 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoenix-VL 1.5 Medium Technical Report
May 11, 2026We introduce Phoenix-VL 1.5 Medium, a 123B-parameter natively multimodal and multilingual foundation model, adapted to regional languages and the Singapore context. Developed as a sovereign AI asset, it demonstrates that deep domain adaptation can be achieved with minimal degradation to broad-spectrum intelligence and alignment. Continued pretraining was performed on Mistral Medium 3.1 using a localized 1-trillion tokens multimodal corpus, followed by a 250-billion tokens long-context extension phase. Subsequent post-training incorporated a novel human-annotated Singapore multimodal dataset and curated textual corpus on Singapore culture, knowledge, and legislation, totaling 22-billion tokens. An additional 5 billion tokens of model alignment was performed through Online Direct Preference Optimization. Phoenix-VL 1.5 Medium achieves state-of-the-art performance for its size on Singapore multimodal, legal, and government policy benchmarks while remaining globally competitive on general multimodal intelligence, multilingual, and STEM benchmarks. We also introduce a novel evaluation suite encompassing localized knowledge benchmarks and an institutionally aligned model behavior and safety framework. We report the data curation principles, training methodology, and highlight benchmark and inference performance.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning
May 30, 2025



We explore a method for improving the performance of large language models through self-reflection and reinforcement learning. By incentivizing the model to generate better self-reflections when it answers incorrectly, we demonstrate that a model's ability to solve complex, verifiable tasks can be enhanced even when generating synthetic data is infeasible and only binary feedback is available. Our framework operates in two stages: first, upon failing a given task, the model generates a self-reflective commentary analyzing its previous attempt; second, the model is given another attempt at the task with the self-reflection in context. If the subsequent attempt succeeds, the tokens generated during the self-reflection phase are rewarded. Our experimental results show substantial performance gains across a variety of model architectures, as high as 34.7% improvement at math equation writing and 18.1% improvement at function calling. Notably, smaller fine-tuned models (1.5 billion to 7 billion parameters) outperform models in the same family that are 10 times larger. Our novel paradigm is thus an exciting pathway to more useful and reliable language models that can self-improve on challenging tasks with limited external feedback.
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
Aug 27, 2024


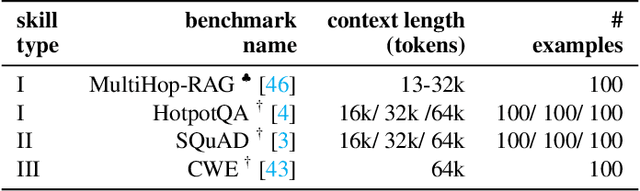
In this paper, we introduce Writing in the Margins (WiM), a new inference pattern for Large Language Models designed to optimize the handling of long input sequences in retrieval-oriented tasks. This approach leverages the chunked prefill of the key-value cache to perform segment-wise inference, which enables efficient processing of extensive contexts along with the generation and classification of intermediate information ("margins") that guide the model towards specific tasks. This method increases computational overhead marginally while significantly enhancing the performance of off-the-shelf models without the need for fine-tuning. Specifically, we observe that WiM provides an average enhancement of 7.5% in accuracy for reasoning skills (HotpotQA, MultiHop-RAG) and more than a 30.0% increase in the F1-score for aggregation tasks (CWE). Additionally, we show how the proposed pattern fits into an interactive retrieval design that provides end-users with ongoing updates about the progress of context processing, and pinpoints the integration of relevant information into the final response. We release our implementation of WiM using Hugging Face Transformers library at https://github.com/writer/writing-in-the-margins.