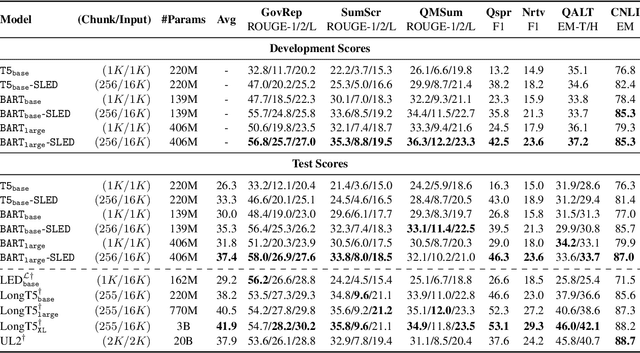
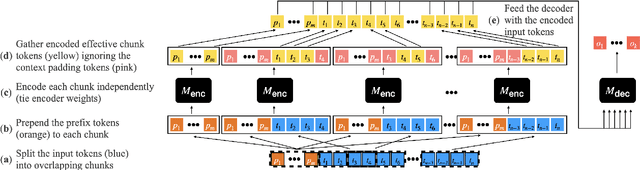
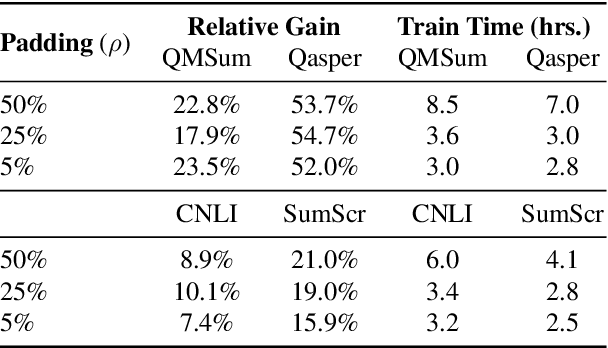
Transformer-based pretrained language models (LMs) are ubiquitous across natural language understanding, but cannot be applied to long sequences such as stories, scientific articles and long documents, due to their quadratic complexity. While a myriad of efficient transformer variants have been proposed, they are typically based on custom implementations that require expensive pretraining from scratch. In this work, we propose SLED: SLiding-Encoder and Decoder, a simple approach for processing long sequences that re-uses and leverages battle-tested short-text pretrained LMs. Specifically, we partition the input into overlapping chunks, encode each with a short-text LM encoder and use the pretrained decoder to fuse information across chunks (fusion-in-decoder). We illustrate through controlled experiments that SLED offers a viable strategy for long text understanding and evaluate our approach on SCROLLS, a benchmark with seven datasets across a wide range of language understanding tasks. We find that SLED is competitive with specialized models that are up to 50x larger and require a dedicated and expensive pretraining step.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Instruction Induction: From Few Examples to Natural Language Task Descriptions
May 22, 2022
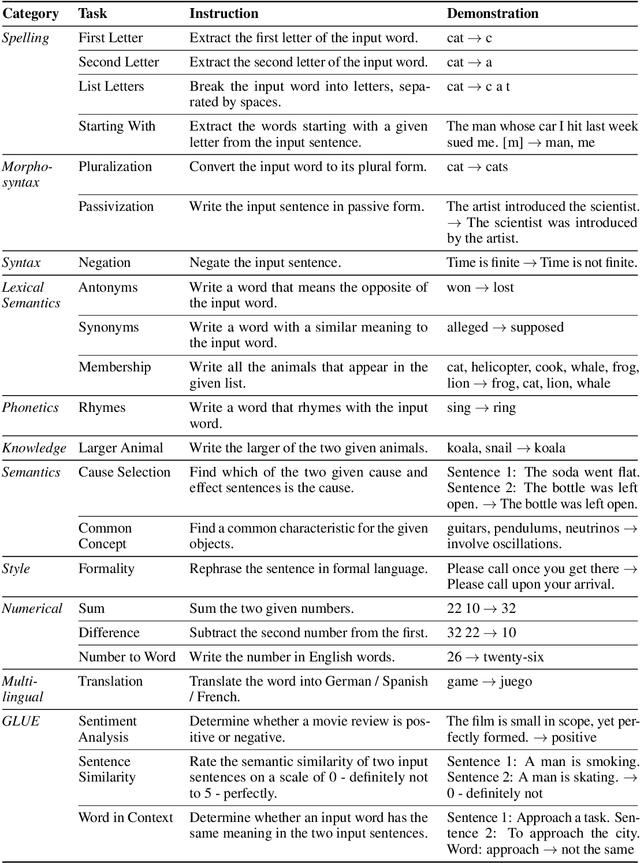
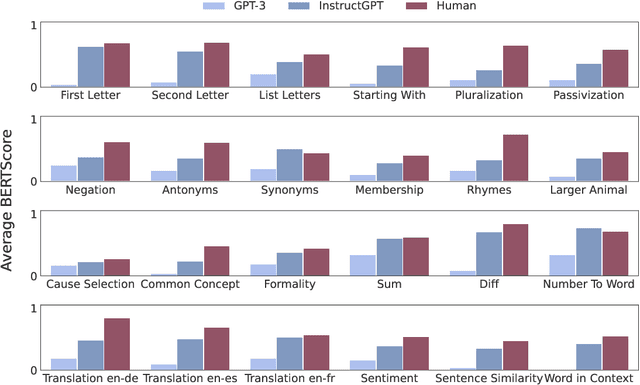
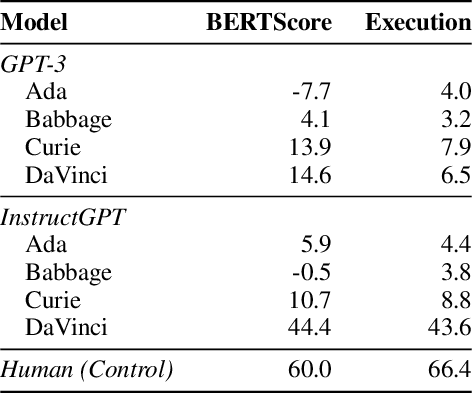
Large language models are able to perform a task by conditioning on a few input-output demonstrations - a paradigm known as in-context learning. We show that language models can explicitly infer an underlying task from a few demonstrations by prompting them to generate a natural language instruction that fits the examples. To explore this ability, we introduce the instruction induction challenge, compile a dataset consisting of 24 tasks, and define a novel evaluation metric based on executing the generated instruction. We discover that, to a large extent, the ability to generate instructions does indeed emerge when using a model that is both large enough and aligned to follow instructions; InstructGPT achieves 65.7% of human performance in our execution-based metric, while the original GPT-3 model reaches only 9.8% of human performance. This surprising result suggests that instruction induction might be a viable learning paradigm in and of itself, where instead of fitting a set of latent continuous parameters to the data, one searches for the best description in the natural language hypothesis space.
SCROLLS: Standardized CompaRison Over Long Language Sequences
Jan 10, 2022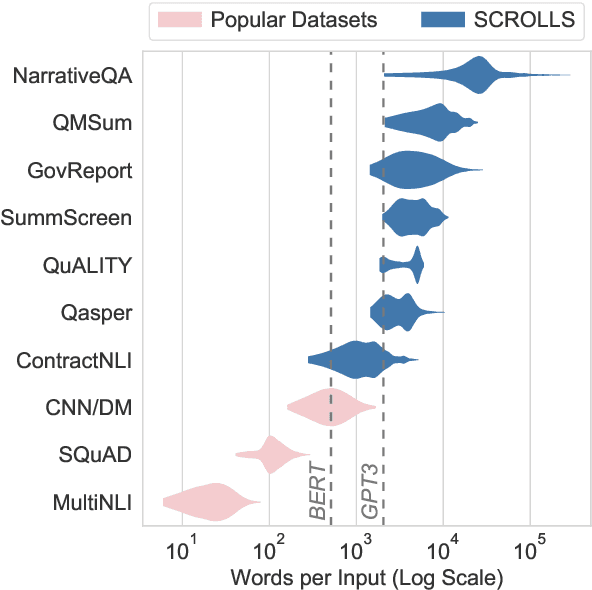
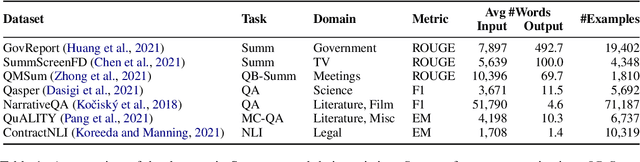

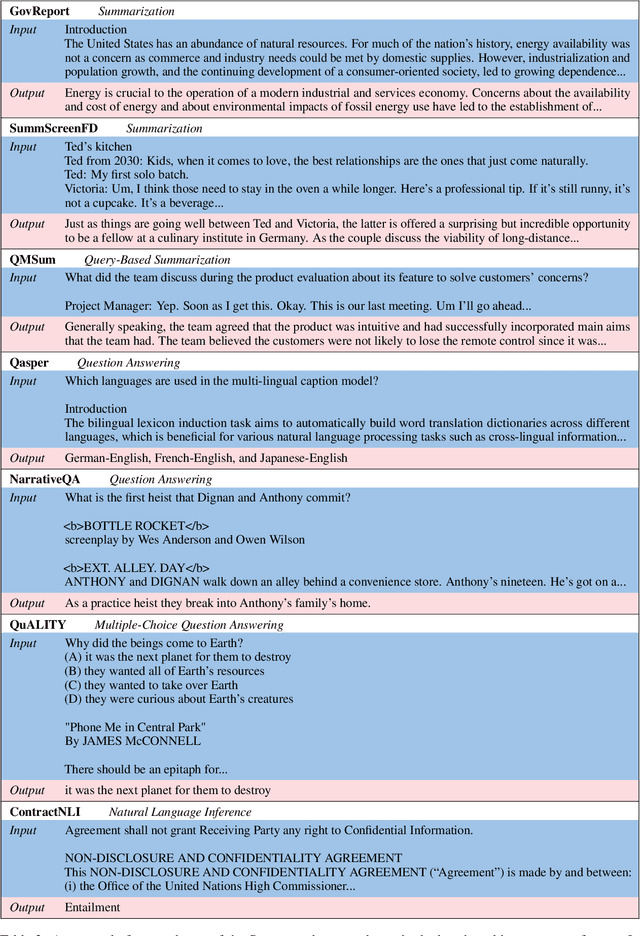
NLP benchmarks have largely focused on short texts, such as sentences and paragraphs, even though long texts comprise a considerable amount of natural language in the wild. We introduce SCROLLS, a suite of tasks that require reasoning over long texts. We examine existing long-text datasets, and handpick ones where the text is naturally long, while prioritizing tasks that involve synthesizing information across the input. SCROLLS contains summarization, question answering, and natural language inference tasks, covering multiple domains, including literature, science, business, and entertainment. Initial baselines, including Longformer Encoder-Decoder, indicate that there is ample room for improvement on SCROLLS. We make all datasets available in a unified text-to-text format and host a live leaderboard to facilitate research on model architecture and pretraining methods.
Single Independent Component Recovery and Applications
Oct 12, 2021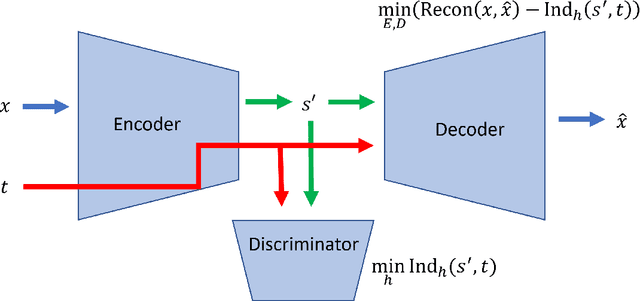
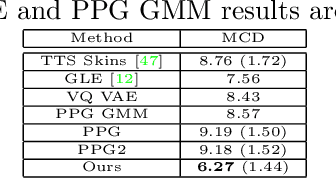
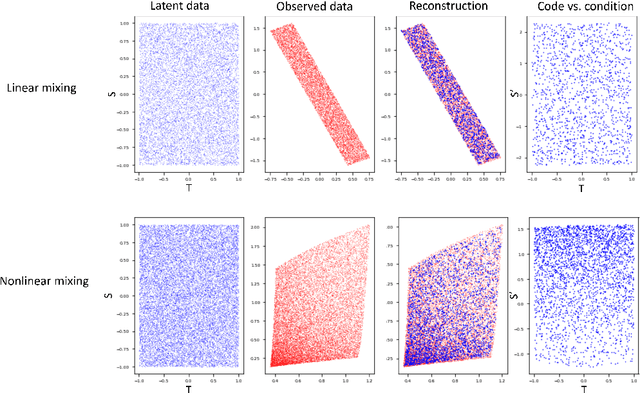
Latent variable discovery is a central problem in data analysis with a broad range of applications in applied science. In this work, we consider data given as an invertible mixture of two statistically independent components, and assume that one of the components is observed while the other is hidden. Our goal is to recover the hidden component. For this purpose, we propose an autoencoder equipped with a discriminator. Unlike the standard nonlinear ICA problem, which was shown to be non-identifiable, in the special case of ICA we consider here, we show that our approach can recover the component of interest up to entropy-preserving transformation. We demonstrate the performance of the proposed approach on several datasets, including image synthesis, voice cloning, and fetal ECG extraction.
Deep Unsupervised Feature Selection by Discarding Nuisance and Correlated Features
Oct 11, 2021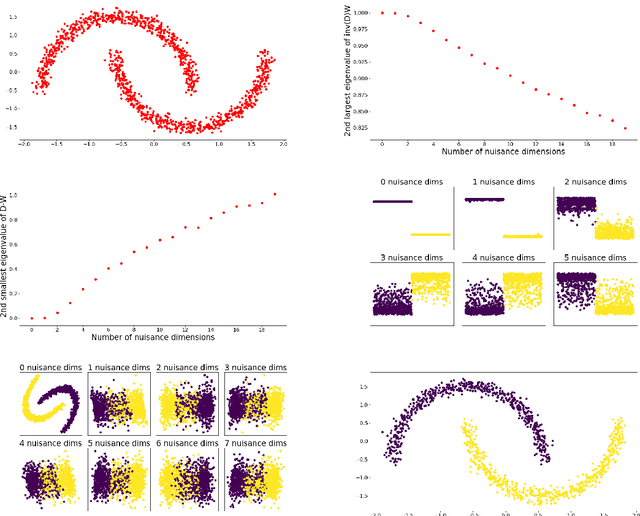
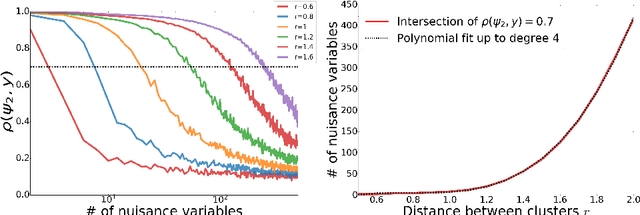
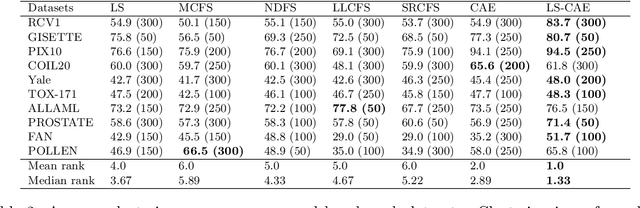
Modern datasets often contain large subsets of correlated features and nuisance features, which are not or loosely related to the main underlying structures of the data. Nuisance features can be identified using the Laplacian score criterion, which evaluates the importance of a given feature via its consistency with the Graph Laplacians' leading eigenvectors. We demonstrate that in the presence of large numbers of nuisance features, the Laplacian must be computed on the subset of selected features rather than on the complete feature set. To do this, we propose a fully differentiable approach for unsupervised feature selection, utilizing the Laplacian score criterion to avoid the selection of nuisance features. We employ an autoencoder architecture to cope with correlated features, trained to reconstruct the data from the subset of selected features. Building on the recently proposed concrete layer that allows controlling for the number of selected features via architectural design, simplifying the optimization process. Experimenting on several real-world datasets, we demonstrate that our proposed approach outperforms similar approaches designed to avoid only correlated or nuisance features, but not both. Several state-of-the-art clustering results are reported.
What Do You Get When You Cross Beam Search with Nucleus Sampling?
Jul 23, 2021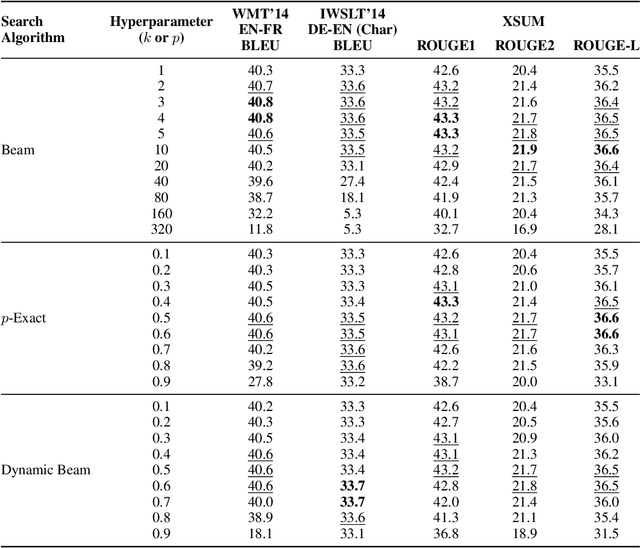
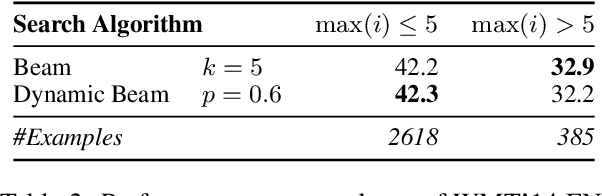
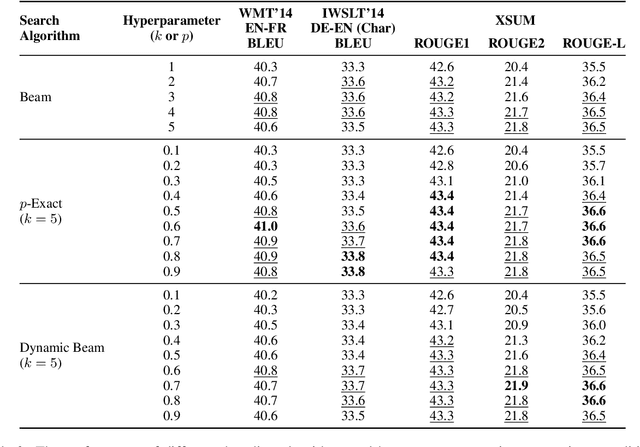
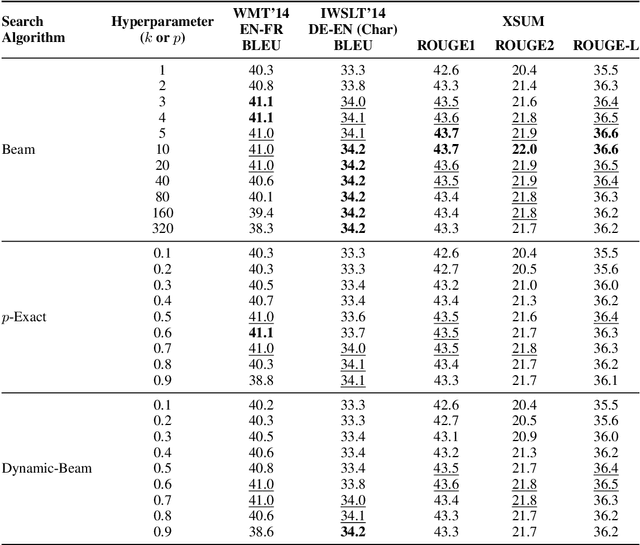
We combine beam search with the probabilistic pruning technique of nucleus sampling to create two deterministic nucleus search algorithms for natural language generation. The first algorithm, p-exact search, locally prunes the next-token distribution and performs an exact search over the remaining space. The second algorithm, dynamic beam search, shrinks and expands the beam size according to the entropy of the candidate's probability distribution. Despite the probabilistic intuition behind nucleus search, experiments on machine translation and summarization benchmarks show that both algorithms reach the same performance levels as standard beam search.