 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing the Loose Brake: Exponential-Tailed Stopping Time in Best Arm Identification
Nov 04, 2024

The best arm identification problem requires identifying the best alternative (i.e., arm) in active experimentation using the smallest number of experiments (i.e., arm pulls), which is crucial for cost-efficient and timely decision-making processes. In the fixed confidence setting, an algorithm must stop data-dependently and return the estimated best arm with a correctness guarantee. Since this stopping time is random, we desire its distribution to have light tails. Unfortunately, many existing studies focus on high probability or in expectation bounds on the stopping time, which allow heavy tails and, for high probability bounds, even not stopping at all. We first prove that this never-stopping event can indeed happen for some popular algorithms. Motivated by this, we propose algorithms that provably enjoy an exponential-tailed stopping time, which improves upon the polynomial tail bound reported by Kalyanakrishnan et al. (2012). The first algorithm is based on a fixed budget algorithm called Sequential Halving along with a doubling trick. The second algorithm is a meta algorithm that takes in any fixed confidence algorithm with a high probability stopping guarantee and turns it into one that enjoys an exponential-tailed stopping time. Our results imply that there is much more to be desired for contemporary fixed confidence algorithms.
HAVER: Instance-Dependent Error Bounds for Maximum Mean Estimation and Applications to Q-Learning
Nov 01, 2024We study the problem of estimating the \emph{value} of the largest mean among $K$ distributions via samples from them (rather than estimating \emph{which} distribution has the largest mean), which arises from various machine learning tasks including Q-learning and Monte Carlo tree search. While there have been a few proposed algorithms, their performance analyses have been limited to their biases rather than a precise error metric. In this paper, we propose a novel algorithm called HAVER (Head AVERaging) and analyze its mean squared error. Our analysis reveals that HAVER has a compelling performance in two respects. First, HAVER estimates the maximum mean as well as the oracle who knows the identity of the best distribution and reports its sample mean. Second, perhaps surprisingly, HAVER exhibits even better rates than this oracle when there are many distributions near the best one. Both of these improvements are the first of their kind in the literature, and we also prove that the naive algorithm that reports the largest empirical mean does not achieve these bounds. Finally, we confirm our theoretical findings via numerical experiments including bandits and Q-learning scenarios where HAVER outperforms baseline methods.
Event Detection: Gate Diversity and Syntactic Importance Scoresfor Graph Convolution Neural Networks
Oct 27, 2020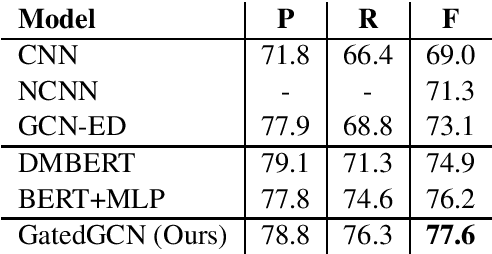
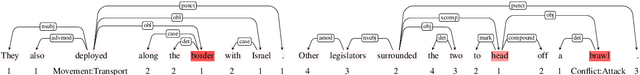
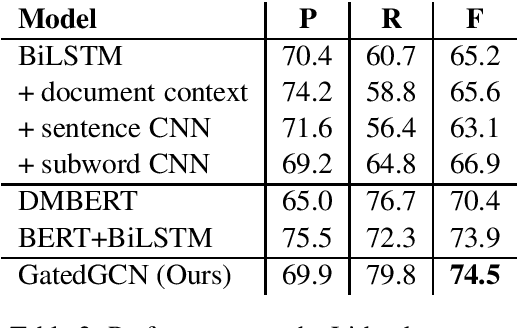
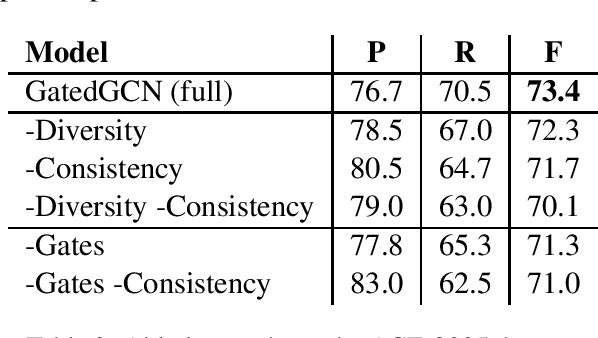
Recent studies on event detection (ED) haveshown that the syntactic dependency graph canbe employed in graph convolution neural net-works (GCN) to achieve state-of-the-art per-formance. However, the computation of thehidden vectors in such graph-based models isagnostic to the trigger candidate words, po-tentially leaving irrelevant information for thetrigger candidate for event prediction. In addi-tion, the current models for ED fail to exploitthe overall contextual importance scores of thewords, which can be obtained via the depen-dency tree, to boost the performance. In thisstudy, we propose a novel gating mechanismto filter noisy information in the hidden vec-tors of the GCN models for ED based on theinformation from the trigger candidate. Wealso introduce novel mechanisms to achievethe contextual diversity for the gates and theimportance score consistency for the graphsand models in ED. The experiments show thatthe proposed model achieves state-of-the-artperformance on two ED datasets
Graph Transformer Networks with Syntactic and Semantic Structures for Event Argument Extraction
Oct 26, 2020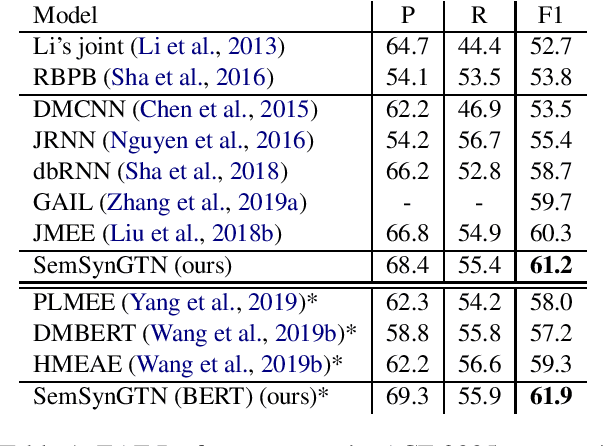
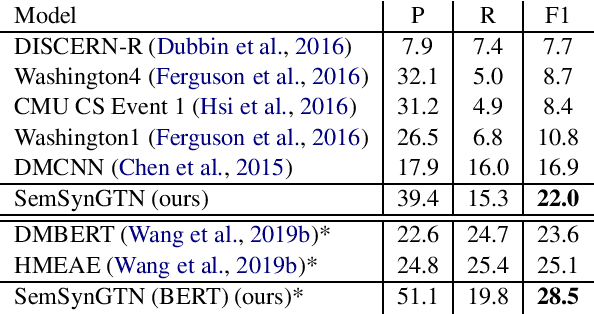
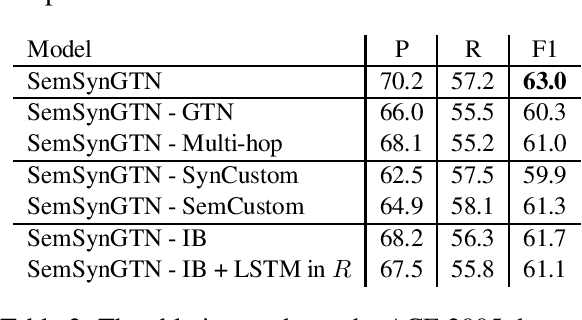
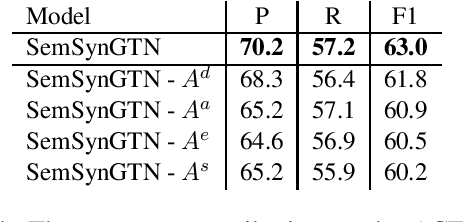
The goal of Event Argument Extraction (EAE) is to find the role of each entity mention for a given event trigger word. It has been shown in the previous works that the syntactic structures of the sentences are helpful for the deep learning models for EAE. However, a major problem in such prior works is that they fail to exploit the semantic structures of the sentences to induce effective representations for EAE. Consequently, in this work, we propose a novel model for EAE that exploits both syntactic and semantic structures of the sentences with the Graph Transformer Networks (GTNs) to learn more effective sentence structures for EAE. In addition, we introduce a novel inductive bias based on information bottleneck to improve generalization of the EAE models. Extensive experiments are performed to demonstrate the benefits of the proposed model, leading to state-of-the-art performance for EAE on standard datasets.
On the Effectiveness of the Pooling Methods for Biomedical Relation Extraction with Deep Learning
Nov 04, 2019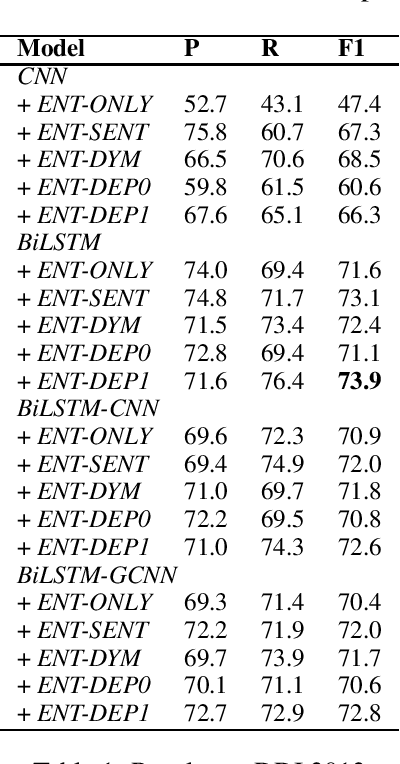
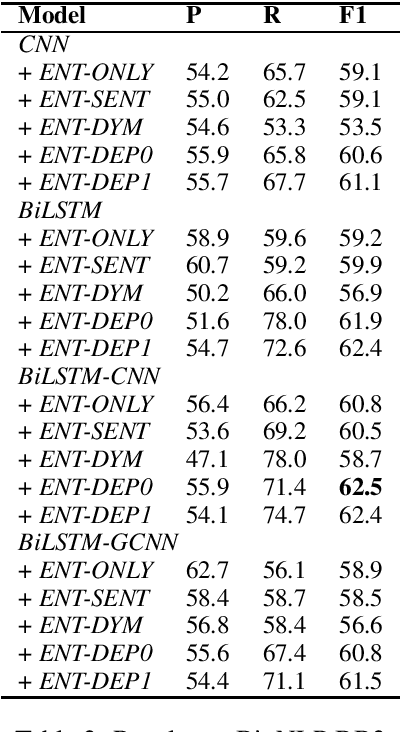
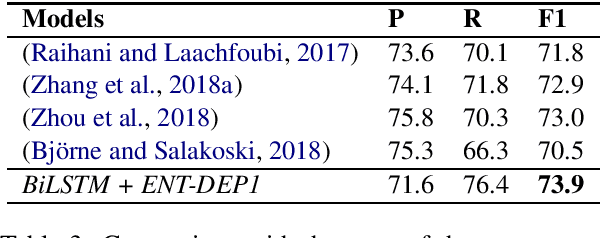
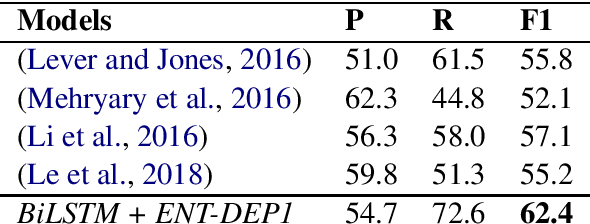
Deep learning models have achieved state-of-the-art performances on many relation extraction datasets. A common element in these deep learning models involves the pooling mechanisms where a sequence of hidden vectors is aggregated to generate a single representation vector, serving as the features to perform prediction for RE. Unfortunately, the models in the literature tend to employ different strategies to perform pooling for RE, leading to the challenge to determine the best pooling mechanism for this problem, especially in the biomedical domain. In order to answer this question, in this work, we conduct a comprehensive study to evaluate the effectiveness of different pooling mechanisms for the deep learning models in biomedical RE. The experimental results suggest that dependency-based pooling is the best pooling strategy for RE in the biomedical domain, yielding the state-of-the-art performance on two benchmark datasets for this problem.