 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data
Mar 08, 2021

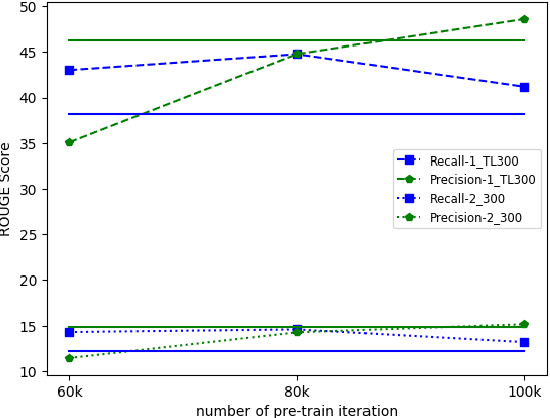
Interleaved texts, where posts belonging to different threads occur in a sequence, commonly occur in online chat posts, so that it can be time-consuming to quickly obtain an overview of the discussions. Existing systems first disentangle the posts by threads and then extract summaries from those threads. A major issue with such systems is error propagation from the disentanglement component. While end-to-end trainable summarization system could obviate explicit disentanglement, such systems require a large amount of labeled data. To address this, we propose to pretrain an end-to-end trainable hierarchical encoder-decoder system using synthetic interleaved texts. We show that by fine-tuning on a real-world meeting dataset (AMI), such a system out-performs a traditional two-step system by 22%. We also compare against transformer models and observed that pretraining with synthetic data both the encoder and decoder outperforms the BertSumExtAbs transformer model which pretrains only the encoder on a large dataset.
Inexpensive Domain Adaptation of Pretrained Language Models: Case Studies on Biomedical NER and Covid-19 QA
Apr 30, 2020
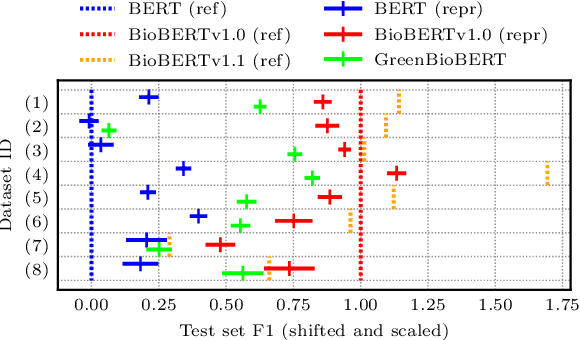
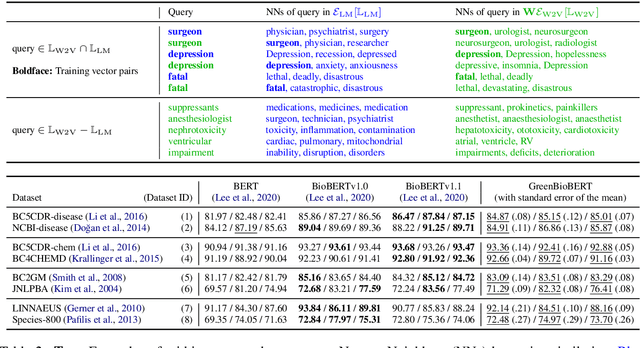

Domain adaptation of Pretrained Language Models (PTLMs) is typically achieved by unsupervised pretraining on target-domain text. While successful, this approach is expensive in terms of hardware, runtime and CO_2 emissions. Here, we propose a cheaper alternative: We train Word2Vec on target-domain text and align the resulting word vectors with the wordpiece vectors of a general-domain PTLM. We evaluate on eight biomedical Named Entity Recognition (NER) tasks and compare against the recently proposed BioBERT model. We cover over 50% of the BioBERT-BERT F1 delta, at 5% of BioBERT's CO_2 footprint and 2% of its cloud compute cost. We also show how to quickly adapt an existing general-domain Question Answering (QA) model to an emerging domain: the Covid-19 pandemic.
AAAI FSS-19: Human-Centered AI: Trustworthiness of AI Models and Data Proceedings
Jan 15, 2020To facilitate the widespread acceptance of AI systems guiding decision-making in real-world applications, it is key that solutions comprise trustworthy, integrated human-AI systems. Not only in safety-critical applications such as autonomous driving or medicine, but also in dynamic open world systems in industry and government it is crucial for predictive models to be uncertainty-aware and yield trustworthy predictions. Another key requirement for deployment of AI at enterprise scale is to realize the importance of integrating human-centered design into AI systems such that humans are able to use systems effectively, understand results and output, and explain findings to oversight committees. While the focus of this symposium was on AI systems to improve data quality and technical robustness and safety, we welcomed submissions from broadly defined areas also discussing approaches addressing requirements such as explainable models, human trust and ethical aspects of AI.
Sentence Meta-Embeddings for Unsupervised Semantic Textual Similarity
Nov 09, 2019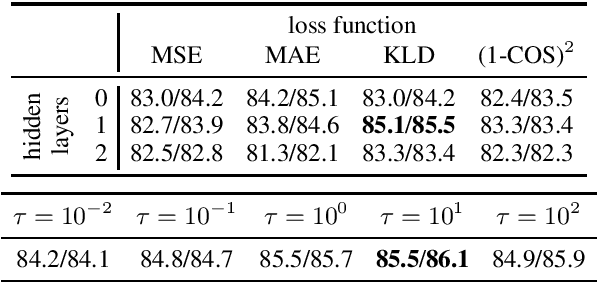
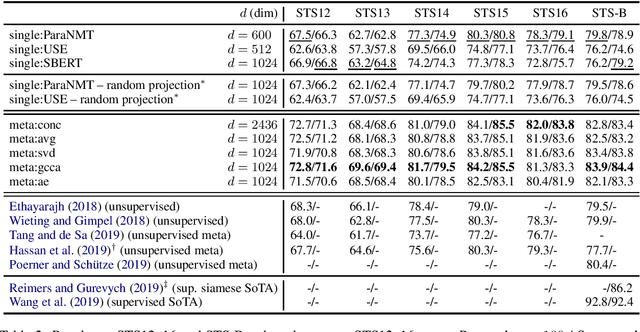

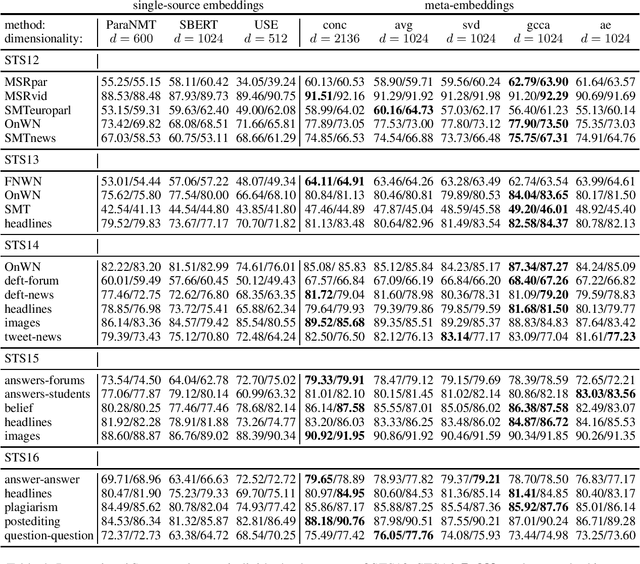
We address the task of unsupervised Semantic Textual Similarity (STS) by ensembling diverse pre-trained sentence encoders into sentence meta-embeddings. We apply and extend different meta-embedding methods from the word embedding literature, including dimensionality reduction (Yin and Sch\"utze, 2016), generalized Canonical Correlation Analysis (Rastogi et al., 2015) and cross-view autoencoders (Bollegala and Bao, 2018). We set a new unsupervised State of The Art (SoTA) on the STS Benchmark and on the STS12-STS16 datasets, with gains of between 3.7% and 6.4% Pearson's r over single-source systems.
BERT is Not a Knowledge Base : Factual Knowledge vs. Name-Based Reasoning in Unsupervised QA
Nov 09, 2019
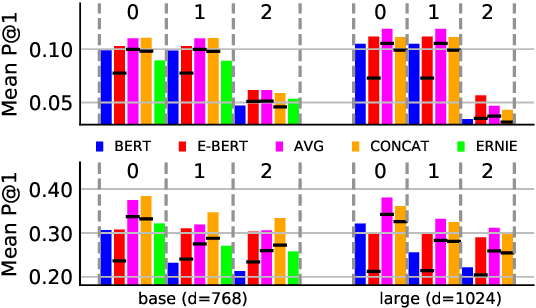
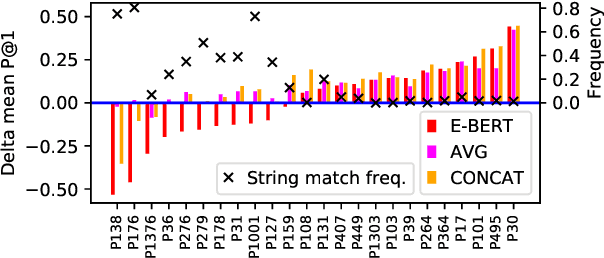
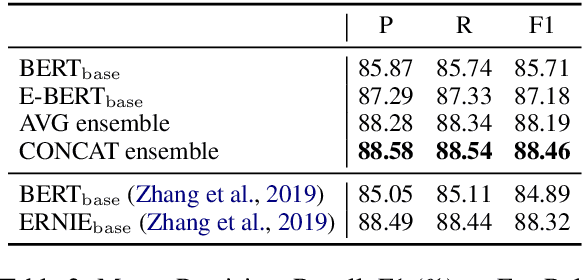
The BERT language model (LM) (Devlin et al., 2019) is surprisingly good at answering cloze-style questions about relational facts. Petroni et al. (2019) take this as evidence that BERT memorizes factual knowledge during pre-training. We take issue with this interpretation and argue that the performance of BERT is partly due to reasoning about (the surface form of) entity names, e.g., guessing that a person with an Italian-sounding name speaks Italian. More specifically, we show that BERT's precision drops dramatically when we filter certain easy-to-guess facts. As a remedy, we propose E-BERT, an extension of BERT that replaces entity mentions with symbolic entity embeddings. E-BERT outperforms both BERT and ERNIE (Zhang et al., 2019) on hard-to-guess queries. We take this as evidence that E-BERT is richer in factual knowledge, and we show two ways of ensembling BERT and E-BERT.
Generating Multi-Sentence Abstractive Summaries of Interleaved Texts
Jun 05, 2019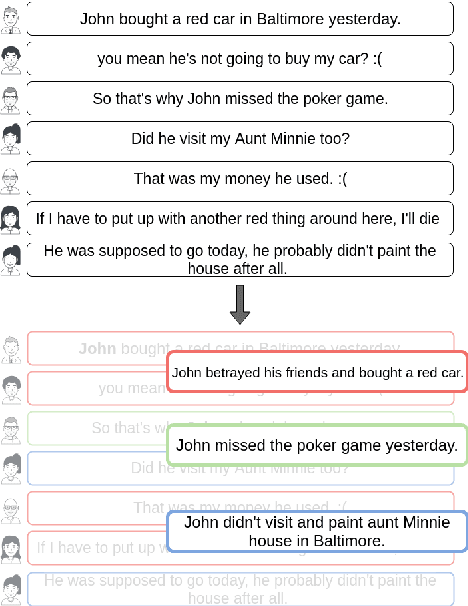

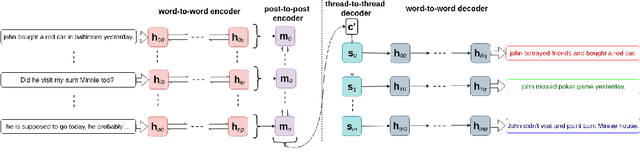
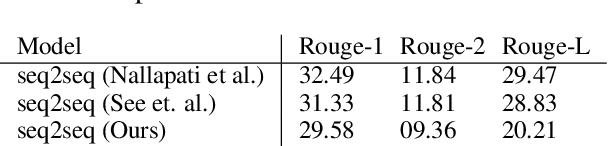
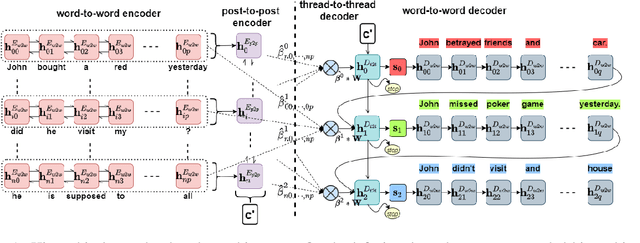
In multi-participant postings, as in online chat conversations, several conversations or topic threads may take place concurrently. This leads to difficulties for readers reviewing the postings in not only following discussions but also in quickly identifying their essence. A two-step process, disentanglement of interleaved posts followed by summarization of each thread, addresses the issue, but disentanglement errors are propagated to the summarization step, degrading the overall performance. To address this, we propose an end-to-end trainable encoder-decoder network for summarizing interleaved posts. The interleaved posts are encoded hierarchically, i.e., word-to-word (words in a post) followed by post-to-post (posts in a channel). The decoder also generates summaries hierarchically, thread-to-thread (generate thread representations) followed by word-to-word (i.e., generate summary words). Additionally, we propose a hierarchical attention mechanism for interleaved text. Overall, our end-to-end trainable hierarchical framework enhances performance over a sequence to sequence framework by 8% on a synthetic interleaved texts dataset.
News Article Teaser Tweets and How to Generate Them
Jul 30, 2018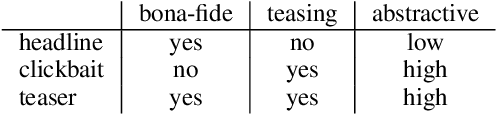

We define the task of teaser generation and provide an evaluation benchmark and baseline systems for it. A teaser is a short reading suggestion for an article that is illustrative and includes curiosity-arousing elements to entice potential readers to read the news item. Teasers are one of the main vehicles for transmitting news to social media users. We compile a novel dataset of teasers by systematically accumulating tweets and selecting ones that conform to the teaser definition. We compare a number of neural abstractive architectures on the task of teaser generation and the overall best performing system is See et al.(2017)'s seq2seq with pointer network.