 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecalling Too Well: Sycophancy Evaluation and Mitigation in Memory-Augmented Models
Jun 09, 2026Persistent memory systems promise to make LLMs more helpful by storing user beliefs over time. We show they also make models less correct by systematically amplifying sycophancy, wherein models prioritize agreement with users over accuracy. We conduct the first systematic evaluation of this effect, introducing MIST: a benchmark of synthetically generated multi-turn conversations where users express plausible misconceptions in scientific, medical, and moral reasoning domains. Testing across three state-of-the-art memory systems and five model families reveals that memory amplifies sycophantic behavior across all conditions, with up to 25x higher sycophancy rates than in-context baselines. Error analyses suggest memory extraction as the primary culprit: lossy compression into discrete snippets encodes user misconceptions while discarding corrective context. Based on these results, we propose two lightweight mitigations that substantially reduce sycophancy while matching or exceeding memory systems at factual recall.
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
Aug 27, 2024


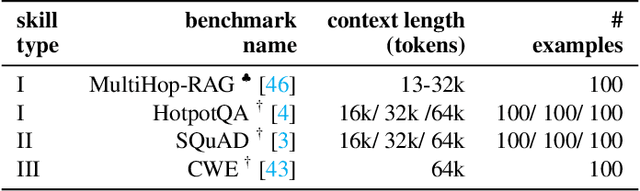
In this paper, we introduce Writing in the Margins (WiM), a new inference pattern for Large Language Models designed to optimize the handling of long input sequences in retrieval-oriented tasks. This approach leverages the chunked prefill of the key-value cache to perform segment-wise inference, which enables efficient processing of extensive contexts along with the generation and classification of intermediate information ("margins") that guide the model towards specific tasks. This method increases computational overhead marginally while significantly enhancing the performance of off-the-shelf models without the need for fine-tuning. Specifically, we observe that WiM provides an average enhancement of 7.5% in accuracy for reasoning skills (HotpotQA, MultiHop-RAG) and more than a 30.0% increase in the F1-score for aggregation tasks (CWE). Additionally, we show how the proposed pattern fits into an interactive retrieval design that provides end-users with ongoing updates about the progress of context processing, and pinpoints the integration of relevant information into the final response. We release our implementation of WiM using Hugging Face Transformers library at https://github.com/writer/writing-in-the-margins.