 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Scale Open-Source Image and Video Dataset for Robust Wildfire Detection and Classification
Jun 08, 2026Wildfire detection and monitoring are critical for mitigating fire spread and reducing environmental and infrastructural damage. In this work, we introduce GWFP (Global Wildfire Prevention Dataset), a large-scale, open-source dataset of wildfire images and videos designed to support early fire and smoke detection research. GWFP contains geographically diverse wildfire scenes, including flames, smoke, Waterdog/Fog environmental conditions, Near Infrared (NIR) imagery, Ember, and challenging negative samples collected from real-world scenarios worldwide. To evaluate dataset robustness and cross-domain generalization, we benchmark multiple convolutional and transformer-based architectures across both in-domain and cross-dataset settings. Additionally, we explore lightweight frequency--spatial feature interaction using Hadamard-enhanced residual connections (HTE-ResNet) to analyze representation robustness under domain-shift conditions. Experimental results demonstrate strong cross-dataset generalization and practical utility for real-world wildfire monitoring applications. The dataset and source code will be publicly released upon acceptance.
Refining 3D Human Texture Estimation from a Single Image
Mar 06, 2023



Estimating 3D human texture from a single image is essential in graphics and vision. It requires learning a mapping function from input images of humans with diverse poses into the parametric (UV) space and reasonably hallucinating invisible parts. To achieve a high-quality 3D human texture estimation, we propose a framework that adaptively samples the input by a deformable convolution where offsets are learned via a deep neural network. Additionally, we describe a novel cycle consistency loss that improves view generalization. We further propose to train our framework with an uncertainty-based pixel-level image reconstruction loss, which enhances color fidelity. We compare our method against the state-of-the-art approaches and show significant qualitative and quantitative improvements.
Mobile Multi-View Object Image Search
Apr 30, 2018

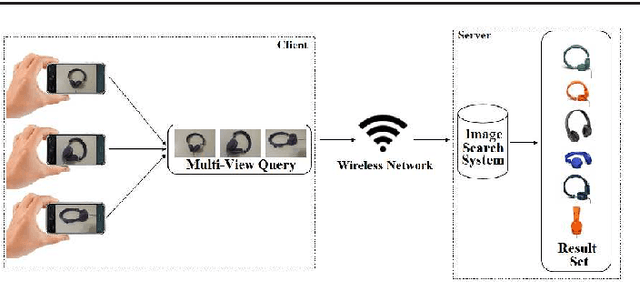

High user interaction capability of mobile devices can help improve the accuracy of mobile visual search systems. At query time, it is possible to capture multiple views of an object from different viewing angles and at different scales with the mobile device camera to obtain richer information about the object compared to a single view and hence return more accurate results. Motivated by this, we developed a mobile multi-view object image search system, using a client-server architecture. Multi-view images of objects acquired by the mobile clients are processed and local features are sent to the server, which combines the query image representations with early/late fusion methods based on bag-of-visual-words and sends back the query results. We performed a comprehensive analysis of early and late fusion approaches using various similarity functions, on an existing single view and a new multi-view object image database. The experimental results show that multi-view search provides significantly better retrieval accuracy compared to single view search.