 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning and Distant Supervision for Multilingual Transformer Models: A Study on African Languages
Oct 07, 2020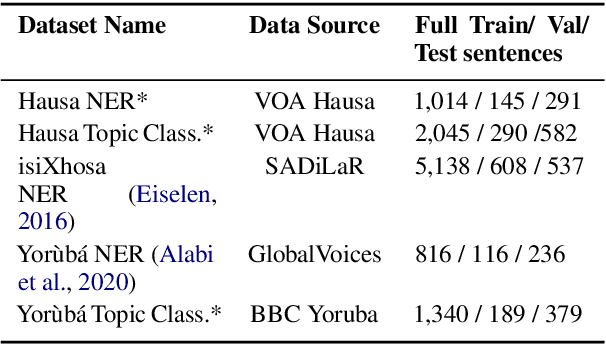
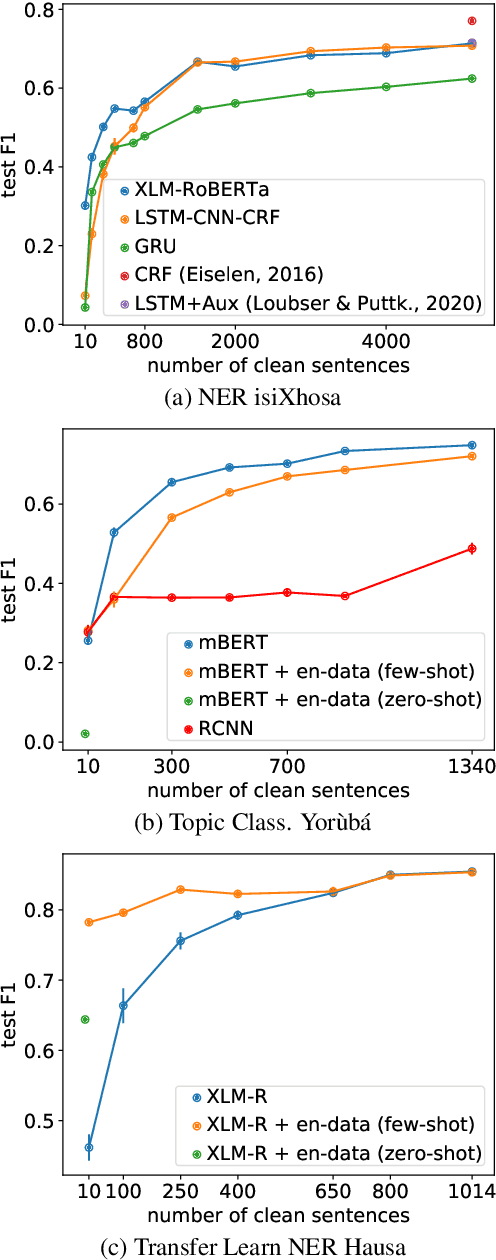
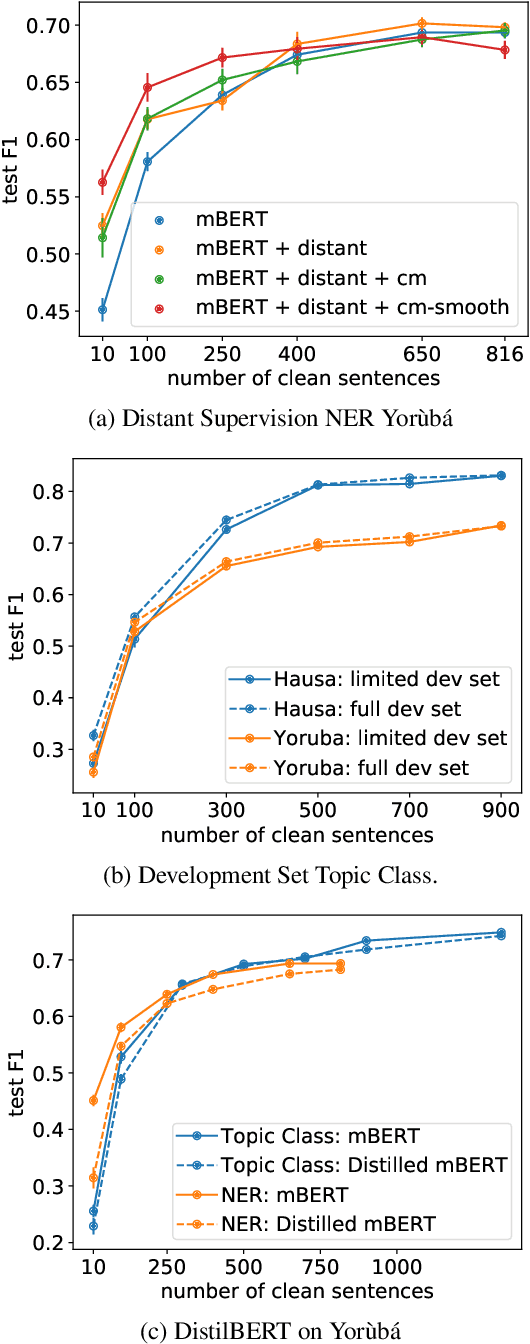
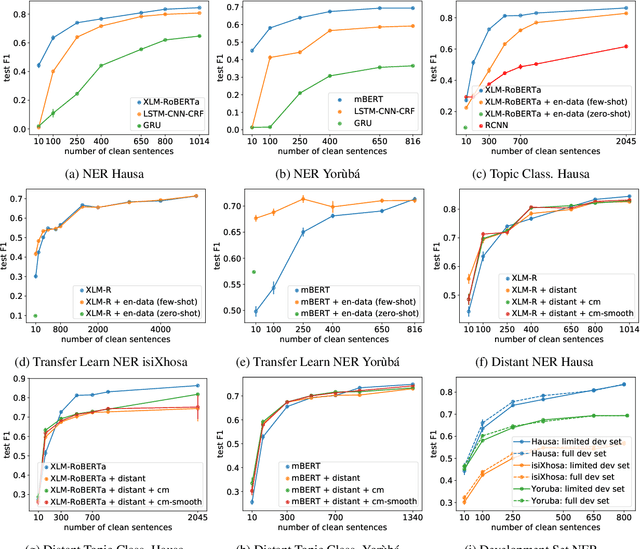
Multilingual transformer models like mBERT and XLM-RoBERTa have obtained great improvements for many NLP tasks on a variety of languages. However, recent works also showed that results from high-resource languages could not be easily transferred to realistic, low-resource scenarios. In this work, we study trends in performance for different amounts of available resources for the three African languages Hausa, isiXhosa and Yor\`ub\'a on both NER and topic classification. We show that in combination with transfer learning or distant supervision, these models can achieve with as little as 10 or 100 labeled sentences the same performance as baselines with much more supervised training data. However, we also find settings where this does not hold. Our discussions and additional experiments on assumptions such as time and hardware restrictions highlight challenges and opportunities in low-resource learning.